【代码研读】Mask RCNN代码阅读笔记(二)骨架网络backbone和入口
前言
笔记分为三个部分,backbone,rpn,roi_head三个部分,之前的该项目总览见【链接】。本文主要是讲解backbone部分的文件,通过在总体把握和实现细节两个方面对其进行记录。
检测的入口
│ │ ├── detector
│ │ │ ├── detectors.py #检测的代码入口
│ │ │ ├── generalized_rcnn.py #生成各种组合的检测模型
进行检测的过程中,首先的代码入口为detectors.py。
detectors.py作用: 根据给定的配置信息实例化一个 class GeneralizedRCNN 的对象。GeneralizedRCNN的构建在文件 generalized_rcnn.py中
generalized_rcnn.py作用:定义了 MaskrcnnBenchmark 的 GeneralizedRCNN 类, 用于表示各种组合后的目标检测模型
- 该类是 MaskrcnnBenchmark 中所有模型的共同抽象, 目前支持 boxes 和 masks 两种形式的标签
- 该类主要包含以下三个部分:
- backbone
- rpn(option)
- heads: 利用前面网络输出的 features 和 proposals 来计算 detections / masks.
骨架网络总体:
│ │ ├── backbone
│ │ │ ├── backbone.py
│ │ │ ├── fpn.py
│ │ │ └── resnet.py
由总体概览知,骨架网络主要分为backbone部分,resnet部分,以及由resnet组成的rpn部分三个主要部分。下面分部分来进行笔记。
backbone
主要作用:将resent和rpn进行调用,并创建对应的组合特征提取网络。
backbone.py 文件中的两个函数 build_resnet_backbone() 和 build_resnet_fpn_backbone() 都使用了 body = resnet.ResNet(cfg) 来创建网络的主体, 这部分的代码定义位于 ./maskrcnn_benchmark/modeling/backbone/resnet.py 文件
resnet
这里实现了50,101层的resnet的代码。
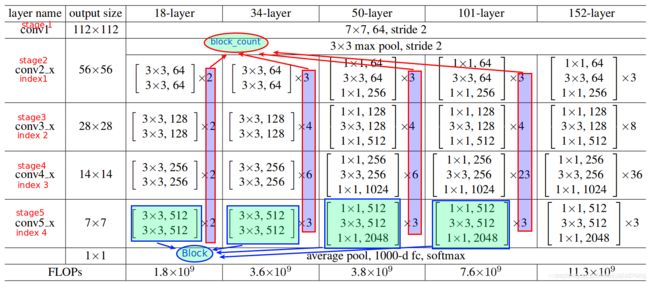
- stem作为stage1被进行创建
- resnet2~5 阶段的整体结构是非常相似的, 都是有最基础的 resnet bottleneck block 堆叠形成的。
在maskrcnn benchmark中,对上面提到的这两种block结构进行的衍生和封装,Bottleneck和Stem分别衍生出带有Batch Normalization 和 Group Normalizetion的封装类,分别为:
- BottleneckWithFixedBatchNorm,
- StemWithFixedBatchNorm
- BottleneckWithGN,
- StemWithGN.
