Hadoop集群管理基础知识笔记
1.Hadoop集群尽量采用ECC内存,否则可能会出现校验和错误,ECC内存有纠错功能。在磁盘方面,尽管namenode建议采用RAID以保护元数据,但是将RAID用于datanode不会给HDFS带来益处,速度依然比HDFS的JBOD(Just a Bunch Of Disks)配置慢。RAID读写速度受制于最慢的盘片,JBOD的磁盘操作都是独立的。而且JBOD配置的HDFS某一磁盘故障可以直接忽略继续工作,RAID有一个盘片坏了整个阵列都无法工作。
2.对于几十个节点的小集群,在一台master机器上同时运行namenode和资源管理器通常可以接受,只要至少一份namenode的元数据被另存在HDFS中。但是集群大了就应该分离这两个角色在不同机子上。Namenode在内存中保存整个命名空间中所有文件元数据和块元数据,内存需求很大,SecondaryNamenode在大多数时间空闲,但在创建检查点时的内存需求与主namenode差不多。
在分开的机器上运行master的主要理由是为了高可用性。主master故障时备机将接替主机,在HDFS中辅助namenode的检查点功能由备机执行,所以不需要同时运行备机和辅助namenode。
3.在网络拓扑上,一般各机架装配30-40个服务器,共享一个10GB的交换机,各机架的交换机又通过上行链路与一个核心交换机或路由器(10GB或更高)互联,这种架构的特点是同一机架内部节点之间总带宽高于不同机架上节点间的带宽。让Hadoop知道多机架集群中机架和节点位置的关系很重要,可以在MapReduce任务分配到各节点时,倾向于执行机架内的数据传输,因为机架内带宽更大。
Hadoop配置需要通过一个Java接口DNSToSwitchMapping指定节点地址和网络位置间的映射关系。接口定义如下:

