html5录音+百度语音实现语音识别
首先,语音识别技术已经不是什么新鲜的词汇了,各大公司也提供了自己的语音识别API,据说百度、讯飞等公司的识别率已经达到99%。
最近我也想给网站加上一个语音识别功能,用于搜索词汇。我首选的是讯飞,毕竟人家是专业做语音的,但关于html5的SDK讯飞已经下架,无法使用人家现成的接口。
没办法只能使用百度的语音识别,百度语音识别,需要提供音频文件,格式为pcm、wav 、avr。所以需要做一个html5的录音功能,我辗转各个网站,浏览了三天的信息,入了无数个坑,也发现了现在的html5录音基本上使用的是recorder.js,通过配合html5的audio标签来实现的。但网上挂着的那些录音代码十个有九个不能用,特别坑。现在网上的html5录音格式基本上都是mp3的,我又费了一点劲调成了wav格式的。
现在步入正题哈
1.首先建一个html,代码如下:
2.再建一个HZRecorder.js
(function (window) {
//兼容
window.URL = window.URL || window.webkitURL;
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia;
var HZRecorder = function (stream, config) {
config = config || {};
config.sampleBits = config.sampleBits || 16; //采样数位 8, 16
config.sampleRate = config.sampleRate || (8000); //采样率(1/6 44100)
var context = new AudioContext();
var audioInput = context.createMediaStreamSource(stream);
var recorder = context.createScriptProcessor(4096, 1, 1);
var audioData = {
size: 0 //录音文件长度
, buffer: [] //录音缓存
, inputSampleRate: context.sampleRate //输入采样率
, inputSampleBits: 16 //输入采样数位 8, 16
, outputSampleRate: config.sampleRate //输出采样率
, oututSampleBits: config.sampleBits //输出采样数位 8, 16
, input: function (data) {
this.buffer.push(new Float32Array(data));
this.size += data.length;
}
, compress: function () { //合并压缩
//合并
var data = new Float32Array(this.size);
var offset = 0;
for (var i = 0; i < this.buffer.length; i++) {
data.set(this.buffer[i], offset);
offset += this.buffer[i].length;
}
//压缩
var compression = parseInt(this.inputSampleRate / this.outputSampleRate);
var length = data.length / compression;
var result = new Float32Array(length);
var index = 0, j = 0;
while (index < length) {
result[index] = data[j];
j += compression;
index++;
}
return result;
}
, encodeWAV: function () {
var sampleRate = Math.min(this.inputSampleRate, this.outputSampleRate);
var sampleBits = Math.min(this.inputSampleBits, this.oututSampleBits);
var bytes = this.compress();
var dataLength = bytes.length * (sampleBits / 8);
var buffer = new ArrayBuffer(44 + dataLength);
var data = new DataView(buffer);
var channelCount = 1;//单声道
var offset = 0;
var writeString = function (str) {
for (var i = 0; i < str.length; i++) {
data.setUint8(offset + i, str.charCodeAt(i));
}
}
// 资源交换文件标识符
writeString('RIFF'); offset += 4;
// 下个地址开始到文件尾总字节数,即文件大小-8
data.setUint32(offset, 36 + dataLength, true); offset += 4;
// WAV文件标志
writeString('WAVE'); offset += 4;
// 波形格式标志
writeString('fmt '); offset += 4;
// 过滤字节,一般为 0x10 = 16
data.setUint32(offset, 16, true); offset += 4;
// 格式类别 (PCM形式采样数据)
data.setUint16(offset, 1, true); offset += 2;
// 通道数
data.setUint16(offset, channelCount, true); offset += 2;
// 采样率,每秒样本数,表示每个通道的播放速度
data.setUint32(offset, sampleRate, true); offset += 4;
// 波形数据传输率 (每秒平均字节数) 单声道×每秒数据位数×每样本数据位/8
data.setUint32(offset, channelCount * sampleRate * (sampleBits / 8), true); offset += 4;
// 快数据调整数 采样一次占用字节数 单声道×每样本的数据位数/8
data.setUint16(offset, channelCount * (sampleBits / 8), true); offset += 2;
// 每样本数据位数
data.setUint16(offset, sampleBits, true); offset += 2;
// 数据标识符
writeString('data'); offset += 4;
// 采样数据总数,即数据总大小-44
data.setUint32(offset, dataLength, true); offset += 4;
// 写入采样数据
if (sampleBits === 8) {
for (var i = 0; i < bytes.length; i++, offset++) {
