inception v3模型经过迁移学习后移植到移动端的填坑经历
先混乱的记录下
1、在将迁移后的pb文件转换为lite文件时报错,
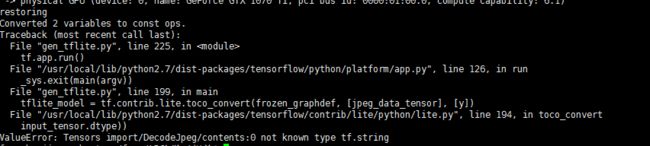
使用 graph.get_operations()查看tensor,Tensor("DecodeJpeg/contents:0", shape=(), dtype=string),原来使用TensorFlow中提供的图像读取函数tf.image.decode_jpeg()得到的是原始的图像数据,格式为byte数组,具体的格式对照如下图所示
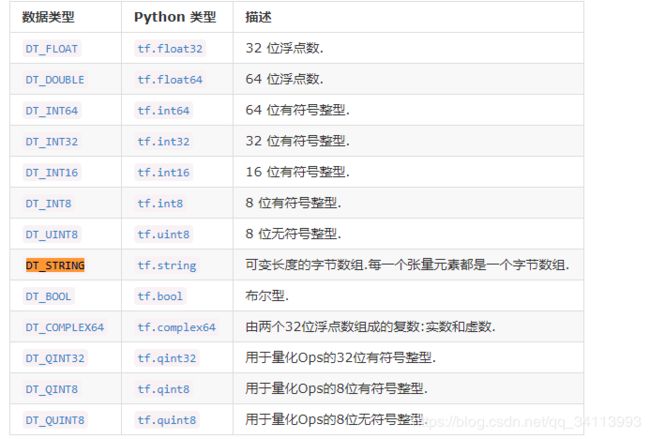
这跟print( tf.gfile.FastGFile(os.path.join(root, file), 'rb').read())类型bytes[]一致,但是该张量作为模型的输入是不合适的,因为缺少了batch信息,我们在apk端的imgdata是个四维数组,第一维是batchsize,那么在inception V3模型中已经有相应的转换数据格式的节点Cast(类型转换),expanddims(增加维度),resizeBilinear(将输入resize为一维向量),那么直接使用resizeBilinear节点作为输入节点,当然,apk端的imgdata此时未经过归一化处理,如果apk端已经进行了归一化处理,那么模型的输入节点就应该为Mul节点了。这样再进行模型转换就没有问题了。
2、对固化好的pb文件进行量化时的操作命令
bazel-bin/tensorflow/tools/quantization/quantize_graph --input=scr_v6.pb \
--output_node_names="output" \
--output= quantized_graph.pb \
--mode=eightbit
3、如果需要将pb文件转换为lite文件那么需要先对模型进行优化,以去掉不需要的和不支持的节点
先编译下该模块bazel build tensorflow/python/tools:optimize_for_inference,如果之前编译过则不需要再编译,然后执行
bazel-bin/tensorflow/python/tools/optimize_for_inference --input=scr_v6.pb \
--output=optimized.pb \
--frozen_graph=True \
--input_names=Mul \
--output_names=output/prob
然后再使用toco命令将pb文件转换为量化的tflite文件
bazel build tensorflow/contrib/lite/toco:toco,同样,之前编译过就不需要再编译。
bazel-bin/tensorflow/contrib/lite/toco/toco --input_file=scr_v6.pb \
--input_format=TENSORFLOW_GRAPHDEF \
--output_format=TFLITE --output_file=quantize_graph_v2.tflite \
--inference_type=QUANTIZED_UINT8 \
--input_arrays=Mul \
--output_arrays=output/prob \
--input_shapes=1,299,299,3 \
--default_ranges_min=0.0 \
--default_ranges_max=255.0
4、转换成功后移植到android中,但是预测结果变化很大,该问题尚未搞明白,尝试在代码中添加如下语句,来生成量化模型,首先在loss函数后加
tf.contrib.quantize.create_training_graph(quant_delay=get_quant_delay()) #它会自动将计算图伪量化,在生成pb文件的代码前添加
tf.contrib.quantize.create_eval_graph() #增加这段代码
即可生成量化后的模型文件。
本文参考:
https://blog.csdn.net/qq_16564093/article/details/78996563