搭建模块层级的核心代码
def _make_stage(
transformation_module,
in_channels,
bottleneck_channels,
out_channels,
block_count,
num_groups,
stride_in_1x1,
first_stride,
dilation=1,
dcn_config={}
):
blocks = []
stride = first_stride
# 根据不同的配置,构造不同的卷基层
for _ in range(block_count):
blocks.append(
transformation_module(
in_channels,
bottleneck_channels,
out_channels,
num_groups,
stride_in_1x1,
stride,
dilation=dilation,
dcn_config=dcn_config
)
)
stride = 1
in_channels = out_channels
return nn.Sequential(*blocks)
resnet核心实现代码
# ./maskrcnn_benchmark/modeling/backbone/resnet.py
class ResNet(nn.Module):
def __init__(self, cfg):
super(ResNet, self).__init__()
# 如果我们希望在 forward 函数中使用 cfg, 那么我们就应该创建一个副本以供其使用
# self.cfg = cfg.clone()
# 将配置文件中的字符串转化成具体的实现, 下面三个分别使用了对应的注册模块, 定义在文件的最后
# 这里是 stem 的实现, 也就是 resnet 的第一阶段 conv1
# cfg.MODEL.RESNETS.STEM_FUNC = "StemWithFixedBatchNorm"
stem_module = _STEM_MODULES[cfg.MODEL.RESNETS.STEM_FUNC]
# resnet conv2_x~conv5_x 的实现
# eg: cfg.MODEL.CONV_BODY="R-50-FPN"
stage_specs = _STAGE_SPECS[cfg.MODEL.CONV_BODY]
# residual transformation function
# cfg.MODEL.RESNETS.TRANS_FUNC="BottleneckWithFixedBatchNorm"
transformation_module = _TRANSFORMATION_MODULES[cfg.MODEL.RESNETS.TRANS_FUNC]
# 获取上面各个组成部分的实现以后, 就可以利用这些实现来构建模型了
# 构建 stem module(也就是 resnet 的stage1, 或者 conv1)
self.stem = stem_module(cfg)
# 获取相应的信息来构建 resnet 的其他 stages 的卷积层
# 当 num_groups=1 时为 ResNet, >1 时 为 ResNeXt
num_groups = cfg.MODEL.RESNETS.NUM_GROUPS
#
width_per_group = cfg.MODEL.RESNETS.WIDTH_PER_GROUP
# in_channels 指的是向后面的第二阶段输入时特征图谱的通道数,
# 也就是 stem 的输出通道数, 默认为 64
in_channels = cfg.MODEL.RESNETS.STEM_OUT_CHANNELS
# 第二阶段输入的特别图谱的通道数
stage2_bottleneck_channels = num_groups * width_per_group
# 第二阶段的输出, resnet 系列标准模型可从 resnet 第二阶段的输出通道数判断后续的通道数
# 默认为256, 则后续分别为512, 1024, 2048, 若为64, 则后续分别为128, 256, 512
stage2_out_channels = cfg.MODEL.RESNETS.RES2_OUT_CHANNELS
# 创建一个空的 stages 列表和对应的特征图谱字典
self.stages = []
self.return_features = {}
for stage_spec in stage_specs: # 关于 stage_specs 的定义可以看上一节
name = "layer" + str(stage_spec.index)
# 计算每个stage的输出通道数, 每经过一个stage, 通道数都会加倍
stage2_relative_factor = 2 ** (stage_spec.index - 1)
# 计算输入图谱的通道数
bottleneck_channels = stage2_bottleneck_channels * stage2_relative_factor
# 计算输出图谱的通道数
out_channels = stage2_out_channels * stage2_relative_factor
# 当获取到所有需要的参数以后, 调用本文件的 `_make_stage` 函数,
# 该函数可以根据传入的参数创建对应 stage 的模块(注意是module而不是model)
module = _make_stage(
transformation_module,
in_channels, # 输入的通道数
bottleneck_channels, # 压缩后的通道数
out_channels, # 输出的通道数
stage_spec.block_count, #当前stage的卷积层数量
num_groups, # ResNet时为1, ResNeXt时>1
cfg.MODEL.RESNETS.STRIDE_IN_1X1,
# 当处于 stage3~5时, 需要在开始的时候使用 stride=2 来downsize
first_stride=int(stage_spec.index > 1) + 1,
)
# 下一个 stage 的输入通道数即为当前 stage 的输出通道数
in_channels = out_channels
# 将当前stage模块添加到模型中
self.add_module(name, module)
# 将stage的名称添加到列表中
self.stages.append(name)
# 将stage的布尔值添加到字典中
self.return_features[name] = stage_spec.return_features
# 根据配置文件的参数选择性的冻结某些层(requires_grad=False)
self._freeze_backbone(cfg.MODEL.BACKBONE.FREEZE_CONV_BODY_AT)
def _freeze_backbone(self, freeze_at):
# 根据给定的参数冻结某些层的参数更新
for stage_index in range(freeze_at):
if stage_index == 0:
m = self.stem # resnet 的第一阶段, 即为 stem
else:
m = getattr(self, "layer" + str(stage_index))
