一、简介
Spark SQL是Spark中处理结构化数据的模块。与基础的Spark RDD API不同,Spark SQL的接口提供了更多关于数据的结构信息和计算任务的运行时信息。在Spark内部,Spark SQL会能够用于做优化的信息比RDD API更多一些。Spark SQL如今有了三种不同的API:SQL语句、DataFrame API和最新的Dataset API。不过真正运行计算的时候,无论你使用哪种API或语言,Spark SQL使用的执行引擎都是同一个。这种底层的统一,使开发者可以在不同的API之间来回切换,你可以选择一种最自然的方式,来表达你的需求。
(本文针对spark1.6版本,示例语言为Scala)
二、概念
1. SQL。Spark SQL的一种用法是直接执行SQL查询语句,你可使用最基本的SQL语法,也可以选择HiveQL语法。Spark SQL可以从已有的Hive中读取数据。更详细的请参考Hive Tables 这一节。如果用其他编程语言运行SQL,Spark SQL将以DataFrame返回结果。你还可以通过命令行command-line 或者 JDBC/ODBC 使用Spark SQL。
2. DataFrame。是一种分布式数据集合,每一条数据都由几个命名字段组成。概念上来说,她和关系型数据库的表 或者 R和Python中的data frame等价,只不过在底层,DataFrame采用了更多优化。DataFrame可以从很多数据源(sources)加载数据并构造得到,如:结构化数据文件,Hive中的表,外部数据库,或者已有的RDD。
DataFrame API支持Scala, Java, Python, and R。
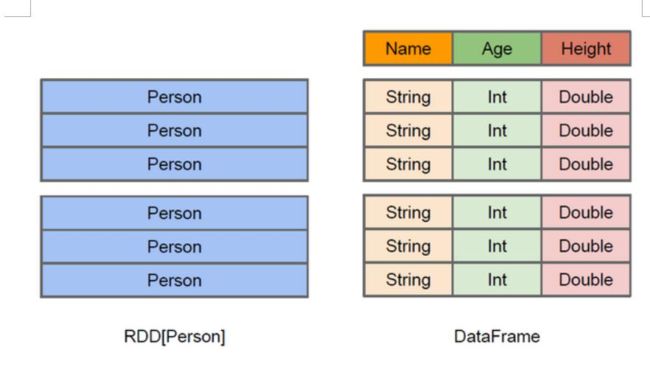
3. Datasets。是Spark-1.6新增的一种API,目前还是实验性的。Dataset想要把RDD的优势(强类型,可以使用lambda表达式函数)和Spark SQL的优化执行引擎的优势结合到一起。Dataset可以由JVM对象构建( constructed )得到,而后Dataset上可以使用各种transformation算子(map,flatMap,filter 等)。
Dataset API 对 Scala 和 Java的支持接口是一致的,但目前还不支持Python,不过Python自身就有语言动态特性优势(例如,你可以使用字段名来访问数据,row.columnName)。对Python的完整支持在未来的版本会增加进来。
三、创建并操作DataFrame
Spark应用可以用SparkContext创建DataFrame,所需的数据来源可以是已有的RDD(existing RDD
),或者Hive表,或者其他数据源(data sources.)以下是一个从JSON文件创建并操作DataFrame的小例子:
val sc: SparkContext // 已有的 SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlContext.read.json("examples/src/main/resources/people.json")
// 将DataFrame内容打印到stdout
df.show()
// age name
// null Michael
// 30 Andy
// 19 Justin
// 打印数据树形结构
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// select "name" 字段
df.select("name").show()
// name
// Michael
// Andy
// Justin
// 展示所有人,但所有人的 age 都加1
df.select(df("name"), df("age") + 1).show()
// name (age + 1)
// Michael null
// Andy 31
// Justin 20
// 筛选出年龄大于21的人
df.filter(df("age") > 21).show()
// age name
// 30 Andy
// 计算各个年龄的人数
df.groupBy("age").count().show()
// age count
// null 1
// 19 1
// 30 1
SQLContext.sql可以执行一个SQL查询,并返回DataFrame结果。
val sqlContext = ... // 已有一个 SQLContext 对象
val df = sqlContext.sql("SELECT * FROM table")
三、spark SQL与RDD互操作
Spark SQL有两种方法将RDD转为DataFrame。分别为反射机制和编程方式。
1. 利用反射推导schema。####
Spark SQL的Scala接口支持自动将包含case class对象的RDD转为DataFrame。对应的case class定义了表的schema。case class的参数名通过反射,映射为表的字段名。case class还可以嵌套一些复杂类型,如Seq和Array。RDD隐式转换成DataFrame后,可以进一步注册成表。随后,你就可以对表中数据使用 SQL语句查询了。
// sc 是已有的 SparkContext 对象
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 为了支持RDD到DataFrame的隐式转换
import sqlContext.implicits._
// 定义一个case class.