var s = Math.max(-1, Math.min(1, bytes[i]));
var val = s < 0 ? s * 0x8000 : s * 0x7FFF;
val = parseInt(255 / (65535 / (val + 32768)));
data.setInt8(offset, val, true);
}
} else {
for (var i = 0; i < bytes.length; i++, offset += 2) {
var s = Math.max(-1, Math.min(1, bytes[i]));
data.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7FFF, true);
}
}
return new Blob([data], { type: 'audio/wav' });
}
};
//开始录音
this.start = function () {
audioInput.connect(recorder);
recorder.connect(context.destination);
}
//停止
this.stop = function () {
recorder.disconnect();
}
//获取音频文件
this.getBlob = function () {
this.stop();
return audioData.encodeWAV();
}
//回放
this.play = function (audio) {
audio.src = window.URL.createObjectURL(this.getBlob());
}
//上传
this.upload = function (url, callback) {
var fd = new FormData();
fd.append("audioData", this.getBlob());
var xhr = new XMLHttpRequest();
if (callback) {
xhr.upload.addEventListener("progress", function (e) {
callback('uploading', e);
}, false);
xhr.addEventListener("load", function (e) {
callback('ok', e);
}, false);
xhr.addEventListener("error", function (e) {
callback('error', e);
}, false);
xhr.addEventListener("abort", function (e) {
callback('cancel', e);
}, false);
}
xhr.open("POST", url);
xhr.send(fd);
}
//音频采集
recorder.onaudioprocess = function (e) {
audioData.input(e.inputBuffer.getChannelData(0));
//record(e.inputBuffer.getChannelData(0));
}
};
//抛出异常
HZRecorder.throwError = function (message) {
alert(message);
throw new function () { this.toString = function () { return message; } }
}
//是否支持录音
HZRecorder.canRecording = (navigator.getUserMedia != null);
//获取录音机
HZRecorder.get = function (callback, config) {
if (callback) {
if (navigator.getUserMedia) {
navigator.getUserMedia(
{ audio: true } //只启用音频
, function (stream) {
var rec = new HZRecorder(stream, config);
callback(rec);
}
, function (error) {
switch (error.code || error.name) {
case 'PERMISSION_DENIED':
case 'PermissionDeniedError':
HZRecorder.throwError('用户拒绝提供信息。');
break;
case 'NOT_SUPPORTED_ERROR':
case 'NotSupportedError':
HZRecorder.throwError('浏览器不支持硬件设备。');
break;
case 'MANDATORY_UNSATISFIED_ERROR':
case 'MandatoryUnsatisfiedError':
HZRecorder.throwError('无法发现指定的硬件设备。');
break;
default:
HZRecorder.throwError('无法打开麦克风。异常信息:' + (error.code || error.name));
break;
}
});
} else {
HZRecorder.throwErr('当前浏览器不支持录音功能。'); return;
}
}
}
window.HZRecorder = HZRecorder;
})(window);
现在前台的代码就到这里了。
3.下面进行Servlet处理
我先说一下,这是在Tomcat服务器中运行的。
下面的这个Servlet:UploadVideoServlet.do是将音频文件保存到服务器端的。
代码如下:
package com.hanfeng.servlet;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.PrintWriter;
import java.util.ArrayList;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import javax.sound.sampled.AudioInputStream;
import javax.sound.sampled.AudioSystem;
import javax.sound.sampled.Clip;
import java.io.IOException;
import javax.servlet.annotation.WebServlet;
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
import com.hanfeng.dao.Music;
import com.hanfeng.dao.Regist;
import com.hanfeng.service.MusicService;
import com.hanfeng.service.RegistService;
public class UploadVideoServlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
MusicService musicService = new MusicService();
HttpSession hs = request.getSession();