resolve()函数的输入函数names描述IP地址列表,返回相应的网络位置字符串列表。net.topology.node.switch.mapping.impl属性实现了DNSToSwitchMapping接口。不过一般情况只需使用默认的ScriptBasedMapping实现即可,它运行用户定义的脚本描述映射关系,脚本的存放路径由属性net.topology.script.file.name控制。脚本接受一系列输入参数,描述带映射的主机名称或IP地址,再将相应的网络位置以空格分开,输出到实际输出。
4.最好创建特定的Unix账号以区分各Hadoop进程,及区分同一机器上其余服务。HDFS、MapReduce和YARN服务通常作为独立的用户运行,分别命名为hdfs、mapred和yarn,同属于一个hadoop组。可以将Hadoop安装在/usr/local或者/opt目录下,最好不要装在/home目录下。此外还需将Hadoop文件拥有者改为hadoop用户和组:
sudo chown –R /opt/hadoop-x.y.zHadoop控制脚本(不是守护进程)依赖SSH执行整个集群的操作。为了支持无缝式工作,需要允许来自集群内机器的hdfs用户和yarn用户能够无密码登陆,需要以hdfs用户身份设置一次,以yarn用户身份一次设置以下命令:
ssh-keygen –t rsa –f ~/.ssh/id_rsa私钥放在由-f参数指定的文件中,存放公钥的文件名称与私钥相同,但以“.pub”作为后缀。接着,需确保公钥存放在用户打算连接的所有机器的~/.ssh/authorized_keys文件中,需要以hdfs用户身份设置一次,以yarn用户身份一次设置以下命令:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys放好公钥后,用ssh命令测试能否连接到其他机器,若可以表明ssh-agent正在运行,再运行ssh-add命令存储口令。
5.在使用HDFS前,需要使用hdfs namenode –format命令对namenode进行初始化。格式化进程将创建一个空的文件系统,该初始化过程不涉及datanode。Hadoop安装目录下的/sbin目录放置了自带的命令行脚本,可以在集群内启动和停止守护进程。namenode和资源管理器节点需要用到安装目录下的etc/hadoop/slaves文件,该文件包含了主机名或IP地址的列表,每行代表一台机子,列举了可以运行datanode和节点管理器(nodemanager)的机器。以hdfs用户运行以下命令启动HDFS守护进程:
start-dfs.sh该脚本实质上做了以下事情:(1)在指定的机器上启动namenode。(2)在etc/hadoop/slaves文件列举的每台机器上启动一个datanode。(3)在指定的机器上启动辅助namenode。
通过以下命令可以从fs.defaultFS属性找到namenode的主机名:
hdfs getconf –namenodes辅助namenode的属性可从hdfs get conf -secondarynamenodes命令查到。
6.以yarn用户在需要运行资源管理器的机器上运行以下命令启动YARN:
start-yarn.sh脚本具体完成以下事情:(1)在当前机器启动一个资源管理器。(2)在etc/hadoop/slaves文件列举的每台机器上启动一个节点管理器。
上述启动各种守护进程的脚本实质上使用了/sbin/hadoop-daemon.sh。mapred用户不需要使用SSH,MapReduce只有一个守护进程,即作业历史服务器,通过mapred用户用以下命令启动:
mr-jobhistory-daemon.sh start historyserver建立并运行Hadoop集群后,需要给不同用户设置用户目录以及访问权限等,可以使用以下命令:
hadoop fs -mkdir /user/username
hadoop fs -chown username:username /user/username可以使用以下命令给特定用户目录设置1TB的容量限制:
hdfs dfsadmin -setSpaceQuota 1t /user/username7.Hadoop的重要配置文件都在安装目录的etc/hadoop目录中。配置文件目录可以放置在安装目录之外便于升级维护,只要启动守护进程时使用--config参数或设置HADOOP_CONF_DIR环境变量。重要配置文件如下所示:
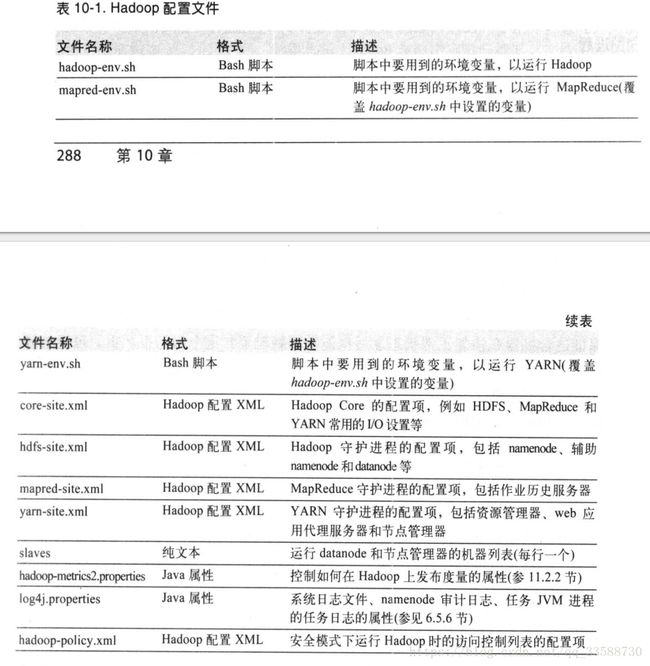
Hadoop没有将所有配置信息放在一个全局位置中,而是集群中每个节点各自保存一部分配置文件,由管理员同步对应配置文件。hadoop-env.sh可以设置环境变量,例如整个集群的JAVA_HOME变量。MapReduce和YARN也有类似配置文件,名为mapred-env.sh和yarn-env.sh,文件中的变量和组件相关,而且hadoop-env.sh中的全局设置值会被这两个文件自己的设置覆盖。
默认情况下,各守护进程被分配1000MB内存,由hadoop-env.sh文件的HADOOP_HEAPSIZE参数控制。也可以只为某个守护进程修改堆大小,如在yarn-env.sh中设置YARN_RESOURCEMANAGER_HEAPSIZE覆盖资源管理器的堆大小。对于namenode来说,1000MB内存的默认设置通常足够管理数百万个文件,但根据经验,保守估计每一百万个数据块就需要分配1000MB内存空间。hadoop-env.sh文件的HADOOP_NAMENODE_OPTS属性包含一个JVM选项以设定内存大小,可以传递例如-Xmx2000m参数表示为namenode分配2000MB内存。由于辅助namenode的内存需求量与主namenode差不多,因此也同时需要对secondarynamenode做相同更改(HADOOP_SECONDARYNAMENODE_OPTS变量)。
默认系统日志文件放在$HADOOP_HOME/logs目录中,也可以改变hadoop-env.sh文件中的HADOOP_LOG_DIR变量来修改存放目录。在实际商用中建议修改默认设置,使之独立于Hadoop安装目录,即使Hadoop升级后安装路径发生变化,也不会影响日志的位置,通常可以放在/var/log/hadoop目录中。具体方法是在hadoop-env.sh中加入一行:
export HADOOP_LOG_DIR=/var/log/hadoop8.运行在各机器上的Hadoop守护进程会产生两类日志文件。(1)第一类日志文件以.log为后缀,是通过log4j记录的,大部分应用程序日志都写到这种日志文件中,故障诊断首要步骤就是检查这样的文件。log4j配置采用日常滚动文件追加方式(daily rolling file appender)来循环管理日志文件,系统不自动删除过期日志,而是等用户定期删除或存档。(2)第二类日志文件后缀为.out,记录标准输出和标准错误日志,因为log4j已经记录大部分日志,这种文件只有少量纪录或空记录。重启守护进程时,系统会创建一个新文件来记录此类日志。系统仅保留最新的5个日志文件,旧的日志会附加一个介于1和5的数字后缀,5为最旧的文件,如下所示:
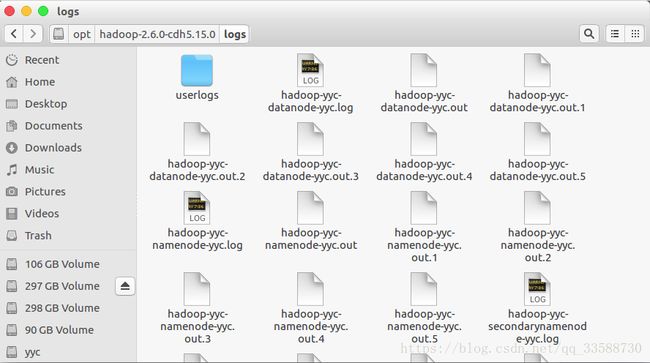
日志文件的名称包含运行守护进程的用户名称、守护进程名称和本地主机名等信息。用户名称部分对应hadoop-env.sh中的HADOOP_IDENT_STRING变量。
9.SSH设置中,StrictHostKeyChecking设置为no会自动将新主机键加到已知主机文件中,默认值是ask,提示用户确认是否已验证“键指纹”(key fingerprint),默认设置不适合大型集群环境。hadoop-env.sh中的HADOOP_SSH_OPTS变量能向SSH传递更多参数。
10.对于真实工作集群中非常关键的一些属性在*-site.xml文件中。对于正在运行的守护进程,要知道实际配置可以在浏览器中访问该进程的/conf页面,例如http://
运行HDFS需要有一台机器指定为namenode,core-site.xml中的fs.defaultFS设置文件系统或HDFS的URI,其主机名是主机名称或IP地址,端口为namenode监听RPC的端口,默认端口为8020。dfs.namenode.name.dir属性指定一系列目录来供namenode存储备份永久性的文件系统元数据(编辑日志和文件系统映像),这样可以将namenode元数据写到一两个本地磁盘和一个远程磁盘中,这样即使本地磁盘故障,甚至整个namenode故障,都可以恢复元数据文件并重构新的namenode,而secondarynamenode只是定期保存namenode的检查点,不一定来得及备份namenode最新数据。
dfs.datanode.data.dir属性设定datanode存储数据块的目录列表,循环地在各个目录中写入数据。因此为了提高性能,最好分别为各个本地磁盘指定一个存储目录,这样数据块跨磁盘分布,针对不同数据块的读操作可以并发执行,提升读取性能。为了充分发挥性能,可以使用noatime参数挂载磁盘。该选项意味着执行读操作时,读取文件的最近访问时间并不刷新,从而显著提升性能。HDFS的关键配置属性如下所示:

默认情况下,HDFS存储目录放在Hadoop临时目录下,该目录通过hadoop.tmp.dir设置,默认值是/tmp/hadoop-username,如果设置别的值可以使得即使清除了系统的临时目录,数据也不会丢失。
11.运行YARN需要指定一台机器作为资源管理器,yarn.resourcemanager.hostname属性设置用于运行resourcemanager的主机名或IP地址。执行MapReduce作业过程中产生的中间数据和工作文件被写到临时本地文件中,包括map任务的输出数据。数据量可能很大,需要保证YARN本地临时存储空间(由yarn.nodemanager.local-dirs设置)足够大。YARN没有MapReduce1中的Tasktracker,它依赖shuffle将map任务输出传给reduce任务,因此需要将yarn-site.xml中的yarn.nodemanager.aux-services属性设置为mapreduce_shuffle来启用MapReduce及shuffle功能。YARN的关键配置属性如下所示:

12.在YARN中,允许为一个任务请求任意在限制范围内的规模的内存,因此一个节点上运行的任务数量取决于这些任务对内存的总需求量。每个Hadoop守护进程默认使用1000M内存,因此需要2000MB内存运行1个datanode和一个节点管理器。为机器上运行的其他进程留出足够内存后,通过yarn.nodemanager.resource.memory-mb属性设置单位为MB的内存总分配量,剩余内存可用于节点管理器的container,默认为8192MB,在大部分场景中太低。
为单个作业设置内存选项有两种方法:(1)控制YARN分配的容器大小。(2)控制容器中运行的Java进程堆大小。需注意的是,MapReduce的内存控制可以由客户端在作业配置中设置,YARN设置是集群层面的,客户端不能修改。容器大小由属性mapreduce.map/reduce.memory.mb决定,默认值都为1024MB。Java进程的堆大小由mapred.child.java.opts设置,默认200MB,也可以单独为map和reduce任务设置Java选项,如下所示:
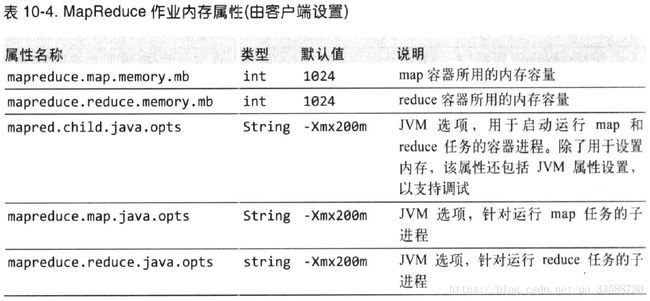
例如,mapred.child.java.opts设置为-Xmx800m,mapreduce.map.memory.mb为默认值,当map任务启动时,节点管理器会为该任务分配一个1024MB的容器,该任务运行期间nodemanager内存池会相应降低1024MB,并启动配置为最大堆为800MB的任务JVM。然而,JVM进程的实际内存开销会比该堆大小要大,JVM进程机器创建的子进程如Streaming使用的物理内存必须不超出分配的容器内存大小(该例子为1024MB)。若某容器使用内存超出分配量,会被节点管理器终止并标记为失败。
而容器的虚拟内存使用量如果超出预定系数和所分配物理内存的乘积,节点管理器也会终止进程,该系数由yarn.nodemanager.vmem-pmem-ratio设置,默认值2.1。YARN调度器默认情况下最小内存分配量为1024MB(由yarn.scheduler.minimum-allocation-mb设置),默认最大内存分配量为8192MB,属性为前者minimum处改为maximum即可。
13.属性yarn.nodemanager.resource.cpuvcores设置节点管理器分配给容器的CPU核数量。应该设置为CPU总核数减去机器上运行的其他守护进程(datanode、nodemanager等)占用的核数(每个进程占用1个核)。设置属性mapreduce.map/reduce.cpu.vcores属性,可以使MapReduce作业能控制分配给map和reduce容器的核数量,两者默认值均为1。
Hadoop守护进程一般同时运行RPC和HTTP两个服务器,RPC服务器支持守护进程间的通信,HTTP服务器提供与用户交互的web页面,需要为各个服务器配置网络地址和端口号。这些设置一方面决定了服务器将绑定的网络接口,另一方面客户端或集群中其他机器使用它们连接服务器,例如节点管理器使用yarn.resourcemanager.resource.tracker.address属性确定资源管理器的地址。
用户经常希望服务器可以同时绑定多个网络接口,将网络地址设置为0.0.0.0可达到该目的,但该地址无法被客户端或集群中其他机器解析。解决方法是将yarn.resourcemanager.hostname设为主机名或IP地址,yarn.resourcemanager.bind-host设为0.0.0.0,可确保资源管理器能与机器上所有网络接口绑定,且同时能为节点管理器和客户端提供可解析的地址。
14.属性dfs.hosts记录允许作为datanode加入集群的机器列表,yarn.resourcenamanger.nodes.include-path记录允许作为节点管理器加入集群的机器列表。dfs.host.exclude和yarn.resourcemanager.nodes.exclude-path所指定的文件包含待解除的机器列表。
Hadoop使用一个4KB的缓冲区辅助I/O操作。对于现代硬件来说容量过于保守,增大缓冲区容量会显著提高性能,例如128KB更常用。可以在core-site.xml中的io.file.buffer.size属性设置缓冲区大小,以字节为单位。
默认情况下,HDFS块大小为128MB,但很多集群将块大小设置成两倍或更大以降低namenode的内存压力,并向mapper传输更多数据。可以通过hdfs-site.xml中的dfs.blocksize设置块的大小,以字节为单位。默认情况下datanode能使用存储目录上所有的闲置空间。如果想要把部分空间留给其他非HDFS应用程序,需要设置dfs.datanode.du.reserved属性指定待保留的空间大小,也以字节为单位。
Hadoop也支持回收站功能,被删除文件可以不被真正删除,仅转移到回收站的一个特定文件夹中。回收站文件被永久删除之前仍会保留一段时间,该时间间隔由core-site.xml中的fs.trash.interval属性以分钟为单位设置,默认情况该值为0,即不启用回收站。这种回收站功能只有由系统shell直接删除的文件才会被放到回收站,用程序删除的一般会直接删除,除非构造一个Trash类的实例,调用moveToTrash()方法把指定路径文件移到回收站中。如果成功返回true,否则如果回收站功能未启用,或该文件已在回收站中,会返回false。
当回收站功能启用时,每个用户都有独立回收站目录,即/home目录下的.Trash目录,恢复文件只需要在.Trash的子目录中找到文件并移出该文件夹即可。只有HDFS会自动删除回收站中的文件,其他文件系统没有该功能,需要利用以下命令手动定期删除已在回收站中超过最小时限的所有文件:
hadoop fs -expungeTrash类的expunge()方法也有相同效果。
15.在默认情况下调度器会一直等待,直到该作业的5%的map任务已经结束才会调用reduce任务。对大型作业来说会降低集群利用率,因为在等待map任务执行完毕的过程中,占用了reduce容器。可以将mapreduce.job.reduce.slowstart.completedmaps的值设置的更大例如0.80(80%),能够提升吞吐率。
从HDFS读取文件时,客户端联系datanode然后数据通过TCP连接发送给客户端,如果正在读取的数据块就在客户端节点上,可以绕过网络直接读取本地磁盘上的数据更有效率,即“短回路本地读”(short-circuit local read),该方式能让HBase等应用执行效率更高。将dfs.client.read.shortcircuit设置为true可启用该功能。该读操作基于Unix套接字实现,在客户端和datanode之间的通信中使用一个本地路径,该本地路径由dfs.domain.socket.path设置,且必须是一条仅由datanode或root用户能创建的路径,例如/var/run/hadoop-hdfs/dn_socket。
16.在安全性方面,Hadoop使用Kerberos(一个成熟开源网络认证协议)实现用户认证,该协议的职责是鉴定登录账号是否就是真的用户,而不是伪造身份的攻击者,而Hadoop本身决定该用户拥有哪些权限。使用Kerberos时一个客户端要经过三个步骤才能获得服务,每个步骤客户端需要和服务器交换报文,如下所示:

(1)认证。客户端向认证服务器发送一条报文,并获取一个含时间戳的凭据授予凭据(Ticket-Granting Ticket,TGT)。
(2)授权。客户端使用TGT向凭据授予服务器(Ticket-Granting Server,TGS)请求一个服务凭据。
(3)服务请求。客户端向对应服务器出示服务凭据,以证实自己的合法性,该服务器(namenode或resourcemanager)提供客户端所需服务。
这样认证服务器和凭据授予服务器构成了密钥分配中心(Key Distribution Center,KDC)。客户端系统会代替用户执行这些步骤,但认证步骤需要用户调用kinit命令执行,该过程会提示输入密码,在TGT有效期内(默认10小时,可调整到一周)不需要输入第二次。更好的做法是采用自动认证,在登录操作系统的时候自动执行认证操作,从而只需单次登录Hadoop。如果需要运行一个无人值守的MapReduce作业等用户不希望提示输入密码的场合,可以使用ktutil命令创建一个Kerberos的keytab文件,该文件保存了用户密码并且可以通过-t选项应用于kinit命令。
举个例子,首先将core-site.xml文件中hadoop.security.authentication属性设置为kerberos,启动Kerberos认证(需提前安装配置好并运行一个KDC),该属性默认值为simple,即利用操作系统用户名来决定登陆者身份。其次,同一文件中的hadoop.security.authorization属性设置为true,以启用服务级别的授权,可配置$HADOOP_HOME/etc/hadoop目录下的hadoop-policy.xml文件中的访问控制列表以决定哪些用户和组能够访问哪些Hadoop服务,默认情况下各个服务的访问控制列表都为*,即所有用户能访问所有服务,包括针对MapReduce作业提交的服务,针对namenode通信的服务等。具体在这种安全认证下复制本地文件到HDFS的命令行例子如下:

17.在kinit命令后,后续认证访问由委托令牌完成,避免在一个高负载集群中,HDFS的客户端与namenode和datanode频繁交互给KDC带来巨大压力。委托令牌由服务器创建,在HDFS中为namenode创建,可视为客户端和服务器间共享的一个密文。客户端首次通过RPC访问namenode时,客户端没有委托令牌,因此需要通过Kerberos认证,之后客户端从namenode获得一个委托令牌,在后续RPC调用中,客户端只需出示委托令牌,namenode就能验证令牌真伪(因为是namenode使用密钥创建的)。
在不安全的Hadoop系统中,客户端只需要知道某个HDFS块的块ID即可访问该数据块,在安全机制下客户端需要块访问令牌(block access token)才能访问特定的HDFS块。当客户端向namenode发出元数据请求时,namenode创建相应的块访问令牌返回客户端,客户端使用这个令牌向datanode认证自己的访问权限(因为namenode和datanode之间有心跳同步机制,也会同步令牌密钥)。要访问不同的数据块需要不同的块访问令牌。可以将dfs.block.access.token.enable设置为true开启块访问令牌功能。作业结束时,委托令牌失效。
18.在集群建立好并开始正式工作前,最好运行一下基准评测程序,并且不同时运行其他任务以获得最佳评测效果。如果不指定参数,大多数基准测试程序都会显示具体用法,如下所示:

Hadoop自带一个名为TeraSort的MapReduce程序,该程序对输入进行全排序。全部输入数据集通过shuffle传输,因此对于同时评测HDFS和MapReduce很有用。测评分为三步:生成随机数据、执行排序和验证结果:
(1)首先,使用teragen生成随机数据,它运行一个仅有map任务的作业,可生成指定行数的二进制数据,每一行100字节长,这样使用1000个map任务可生成10TB数据,命令如下(10t为10trillion的意思):
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \
teragen -Dmapreduce.job.maps=1000 10t random-data
(2)接下来运行TeraSort:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \
terasort random-data sorted-data
排序的总执行时间是有用的度量值,可以通过浏览器内访问http://
(3)最后,验证在sorted-data文件中的数据是否已经排好序:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \
teravalidate sorted-data report
该命令运行一个小的MapReduce作业,对排序后数据进行检查,任何错误可从输出文件report/part-r-00000中找到。常用的基准测评程序如下所示:

如果所测集群是该用户第一个集群,且还没有任何作业,Gridmix或SWIM都是推荐的评测方案。
19.运行中的namenode有如下所示的目录结构,各个目录存储着镜像内容,该机制使系统具备一定复原能力,尤其是其中某个目录为NFS时:


VERSION文件是一个Java属性文件,包含正在运行的HDFS版本信息,一般包括如下内容:

layoutVersion是一个负整数,描述HDFS布局的版本,该版本号与Hadoop版本无关,只要布局变更,版本号递减(例如变为-58),此时HDFS也需要更新,否则磁盘依然使用旧版本布局,新版本namenode或datanode会无法正常工作。namespaceID是文件系统命名空间的唯一标识符,是在namenode首次格式化时创建的。clusterID是整个HDFS集群的唯一标识符,用于区分联合HDFS内多个HDFS集群。blockpoolID是数据块池的唯一标识符,池中包含一个namenode管理的命名空间中的所有文件。
cTime属性标记了namenode存储系统的创建时间,刚格式化的存储系统值为0,文件系统数据更新后会有新的时间戳。storageType属性说明该存储目录包含的是namenode的数据结构。in_use.lock文件是一个锁文件,namenode使用该文件为存储目录加锁,可避免其他namenode实例同时使用甚至破坏同一个存储目录。
20.文件系统客户端执行写操作时(如创建和移动文件),这些事物先记录到编辑日志中,namenode在内存中维护文件系统的元数据;当编辑日志被修改时,相关元数据信息也同步更新。编辑日志概念上虽然像单个实体,实质上是磁盘上的多个文件,每个文件称为一个“段”(segment),名称由前缀edits及后缀组成,后缀是该文件所包含的事物ID。任一时刻只有一个文件处于打开可写状态,例如上面的edits_inprogress_XXXX。在每个事务完成之后并在向客户端发送成功码之前,文件都需要更新和同步。当namenode向多个目录写数据时,只有在所有操作更新并同步到每个副本之后才可返回成功码。
每个fsimage文件都是文件系统元数据的一个完整的永久性检查点,前缀中的序号表示映像文件中的最后一个事务。如果namenode发生故障,最近的fsimage文件将被载入到内存以重构元数据的最近状态,再从相关点开始向前执行编辑日志中记录的每个事务。事实上namenode在启动阶段也是这样做的。
如上所述,编辑日志会无限增长,由于需要恢复非常长的编辑日志中的各项事务,故障namenode的重启会比较慢,解决方案是运行辅助namenode,为主namenode内存中的文件系统元数据创建检查点。创建检查点步骤如下所示:

(1)辅助namenode请求主namenode停止使用正在进行中的edits文件,这样新的编辑操作记录到一个新文件中。主namenode还会更新所有存储目录中的seen_txid文件。
(2)辅助namenode从主namenode获取最近的fsimage和edits文件,采用HTTP GET方式。
(3)辅助namenode将fsimage文件载入内存,逐一执行edits文件中的事务,创建新的合并后的fsimage文件。
(4)辅助namenode将新的fsimage文件发送回主namenode(使用HTTP PUT方式),主namenode将其保存为临时的.ckpt文件。
(5)主namenode重新命名临时的fsimage文件,便于日后使用。
最终,主namenode拥有最新的fsimage文件和一个更小的edits-inprogress文件。当namenode处在安全模式时,管理员也可调用hdfs dfsadmin -saveNamespace命令来创建检查点。因此该过程解释了辅助namenode与主namenode有相近内存需求的原因,即辅助namenode也把fsimage文件存入自己的内存。因此大型集群中Secondarynamenode需要运行在另一台机子上的原因。
创建检查点的触发条件受两个参数控制:(1)辅助namenode默认每隔一小时(由dfs.namenode.checkpoint.period设置,以秒为单位)创建检查点。(2)如果从上一个检查点开始编辑日志的大小已经达到默认100万个事务(由dfs.namenode.checkpoint.txns设置),即使不到创建间隔也会创建检查点,检查数量的频率默认为每分钟一次(由dfs.namenode.checkpoint.check.period设置,以秒为单位)。
21.辅助namenode的检查点目录(dfs.namenode.checkpoint.dir)的布局和主namenode检查点目录的布局相同,如下所示:

从辅助namenode恢复数据有两种方法:(1)将该存储目录复制到新的namenode中。(2)使用-importCheckpoint参数启动namenode守护进程,从而将辅助namenode作为新的主namenode。借助该参数,仅当dfs.namenode.name.dir属性定义的目录中没有元数据时,辅助namenode会从dfs.namenode.checkpoint.dir属性定义的目录中载入最新的检查点namenode元数据,因此不会覆盖现有元数据。
22.datanode与namenode不同,它的存储目录是初始阶段自动创建的,不需要用格式化命令。datanode的目录结构如下所示:

HDFS数据块存储在以blk_为前缀名的文件中,文件名包含了该文件存储的块的原始字节数。每个块有一个相关联的带有.meta后缀的元数据文件。元数据文件包括头部(含版本和类型信息)和该块各区段的一系列校验和。每个块属于一个数据块池(blockpool),每个数据块池都有自己的存储目录,目录名与namenode的VERSION文件中的blockpoolID相同。
当目录中数据块数量增加到默认64个数据块(由dfs.datanode.numblocks设置)时,就创建一个子目录存放新的数据块及其元数据信息。这样即使HDFS中块数量很多,目录树的层数也不多,便于管理。如果dfs.datanode.data.dir属性指定了不同磁盘上的多个目录,那么数据块会以轮转方式写到各个目录中,同一个datanode上每个磁盘上的块不会重复,但是不同datanode之间的块可能重复。
23.namenode启动时,首先将映像文件fsimage载入内存,并执行编辑日志edits中的各项编辑操作,一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的新编辑日志,这个过程中namenode的文件系统对于客户端来说是只读的(例如显示文件列表)还不能进行文件修改操作(写、删除或重命名),称为安全模式。
一开始系统中数据块的位置不由namenode维护,而是以块列表的形式存储在datanode中。在系统操作期间,namenode会在内存中保留所有块位置的映射信息。在安全模式下,各datanode会向namenode发送最新的块列表信息。如果满足最小副本条件(minimal replication condition),namenode会在30秒钟后退出安全模式,该条件即整个HDFS中有99.9%的数据块满足最小副本数量(默认值为1,由dfs.namenode.replication.min设置)。如果是启动一个新的刚格式化的HDFS集群,系统中没有任何数据块,所以namenode不会进入安全模式。
要查看namenode是否处于安全模式,可以使用如下命令,或从HDFS的网页页面查看:
hdfs dfsadmin -safemode get
有时用户希望先退出安全模式启动某个其他命令,可以用以下命令:
hdfs dfsadmin -safemode wait
#command to read or write a file
在维护和升级集群时,管理员可以随时将namenode进入或离开安全模式,因为需要确保数据在指定时间段内只读,使用以下命令进入安全模式:
hdfs dfsadmin -safemode enter运行以下命令可以使namenode离开安全模式:
hdfs dfsadmin -safemode leave24.HDFS日志能够记录所有文件系统访问请求,对日志进行审计是log4j在INFO级别实现的。默认情况没有启用该特性,可以在$HADOOP_HOME/etc/hadoop/hadoop-env.sh文件中增加下面这行状态变量启用日志审计:
export HDFS_AUDIT_LOGGER=”INFO,RFAAUDIT”每个HDFS事件均在审计日志hdfs-audit.log中生成一行日志记录。hdfs dfsadmin命令用途较广,可以查找HDFS状态信息,又可以在HDFS上执行管理操作,该命令一般需要超级用户权限,部分命令参数如下:
25.hdfs fsck命令检查HDFS中文件健康情况,例如所有datanode中缺失的块以及过少或过多的块,如下所示:

其中Over-replicated blocks表示副本数超过最小副本数量的块,HDFS会自动删除多余副本;Under_replicated blocks表示副本数少于最小副本数量的块,HDFS会自动创建新副本;Mis-replicated blocks表示违反副本放置策略的块,例如默认最少副本数为3的多机架集群中,若一个数据块的三个副本都放在同一个机架里,可认定该块的副本放置错误,应该两个在本机架,一个在另一个机架;Corrupt blocks表示所有副本都已损坏的块;Missing replicas表示集群中没有任何副本的块。要注意的是,fsck命令只从namenode获取数据块的元数据信息,不与任何datanode进行交互。
损坏的块和缺失的块最需要注意,因为这意味着数据已经丢失了。此时有两种选择:(1)使用hdfs fsck -move命令将受影响的文件移到HDFS的/lost+found目录,这些文件会分裂成连续的块链表帮助挽回损失。(2)使用-delete参数删除受影响的文件。
hdfs fsck命令还可以帮助用户找到属于特定文件的数据块,例如:
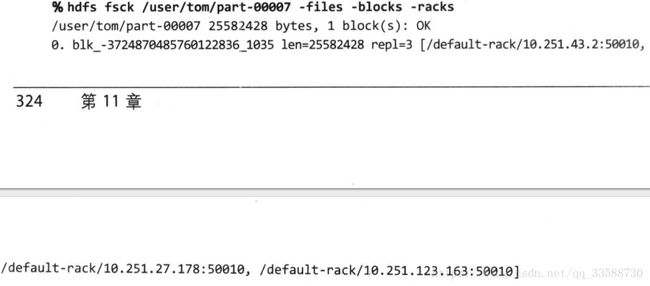
该输出表示文件/user/tom/part-00007包含一个数据块,该块三个副本存储在最后三个datanode上。-files参数显示第一行信息,包括文件名称、大小、块数量和健康状况(是否有缺失的块)。-blocks参数描述文件中各个块的信息,每个块一行。-racks参数显示每个块的机架位置和datanode的地址。
26.各datanode运行一个块扫描器,默认每504小时(三周,由dfs.datanode.scan.period.hours设置)通过扫描器维护的块列表依次扫描检测本节点上的所有块,从而在客户端读到坏块之前及时检测并报告给namenode修复块。扫描器使用了节流机制,块扫描器工作时仅占用一小部分磁盘带宽。用户通过网页http://