# 将 m 中的所有参数置为不更新状态.
for p in m.parameters():
p.requires_grad = False
# 定义 ResNet 的前行传播过程
def forward(self, x):
outputs = []
x = self.stem(x) # 先经过 stem(stage 1)
# 再依次计算 stage2~5的结果
for stage_name in self.stages:
x = getattr(self, stage_name)(x)
if self.return_features[stage_name]:
# 将stage2~5的所有计算结果(也就是特征图谱)以列表形式保存
outputs.append(x)
# 将结果返回, outputs为列表形式, 元素为各个stage的特征图谱, 刚好作为 FPN 的输入
return outputs
FPN
我们将通过resnet搭建对应的FPN网路模型,FPN网络主要应用于多层特征提取,使用多尺度的特征层来进行目标检测,可以利用不同的特征层对于不同大小特征的敏感度不同,将他们充分利用起来,以更有利于目标检测
这里直接利用了上面resnet的类,并在此基础上进行搭建,主要流程为定义11卷积改变通道数,定义33卷积进行特征图提取。在进行前向计算阶段,进行缩小2倍的特征并进行直接的相加。将这个作为下一个阶段的输入。
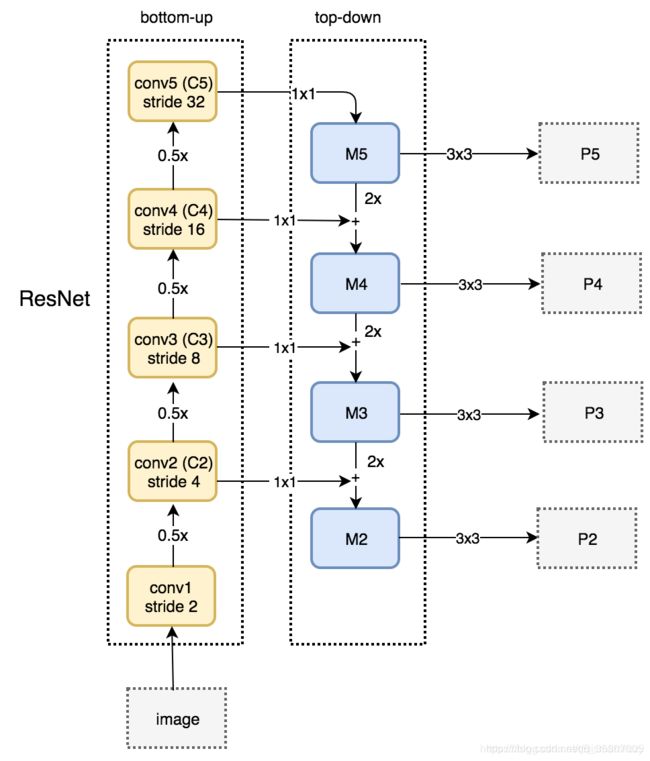
resnet+FPN的实例图
核心实现代码
# ./maskrcnn_benchmark/modeling/backbone/fpn.py
import torch
import torch.nn.functional as F
from torch import nn
class FPN(nn.Module):
# 在一系列的 feature map (实际上就是stage2~5的最后一层输出)添加 FPN
# 这些 feature maps 的 depth 假定是不断递增的, 并且 feature maps 必须是连续的(从stage角度)
def __init__(self, in_channels_list, out_channels, top_blocks=None):
# in_channels_list (list[int]): 指示了送入 fpn 的每个 feature map 的通道数
# out_channels (int): FPN表征的通道数, 所有的特征图谱最终都会转换成这个通道数大小
# top_blocks (nn.Module or None): 当提供了 top_blocks 时, 就会在 FPN 的最后
# 的输出上进行一个额外的 op, 然后 result 会扩展成 result list 返回
super(FPN, self).__init__()
# 创建两个空列表
self.inner_blocks = []
self.layer_blocks = []
# 假设我们使用的是 ResNet-50-FPN 和配置, 则 in_channels_list 的值为:
# [256, 512, 1024, 2048]
for idx, in_channels in enumerate(in_channels_list, 1): # 下标从1开始
# 用下表起名: fpn_inner1, fpn_inner2, fpn_inner3, fpn_inner4
inner_block = "fpn_inner{}".format(idx)
# fpn_layer1, fpn_layer2, fpn_layer3, fpn_layer4
layer_block = "fpn_layer{}".format(idx)
# 创建 inner_block 模块, 这里 in_channels 为各个stage输出的通道数
# out_channels 为 256, 定义在用户配置文件中
# 这里的卷积核大小为1, 该卷积层主要作用为改变通道数到 out_channels(降维)
inner_block_module = nn.Conv2d(in_channels, out_channels, 1)
# 改变 channels 后, 在每一个 stage 的特征图谱上再进行 3×3 的卷积计算, 通道数不变
layer_block_module = nn.Conv2d(out_channels, out_channels, 3, 1, 1)