String userName = (String) hs.getAttribute("username");
// 得到上传文件的保存目录,将上传的文件存放于WEB-INF目录下,不允许外界直接访问,保证上传文件的安全
String savePath = "D:/java web/apache-tomcat-9.0.0.M17/webapps/pcm";
File file = new File(savePath);
// 判断上传文件的保存目录是否存在
if (!file.exists() && !file.isDirectory()) {
System.out.println(savePath + "目录不存在,需要创建");
// 创建目录
file.mkdir();
}
// 消息提示
String message = "";
try {
String filename = null;
// 使用Apache文件上传组件处理文件上传步骤:
// 1、创建一个DiskFileItemFactory工厂
DiskFileItemFactory factory = new DiskFileItemFactory();
// 2、创建一个文件上传解析器
ServletFileUpload upload = new ServletFileUpload(factory);
// 解决上传文件名的中文乱码
upload.setHeaderEncoding("UTF-8");
// 3、判断提交上来的数据是否是上传表单的数据
if (!ServletFileUpload.isMultipartContent(request)) {
// 按照传统方式获取数据
return;
}
// 4、使用ServletFileUpload解析器解析上传数据,解析结果返回的是一个List
List
//System.out.println(list.get(0));
String[] value = new String[5];
int i=0;
for (FileItem item : list) {
// 如果fileitem中封装的是普通输入项的数据
if (item.isFormField()) {
// System.out.println("歌曲名"+item.getString("musicName")+"类别"+item.getString("musicType"));
String name = item.getFieldName();
// 解决普通输入项的数据的中文乱码问题
value[i++] = item.getString("UTF-8");
// value = new String(value.getBytes("iso8859-1"),"UTF-8");
//System.out.println(name + "=" + value);
} else {// 如果fileitem中封装的是上传文件
// 得到上传的文件名称,
filename = "test.wav";
//item.getName();
System.out.println(filename);
if (filename == null || filename.trim().equals("")) {
continue;
}
// 注意:不同的浏览器提交的文件名是不一样的,有些浏览器提交上来的文件名是带有路径的,如:
// c:\a\b\1.txt,而有些只是单纯的文件名,如:1.txt
// 处理获取到的上传文件的文件名的路径部分,只保留文件名部分
filename = filename.substring(filename.lastIndexOf("\\") + 1);
// 获取item中的上传文件的输入流
InputStream in = item.getInputStream();
// 创建一个文件输出流
FileOutputStream out = new FileOutputStream(savePath + "\\" + filename);
// 创建一个缓冲区
byte buffer[] = new byte[1024];
// 判断输入流中的数据是否已经读完的标识
int len = 0;
// 循环将输入流读入到缓冲区当中,(len=in.read(buffer))>0就表示in里面还有数据
while ((len = in.read(buffer)) > 0) {
// 使用FileOutputStream输出流将缓冲区的数据写入到指定的目录(savePath + "\\"
// + filename)当中
out.write(buffer, 0, len);
}
// 关闭输入流
in.close();
// 关闭输出流
out.close();
// 删除处理文件上传时生成的临时文件
item.delete();
message = "文件上传成功!";
}
}
} catch (Exception e) {
message = "文件上传失败!";
e.printStackTrace();
}
}
}
4.下面进入百度语音识别端口的连接,
首先进入百度语音网站申请端口(都是免费的)http://yuyin.baidu.com/
(1)点击SDK下载

(2)选择应用,自己填一下信息,申请一下,很简单的

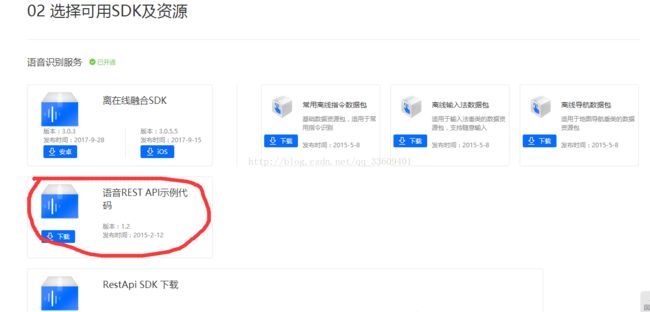
(3)选择SDK,画红圈的是百度语音提供的demo,做javaweb用这个足以,就下载那个就行。
选择java,导入到自己的工程中。
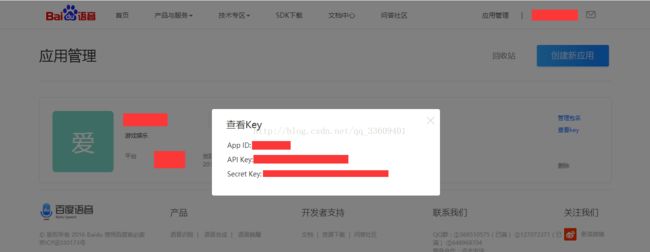
(4)上述的都弄好了之后,进入应用管理,获取自己的key
5.下面进行百度语音识别API连接
建一个java文件
package com.baidu.speech.serviceapi;
import java.io.BufferedReader;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.xml.bind.DatatypeConverter;
import org.json.JSONObject;
public class Sample {
private static final String serverURL = "http://vop.baidu.com/server_api";
private static String token = "";
private static final String testFileName = "D:/java web/apache-tomcat-9.0.0.M17/webapps/pcm/test.wav";//需要识别的音频文件
//put your own params here
private static final String apiKey = "自己的apiKey";
private static final String secretKey = "自己的secretKey";
private static final String cuid = “自己的网卡物理地址";
public static void main(String[] args) throws Exception {
getToken();
method1();
method2();
}