// 注意:Scala 2.10的case class最多支持22个字段,要绕过这一限制,
// 你可以使用自定义class,并实现Product接口。当然,你也可以改用编程方式定义schema
case class Person(name: String, age: Int)
// 创建一个包含Person对象的RDD,并将其注册成table
val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
people.registerTempTable("people")
// sqlContext.sql方法可以直接执行SQL语句
val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
// SQL查询的返回结果是一个DataFrame,且能够支持所有常见的RDD算子
// 查询结果中每行的字段可以按字段索引访问:
teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
// 或者按字段名访问:
teenagers.map(t => "Name: " + t.getAs[String]("name")).collect().foreach(println)
// row.getValuesMap[T] 会一次性返回多列,并以Map[String, T]为返回结果类型
teenagers.map(_.getValuesMap[Any](List("name", "age"))).collect().foreach(println)
// 返回结果: Map("name" -> "Justin", "age" -> 19)
2. 编程方式定义Schema。####
如果不能事先通过case class定义schema(例如,记录的字段结构是保存在一个字符串,或者其他文本数据集中,需要先解析,又或者字段对不同用户有所不同),那么你可能需要按以下三个步骤,以编程方式的创建一个DataFrame:
从已有的RDD创建一个包含Row对象的RDD,用StructType创建一个schema,和步骤1中创建的RDD的结构相匹配,把得到的schema应用于包含Row对象的RDD,调用这个方法来实现这一步:SQLContext.createDataFrame
例如:
// sc 是已有的SparkContext对象
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 创建一个RDD
val people = sc.textFile("examples/src/main/resources/people.txt")
// 数据的schema被编码与一个字符串中
val schemaString = "name age"
// Import Row.
import org.apache.spark.sql.Row;
// Import Spark SQL 各个数据类型
import org.apache.spark.sql.types.{StructType,StructField,StringType};
// 基于前面的字符串生成schema
val schema =
StructType(
schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true)))
// 将RDD[people]的各个记录转换为Rows,即:得到一个包含Row对象的RDD
val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// 将schema应用到包含Row对象的RDD上,得到一个DataFrame
val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema)
// 将DataFrame注册为table
peopleDataFrame.registerTempTable("people")
// 执行SQL语句
val results = sqlContext.sql("SELECT name FROM people")
// SQL查询的结果是DataFrame,且能够支持所有常见的RDD算子
// 并且其字段可以以索引访问,也可以用字段名访问
results.map(t => "Name: " + t(0)).collect().foreach(println)
四、spark SQL与其它数据源的连接与操作
Spark SQL支持基于DataFrame操作一系列不同的数据源。DataFrame既可以当成一个普通RDD来操作,也可以将其注册成一个临时表来查询。把 DataFrame注册为table之后,你就可以基于这个table执行SQL语句了。本节将描述加载和保存数据的一些通用方法,包含了不同的 Spark数据源,然后深入介绍一下内建数据源可用选项。
在最简单的情况下,所有操作都会以默认类型数据源来加载数据(默认是Parquet,除非修改了spark.sql.sources.default 配置)。
val df = sqlContext.read.load("examples/src/main/resources/users.parquet")
df.select("name", "favorite_color").write.save("namesAndFavColors.parquet")
你也可以手动指定数据源,并设置一些额外的选项参数。数据源可由其全名指定(如,org.apache.spark.sql.parquet),而 对于内建支持的数据源,可以使用简写名(json, parquet, jdbc)。任意类型数据源创建的DataFrame都可以用下面这种语法转成其他类型数据格式。
val df = sqlContext.read.format("json").load("examples/src/main/resources/people.json")
df.select("name", "age").write.format("parquet").save("namesAndAges.parquet")
Spark SQL还支持直接对文件使用SQL查询,不需要用read方法把文件加载进来。
val df = sqlContext.sql("SELECT * FROM parquet.`examples/src/main/resources/users.parquet`")
1. 连接JSON数据集####
Spark SQL在加载JSON数据的时候,可以自动推导其schema并返回DataFrame。用SQLContext.read.json读取一个包含String的RDD或者JSON文件,即可实现这一转换。
注意,通常所说的json文件只是包含一些json数据的文件,而不是我们所需要的JSON格式文件。JSON格式文件必须每一行是一个独立、完整的的JSON对象。因此,一个常规的多行json文件经常会加载失败。
// sc是已有的SparkContext对象
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 数据集是由路径指定的
// 路径既可以是单个文件,也可以还是存储文本文件的目录
val path = "examples/src/main/resources/people.json"
val people = sqlContext.read.json(path)
// 推导出来的schema,可由printSchema打印出来
people.printSchema()
// root
// |-- age: integer (nullable = true)
// |-- name: string (nullable = true)
// 将DataFrame注册为table
people.registerTempTable("people")
// 跑SQL语句吧!