for module in [inner_block_module, layer_block_module]:
# Caffe2 的实现使用了 XavierFill,
# 实际上相当于 PyTorch 中的 kaiming_uniform_
nn.init.kaiming_uniform_(module.weight, a=1)
nn.init.constant_(module.bias, 0)
# 在当前的特征图谱上添加 FPN
self.add_module(inner_block, inner_block_module) #name, module
self.add_module(layer_block, layer_block_module)
# 将当前 stage 的 fpn 模块的名字添加到对应的列表当中
self.inner_blocks.append(inner_block)
self.layer_blocks.append(layer_block)
# 将top_blocks作为 FPN 类的成员变量
self.top_blocks = top_blocks
def forward(self, x):
# x (list[Tensor]): 每个 feature level 的 feature maps,
# ResNet的计算结果正好满足 FPN 的输入要求, 也因此可以使用 nn.Sequential 将二者直接结合
# results (tuple[Tensor]): 经过FPN后的特征图谱组成的列表, 排列顺序是高分辨率的在前
# 先计算最后一层(分辨率最低)特征图谱的fpn结果.
last_inner = getattr(self, self.inner_blocks[-1])(x[-1])
# 创建一个空的结果列表
results=[]
# 将最后一层的计算结果添加到 results 中
results.append(getattr(self, self.layer_blocks[-1])(last_inner))
# [:-1] 获取了前三项, [::-1] 代表从头到尾切片, 步长为-1, 效果为列表逆置
# 举例来说, zip里的操作 self.inner_block[:-1][::-1] 的运行结果为
# [fpn_inner3, fpn_inner2, fpn_inner1], 相当于对列表进行了逆置
for feature, inner_block, layer_block in zip(
x[:-1][::-1], self.inner_block[:-1][::-1], self.layer_blocks[:-1][::-1]
):
# 根据给定的scale参数对特征图谱进行放大/缩小, 这里scale=2, 所以是放大
inner_top_down = F.interpolate(last_inner, scale_factor=2, mode="nearest")
# 获取 inner_block 的计算结果
inner_lateral = getattr(self, inner_block)(feature)
# 将二者叠加, 作为当前stage的输出 同时作为下一个stage的输入
last_inner = inner_lateral + inner_top_down
# 将当前stage输出添加到结果列表中, 注意还要用 layer_block 执行卷积计算
# 同时为了使得分辨率最大的在前, 我们需要将结果插入到0位置
results.insert(0, getattr(self, layer_block)(last_inner))
# 如果 top_blocks 不为空, 则执行这些额外op
if self.top_blocks is not None:
last_results = self.top_blocks(results[-1])
results.extend(last_results) # 将新计算的结果追加到列表中
# 以元组(只读)形式返回
return tuple(results)
# 最后一级的 max pool 层
class LastLevelMaxPool(nn.Module):
def forward(self, x):
return [F.max_pool2d(x, 1, 2, 0)]
参考链接:
【地址1 resnet.py】
【地址2 rpn.py】
【地址3 backbone.py】
【地址2个人主页】
(文中的ROI_HEAD部分并没有进行注解)