神经网络中超参数的选择
超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
首先需要知道的是并不存在适用于所有场景的超参数,不同的数据集、模型适用的超参数可能不同,因此我们需要尝试不同的超参数,然后得到最优。
超参数的分类:
一般可以将超参数分为两类:
-
优化器超参数:包括学习率、minn_batch大小、迭代的epoch次数;
-
模型超参数:包括网络层数和隐藏层单元数。
下面开始介绍各个超参数如何在实践中进行选择。
1. 学习率:
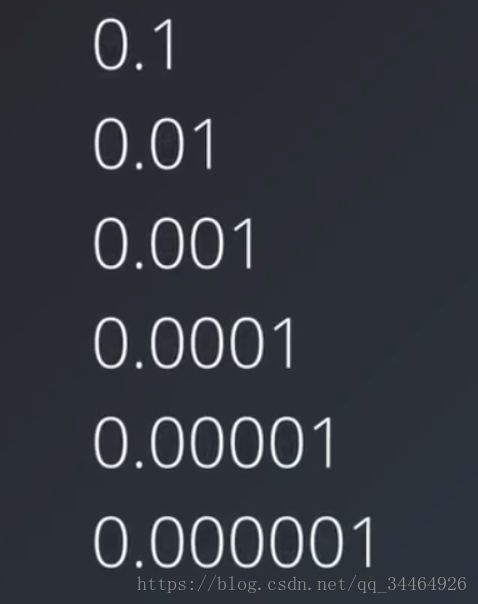
学习率是一个比较重要的超参数。即便是将别人构建的模型用于自己的数据集,也可能需要尝试多个不同的学习率。如何选择正确的学习率?学习率太小,会导致收敛太慢,需要很多的epoch才能到达最优点;而太大会导致越过最优点。比较常见的做法是从0.1开始,然后不断倍率减小进行尝试,例如
在实践中,往往会绘制出损失函数E随权重变化的函数来确定如何调整超参数。
如果训练误差在缓慢 减小,并且训练完成后仍在减小,可以尝试增大学习率。
如果训练误差在增加,不妨试试减小学习率。
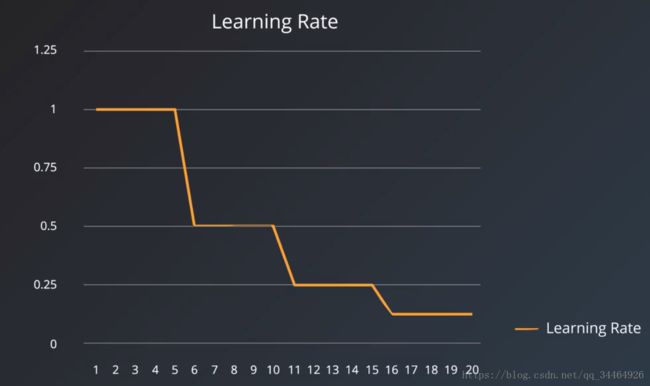
比较好的做法是使学习率能够自适应调整大小,从而达到最优解。例如:学习率衰减,这么做的方式是线性降低学习率,例如每五个epoch学习率减半:
或者指数方式降低学习率,例如每8个epoch后学习率乘上0.1:

在TensorFlow中,有一些能够自适应调整学习率的优化器,例如:
AdamOptimizer
AdagradOptimizer
在实践中如何调整学习率的两个例子:
-
假设你在训练一个模型。如果训练过程的输出如下所示,你将如何调整学习率来 提高训练性能?
| Epoch 1, Batch 1, Training Error: 8.4181 Epoch 1, Batch 2, Training Error: 8.4177 Epoch 1, Batch 3, Training Error: 8.4177 Epoch 1, Batch 4, Training Error: 8.4173 Epoch 1, Batch 5, Training Error: 8.4169 |
答案:提高学习率。因为模型在进行训练,但速度太慢。提高学习率将使优化器以更大的步长将参数推向最佳值。
-
假设你在训练一个模型。如果训练过程的输出如下所示,你将如何调整学习率来提高训练性能?