val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
// 另一种方法是,用一个包含JSON字符串的RDD来创建DataFrame
val anotherPeopleRDD = sc.parallelize(
"""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
val anotherPeople = sqlContext.read.json(anotherPeopleRDD)
2. 连接Hive表
Spark SQL支持从Apache Hive读 写数据。然而,Hive依赖项太多,所以没有把Hive包含在默认的Spark发布包里。要支持Hive,需要在编译spark的时候增加-Phive和 -Phive-thriftserver标志。这样编译打包的时候将会把Hive也包含进来。注意,hive的jar包也必须出现在所有的worker节 点上,访问Hive数据时候会用到(如:使用hive的序列化和反序列化SerDes时)。
Hive配置在conf/目录下hive-site.xml,core-site.xml(安全配置),hdfs-site.xml(HDFS配 置)文件中。请注意,如果在YARN cluster(yarn-cluster mode)模式下执行一个查询的话,lib_mananged/jar/下面的datanucleus 的jar包,和conf/下的hive-site.xml必须在驱动器(driver)和所有执行器(executor)都可用。一种简便的方法是,通过 spark-submit命令的–jars和–file选项来提交这些文件。
如果使用Hive,则必须构建一个HiveContext,HiveContext是派生于SQLContext的,添加了在Hive Metastore里查询表的支持,以及对HiveQL的支持。用户没有现有的Hive部署,也可以创建一个HiveContext。如果没有在 hive-site.xml里配置,那么HiveContext将会自动在当前目录下创建一个metastore_db目录,再根据HiveConf设置 创建一个warehouse目录(默认/user/hive/warehourse)。所以请注意,你必须把/user/hive/warehouse的 写权限赋予启动spark应用程序的用户。
// sc是一个已有的SparkContext对象
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
// 这里用的是HiveQL
sqlContext.sql("FROM src SELECT key, value").collect().foreach(println)
3. 用JDBC连接其他数据库####
Spark SQL也可以用JDBC访问其他数据库。这一功能应该优先于使用JdbcRDD。因为它返回一个DataFrame,而DataFrame在Spark SQL中操作更简单,且更容易和来自其他数据源的数据进行交互关联。JDBC数据源在java和python中用起来也很简单,不需要用户提供额外的 ClassTag。(注意,这与Spark SQL JDBC server不同,Spark SQL JDBC server允许其他应用执行Spark SQL查询)
首先,你需要在spark classpath中包含对应数据库的JDBC driver,下面这行包括了用于访问postgres的数据库driver
SPARK_CLASSPATH=postgresql-9.3-1102-jdbc41.jar bin/spark-shell
val jdbcDF = sqlContext.read.format("jdbc").options(
Map("url" -> "jdbc:postgresql:dbserver",
"dbtable" -> "schema.tablename")).load()
注意:
- JDBC driver class必须在所有client session或者executor上,对java的原生classloader可见。这是因为Java的DriverManager在打开一个连接之 前,会做安全检查,并忽略所有对原声classloader不可见的driver。最简单的一种方法,就是在所有worker节点上修改 compute_classpath.sh,并包含你所需的driver jar包。
- 一些数据库,如H2,会把所有的名字转大写。对于这些数据库,在Spark SQL中必须也使用大写。