private static void getToken() throws Exception {
String getTokenURL = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials" +
"&client_id=" + apiKey + "&client_secret=" + secretKey;
HttpURLConnection conn = (HttpURLConnection) new URL(getTokenURL).openConnection();
token = new JSONObject(printResponse(conn)).getString("access_token");
}
private static void method1() throws Exception {
File wavFile = new File(testFileName);
HttpURLConnection conn = (HttpURLConnection) new URL(serverURL).openConnection();
// construct params
JSONObject params = new JSONObject();
params.put("format", "wav");
params.put("rate", 16000);
params.put("channel", "1");
params.put("token", token);
params.put("cuid", cuid);
params.put("lan", "zh");
params.put("len", wavFile.length());
params.put("speech", DatatypeConverter.printBase64Binary(loadFile(wavFile)));
// add request header
conn.setRequestMethod("POST");
conn.setRequestProperty("Content-Type", "application/json; charset=utf-8");
conn.setDoInput(true);
conn.setDoOutput(true);
// send request
DataOutputStream wr = new DataOutputStream(conn.getOutputStream());
wr.writeBytes(params.toString());
wr.flush();
wr.close();
printResponse(conn);
}
private static void method2() throws Exception {
File wavFile = new File(testFileName);
HttpURLConnection conn = (HttpURLConnection) new URL(serverURL
+ "?cuid=" + cuid + "&token=" + token).openConnection();
// add request header
conn.setRequestMethod("POST");
conn.setRequestProperty("Content-Type", "audio/wav; rate=16000");
conn.setDoInput(true);
conn.setDoOutput(true);
// send request
DataOutputStream wr = new DataOutputStream(conn.getOutputStream());
wr.write(loadFile(wavFile));
wr.flush();
wr.close();
printResponse(conn);
}
private static String printResponse(HttpURLConnection conn) throws Exception {
if (conn.getResponseCode() != 200) {
// request error
return "";
}
InputStream is = conn.getInputStream();
BufferedReader rd = new BufferedReader(new InputStreamReader(is));
String line;
StringBuffer response = new StringBuffer();
while ((line = rd.readLine()) != null) {
response.append(line);
response.append('\r');
}
rd.close();
System.out.println(new JSONObject(response.toString()).toString(4));
//System.out.println(response.toString());
return response.toString();
}
private static byte[] loadFile(File file) throws IOException {
InputStream is = new FileInputStream(file);
long length = file.length();
byte[] bytes = new byte[(int) length];
int offset = 0;
int numRead = 0;
while (offset < bytes.length
&& (numRead = is.read(bytes, offset, bytes.length - offset)) >= 0) {
offset += numRead;
}
if (offset < bytes.length) {
is.close();
throw new IOException("Could not completely read file " + file.getName());
}
is.close();
return bytes;
}
public static String getChinese(String paramValue) {
String regex = "([\u4e00-\u9fa5]+)";
String str = "";
Matcher matcher = Pattern.compile(regex).matcher(paramValue);
while (matcher.find()) {
str+= matcher.group(0);
}
return str;
}
}
好了做完上述操作基本上语音识别就实现了,自己可以先打开html的录音录好后,运行java程序,就可以查看语音识别结果了。
当然你也可以将main方法去掉,将代码放入到一个Servlet中,将识别结果return出来,可以用ajaxj将结果回调获取,传值到搜索的页面,获得搜索结果。
这是我做的Demo,有需要的可以自行下载 https://download.csdn.net/download/qq_33609401/10847695
好的,就这些了,希望能帮助到需要语音识别的你们。
如果有不懂的地方可以留言,谢谢。