| Epoch 1, Batch 1, Training Error: 8.71 Epoch 1, Batch 2, Training Error: 3.25 Epoch 1, Batch 3, Training Error: 4.93 Epoch 1, Batch 4, Training Error: 3.30 Epoch 1, Batch 5, Training Error: 4.82 |
答案:降低学习率或者使用自适应学习率。因为误差瞬间降低然后升高,代表学习率太大,越过了最小值。
2. Mini-batch大小:
mini-batch大小对训练过程中的资源要求有影响,也会影响训练速度和迭代次数。
较大的batch大小会使训练过程中矩阵运算加快,但是也需要占用更多的内存计算空间。遇到内存不足或者TensorFlow错误,可通过减小batch大小来解决。
较小的batch会使误差计算有更多的噪声,并且运算缓慢,而且此噪声通常有助于防止训练过程陷入局部最优。
选择batch需要根据你的数据集大小和任务进行尝试。常见的batch大小:
| 1 2 4 8 16 32 64 128 256 |
通常32 是个不错的初始选择,也可以尝试64,128,256。
3. 迭代次数ecpoch:
要选择正确的epoch,我们关注的指标应该为验证误差。直观的方法是尝试不同的epoch,只要验证误差还在降低,就继续迭代。不过我们通常使用一种早期停止的技术,来确定何时停止训练模型。它的原理是监督验证误差,并在验证误差停止下降时停止训练。不过在定义停止触发器时,可以稍微灵活一点,尽管整体呈下降趋势,但验证误差往往会来回波动,因此我们不能在第一次看到验证误差开始增高时就停止训练,而是如果验证误差在最后10步或者20步内没有任何改进的情况下停止训练。
在TensorFlow中,可以通过以下方式实现早停。
- ValidationMonitor,参见文档。
在TensorFlow中,我们可以使用 ValidationMonitor 与 tf.contrib.learn 发挥两个功能:监督训练过程和在满足特定条件的情况下停止训练。
来自 ValidationMonitor 文档的以下示例展示了它的设置。注意最后三个参数表示我们正在优化的指标。
validation_monitor = tf.contrib.learn.monitors.ValidationMonitor(
test_set.data,
test_set.target,
every_n_steps=50,
metrics=validation_metrics,
early_stopping_metric="loss",
early_stopping_metric_minimize=True,
early_stopping_rounds=200)最后一个参数向 ValidationMonitor 表示如果损失未在 200 步(轮)训练内降低,则停止训练过程。
然后,validation_monitor 被传递给 tf.contrib.learn 的 "fit" 方法,后者运行以下训练过程:
classifier = tf.contrib.learn.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model",
config=tf.contrib.learn.RunConfig(save_checkpoints_secs=1))classifier.fit(x=training_set.data,
y=training_set.target,
steps=2000,
monitors=[validation_monitor])-
SessionRunHook
最近版本的 TensorFlow 废弃了 Monitor 函数,而采用 SessionRunHooks 。SessionRunHook 是 tf.train 不断发展的一部分,往后似乎将是实施早期停止的一个适当位置。
目前为止,tf.train 的训练钩子函数 中已存在两个预定义的停止 Monitor 函数。
StopAtStepHook:用于在特定步数之后要求停止训练的 Monitor 函数
NanTensorHook:监控损失并在遇到 NaN 损失时停止训练的 Monitor 函数
4. 隐藏单元/层的数量:
隐藏单元的数量和架构是衡量模型学习能力的主要标准。但是如果模型的学习能力太多,模型会出现过拟合,结果只会适应训练集而泛化能力弱。如果发现模型出现过拟合,也就是训练准确度远高于验证准确度,你可以尝试减少隐藏单元数量,当然也可以使用正则化技术。如Dropout或者L2正则化。因此就隐藏单元数量来说,越多越好,稍微超过理想数量不成问题,但是如果过多,会出现过拟合问题,所以你的模型无法训练,就向它添加更多隐藏层,并跟踪验证误差,持续添加隐藏层单元,直到验证误差开始增大。对于第一个隐藏层,有一条经验是将其设为大于输入层数量的一个数,
对于神经网络层数的选择:在实践中,3 层神经网络的性能通常优于 2 层神经网络,但是更深(4、5、6 层)帮助不大。这与卷积网络形成鲜明对比,卷积神经网络中层数越多相对性能越好,人们发现在卷积网络中深度是对良好的识别系统极其重要的组成部分(例如,10 个可学习层的数量级)。