通过在地址栏里指定listblocks参数,即http://

第一列是块ID,后面是键值对,块的状态(status)要么是failed,要么ok,由最近一次块扫描是否检测到校验和决定,扫描类型(type)可以是local、remote或none。如果扫描操作由后台线程执行则为local;如果扫描操作由客户端或其他datanode执行则为remote;如果针对该块的扫描尚未执行则为none。最后一项信息是扫描时间,从1970/01/01午夜开始的毫秒数。
27.随着时间推移,各datanode上的块分布会越来越不均衡,不均衡的集群会降低MapReduce的数据本地性,导致部分datanode相对更加繁忙,需要避免这种情况。均衡器(balancer)程序是一个Hadoop守护进程,将块从忙碌的datanode移到相对空闲的datanode,重新分配块,同时坚持副本放置原则,将副本分散到不同机架,直到每个datanode的使用率(已用空间/总空间)和集群使用率非常接近,差距不超过给定阈值。调用下列命令启动均衡器:
start-balancer.sh-threshold参数指定阈值(百分比格式)。若省略,默认阈值是100%,任何时刻,集群中都只运行一个均衡器。均衡器使集群变得均衡之后,就不能再移动块,并且也要保持与namenode的连接。均衡器在标准日志目录中创建一个日志文件,记录它执行的每轮重新分配过程,每轮次输出一行,如下所示:

为降低集群负荷,均衡器在后台运行,在不同节点之间复制数据的带宽是有限的,默认值很小为1MB/s,可通过hdfs-site.xml中的dfs.datanode.balance.bandwidthPerSec属性设置,单位为字节。
28.所有Hadoop守护进程都会产生日志文件,可以通过守护进程的网页(守护进程网页的/logLevel目录下)改变任何log4j日志的日志级别,例如启用资源管理器相关所有类的日志调试特性,可以访问http://resource-manager-host:8088/logLevel,并将日志名org.apache.hadoop.yarn.server.resourcemanager设置为DEBUG级别,也可以用以下命令:
hadoop daemonlog -setlevel resource-manager-host:8088 \
org.apache.hadoop.yarn.server.resourcemanager DEBUG
上面两个方式修改的日志级别会在守护进程被重启时重置。如果要永久变更日志级别,需要在$HADOOP_HOME/etc/hadoop/log4j.properties文件中添加如下赋值代码:
log4j.logger.org.apache.hadoop.yarn.server.resourcemanager=DEBUGHadoop守护进程还提供一个网页(对应节点页面的/stacks子地址)对守护进程的JVM中运行的线程执行线程转储(thread dump,指JVM某一个时刻运行的所有线程的快照,每个线程都有自己的调用堆栈,在一个给定时刻体现为一个独立功能。线程转储会提供JVM中所有线程的堆栈信息)。例如,可通过http://resource-manager-host:8088/stacks获得资源管理器的线程转储,如下所示:
29.Hadoop守护进程收集事件和度量相关的信息,这些信息称为“度量”(metric)。例如各datanode会收集以下度量:写入字节数、块的副本数和客户端发起的读操作请求数等。其中dfs、mapred、yarn和rpc为四个方面的度量场景,例如datanode会分别为dfs和rpc场景收集度量。
度量与计数器的不同点有:(1)度量由守护进程收集,而计数器先针对MapReduce任务进行采集,再针对整个作业进行汇总。(2)用户群不同,度量为管理员服务,计数器主要为MapReduce用户服务。(3)数据采集和聚集过程不同。MapReduce系统确保计数器值由任务JVM产生,再传回application master,最终传回运行作业的客户端。整个过程中任务进程和application master都会执行汇总操作;而度量的收集机制独立于接收更新的组件,有多种输出度量的方式包括本地文件和JMX等。守护进程收集度量,并在输出之前执行汇总操作。
Hadoop度量可以使用JMX工具例如JDK自带的JConsole查看。如果是远程访问需要将JMX系统属性com.sun.management.jmxremote.port及其他一些用于安全的属性设置为允许访问。例如在namenode实现该功能,需要在$HADOOP_HOME/etc/hadoop/hadoop-env.sh文件中设置以下语句:
HADOOP_NAMENODE_OPTS=”-Dcom.sun.management.jmxremote.port=8004”也可以通过特定守护进程的/jmx网页查看该守护进程的JMX度量(JSON格式),例如在网页http://namenode-host:50070/jmx查看namenode的度量,如下所示:

30.如果namenode永久性元数据丢失或破坏,则整个文件系统无法使用,因此备份元数据非常关键。可以在系统中分别保存若干份不同时间的备份,最直接的元数据备份方法是使用hdfs dfsadmin命令下载namenode最新的fsimage文件的副本:
hdfs dfsadmin -fetchImage fsimage.backup备份原则是无法重新生成的数据的优先级最高,这些数据对业务非常关键,而可再生数据和一次性数据价值有限,优先级最低无需备份。distcp是一个理想的备份工具,其并行的文件复制功能可以将备份文件存储到其他HDFS集群或例如亚马逊S3等其他文件系统中。HDFS还允许用户对文件系统进行快照,快照是对文件系统在给定时刻的一个只读副本,由于并不真正复制数据,因此快照非常高效,它们简单地记下每个文件的元数据和块列表,对于重构快照时刻的文件系统已经足够。
日常的集群维护有以下事务:(1)元数据备份。(2)HDFS数据备份。(3)定期在整个文件系统上运行fsck命令,主动查找丢失或损失的块。(4)定期运行均衡器使各datanode比较均衡。
31.集群需要经常添加节点或移除节点,例如为了扩大容量,需要委任节点,如果需要缩小集群规模或者某些节点表现反常,故障率过高或性能过于低下等,需要解除节点。通常节点同时运行datanode和节点管理器,所以两者一般同时被委任或解除。允许连接到namenode的datanode列表放在namenode的一个文件中,文件名称由dfs.hosts属性指定,该文件每行对应一个datanode的网络地址。
同样,连接到资源管理器的各节点管理器也在同一个文件中指定(文件名由yarn.resourcemanager.nodes.include-path指定)。通常集群中的节点同时运行datanode和节点管理器的守护进程,dfs.host和yarn.resourcemanager.nodes.include-path会同时指向一个文件,即$HADOOP_HOME/etc/hadoop/include文件。向集群添加新节点的步骤如下:
(1)将新节点的网络地址添加到include文件中。
(2)运行以下指令,将新增的datanode更新至namenode信息:
hdfs dfsadmin -refreshNodes(3)运行以下指令,将新增的节点管理器更新至资源管理器:
yarn rmadmin -refreshNodes(4)将新节点的列表写入更新slaves文件(含有datanode与nodemanager地址列表),这样Hadoop控制脚本会将新节点包括在未来操作中。
(5)启动新的datanode和nodemanager。
(6)检查新的datanode和节点管理器是否都出现在网页界面中。
HDFS不会自动将块从旧datanode移到新的datanode以平衡集群,需要手动运行均衡器。
32.解除旧节点时,需要解除的节点列表需要放到exclude文件中,对于datanode该文件由dfs.hosts.exclude属性设置,对于YARN来说由yarn.resourcemanager.nodes.exclude-path设置。通常这两个属性指向同一个文件。判断一个nodemanager是否能连接到资源管理器很简单,当节点管理器地址出现在include文件且未出现在exclude文件中时才可。如果未指定include文件或文件内为空,则意味着所有节点都包含在include文件中;而对于HDFS不同,如果一个datanode同时出现在include和exclude文件中,意味着该节点可连接但马上会被解除,如果一个datanode没有出现在include和exclude文件中,则节点无法连接。移除节点的步骤如下:
(1)将待解除节点的网络地址添加到exclude文件中,不更新include文件。
(2)执行以下命令,刷新namenode设置:
hdfs dfsadmin -refreshNodes(3)执行以下命令,刷新资源管理器设置:
yarn rmadmin -refreshNodes(4)转到网页界面,查看待解除datanode的管理状态是否已变为“正在解除”(Decommission In Progress),此时这些datanode会把它们的块复制到其他datanode中。
(5)当所有待解除datanode的状态变为“解除完毕”(Decommissioned)时,表明所有块已复制完毕,关闭已经解除的节点。
(6)从include文件中移除这些节点地址,并运行以下命令:
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
(7)从slaves文件中移除节点。
33.在升级集群系统时,需要考虑API兼容性、数据兼容性和连接兼容性。其中连接兼容性的规则是,客户端与服务器必须有相同的主版本号,但次版本号或单点发行版本号可以不同,例如客户端2.0.2版可和服务器2.1.0版工作,但不可和服务器3.0.0版工作。如果文件系统布局没有改变,升级集群非常容易:关闭旧守护进程,在集群上安装新版本Hadoop,升级配置文件,启动新守护进程,令客户端使用新的库,该过程可逆可还原为旧版本。
成功升级版本后,还需要执行两个清理步骤:(1)从集群中移除旧的安装和配置文件。(2)对代码和配置文件中针对“被弃用”(deprecation)警告信息进行修复。Cloudera Manager和Apache Ambari等集群管理软件升级过程更容易,它们使用滚动升级,节点以批量方式升级,这样客户端不会感受到服务中断。
不过如果新旧HDFS的文件系统布局不同,则按照上述升级方法会使namenode无法工作,会在日志文件中产生如下信息:

升级HDFS会保留前一版本的元数据和数据副本,不过并不需要两倍存储开销,因为datanode使用硬连接保存指向同一个数据块的两个应用(当前版本和前一版本),这样可以方便回滚到前一个版本,但只能回滚到前一个版本不能前几个版本。下次升级HDFS数据和元数据前,需要删除这次升级保留的前一版本,该过程称为“定妥升级”(finalizing the upgrade)。一旦执行该操作,就无法回滚到该前一版本。
仅当文件系统健康时才能升级,因此有必要在升级前调用hdfs fsck命令全面检查文件系统状态。而且最好保留该检查输出报告,升级后再次运行该命令检查一遍,对比两份检查报告的内容。在升级前最好清空临时文件,包括HDFS的MapReduce系统目录和本地临时文件等。因此,如果升级集群会导致文件系统布局变化,需要采用以下步骤升级:
(1)在执行升级任务之前,确保前一升级已经定妥。
(2)关闭YARN和MapReduce守护进程。
(3)关闭HDFS,并备份namenode目录。
(4)在集群和客户端安装新版本的Hadoop。
(5)使用-upgrade选项启动HDFS。
(6)等待,直到升级完成。
(7)检验HDFS是否运行正常,例如使用fsck,检验时使HDFS进入安全模式。
(8)启动YARN和MapReduce守护进程。
(9)回滚或定妥升级任务(可选)。
运行升级任务时,最好移除PATH环境变量下的Hadoop脚本,这样用户不会混淆不同版本的脚本。通常可以为新的安装目录定义两个环境变量,例如OLD_HADOOP_HOME和NEW_HADOOP_HOME。在步骤(5)中,为了执行升级,可运行如下命令:
$NEW_HADOOP_HOME/bin/start-dfs.sh -upgrade该命令的结果是让namenode升级元数据,将前一版本放在dfs.namenode.name.dir下的名为previous的新目录中。同样datanode升级存储目录,保留原先副本,将其存放在previous目录中。步骤(6)等待升级过程时,可以用以下命令查看升级进度,升级事件也会出现在守护进程的日志文件中:
$NEW_HADOOP_HOME/bin/hdfs dfsadmin -upgradeProgress status步骤(9)中如果新版本无法正常工作,可以回滚到前一版本。首先关闭新的守护进程:
$NEW_HADOOP_HOME/bin/stop-dfs.sh然后使用-rollback选项启动旧版本HDFS:
$OLD_HADOOP_HOME/bin/start-dfs.sh -rollback该命令会让namenode和datanode使用升级前的副本替换当前的存储目录,文件系统返回之前的状态。如果满足最新版本的HDFS,要定妥升级移除升级前的存储目录,需要执行以下命令:
$NEW_HADOOP_HOME/bin/hdfs dfsadmin -finalizeUpgrade
$NEW_HADOOP_HOME/bin/hdfs dfsadmin -upgradeProgress status