kettle抽取——多平台汇总数据仓库
kettle版本:6.0
jdk:1.7(注意:经多次实验,6.0必须用jdk1.7,5.x的可以使用1.6jdk)
系统:64位 windows7 旗舰版
配置:内存(8G),处理器(i5-4590 CPU 3.30GHz)
一、需求简介
1.多个平台数据汇总到数据仓库,最后的所有表在数据仓库是完备的
注意点:
a.平台1和平台2各有1200和1100张表,其中1000张表在两个平台都有,另外平台1的200张表和平台2的100张表示各自拥有的,那么数据仓库就会有1300张表,其中1000张共有表抽取到数据仓库的时候由于有平台值主键不会发生冲突
b.汇总后数据仓库里的表名会有所改变,会有三种形式:依旧是原表名、原表名+后缀1、原表名+后缀2
2.汇总表的同时每条记录都要记录日志表,日志表有两个,一个为记录成功或失败记录,一个为分配已成功抽取的表进行数据清洗、对比、转换等数据处理
名词设定:需要抽取的表称为基础表,记录成功或失败记录的表称为历史表,分配任务的表称为清洗表,下文皆同
二、思路简介
正常思路:从数据仓库中拿出所有表并设置变量,然后获取变量值再从各个平台分别抽取这些表,抽取之前剔除不存在的表;抽取一条记录成功或失败都记录到历史表中,最后从历史表中拿出数据并转换、判断插入清洗表
但这里存在难点:由于kettle的限制,你不能一条数据一条数据的来,只能一堆数据一堆数据的来,所以抽取一条基本表就记录一条历史表这个是实现不了的
所以思路进行调整,抽取完基本表,如果抽取成功,就从基本表里全部拿出数据并记录到历史表且标记为“成功”;如果抽取失败,则跳出这个表的抽取程序,并记录一条失败的记录到历史表,这样的话就能实现需求的功能,只不过失败的表需要重新抽取整个表,而不是跳过失败的那条记录然后继续抽取其它的数据
三、流程概览
整个抽取流程包括2个job和7个transform
总作业
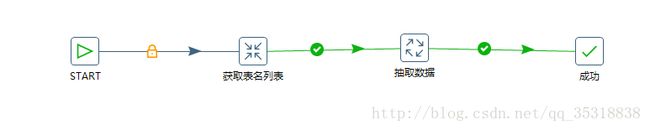
抽取数据作业

这两个作业大体显示了整个抽取的流程
从变量的设置、获取,到数据的剔除、清洗、抽取、记录日志等
四、细节整理
1.总作业
总作业的图我已经放在(三)中了,包裹一个transform和一个job,获取表名列表是从数据仓库中获取要抽取的表名列表,抽取数据作业是具体的数据转换、清洗、抽取过程
2.获取表名列表
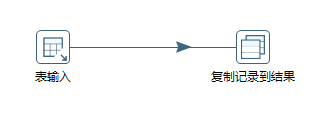
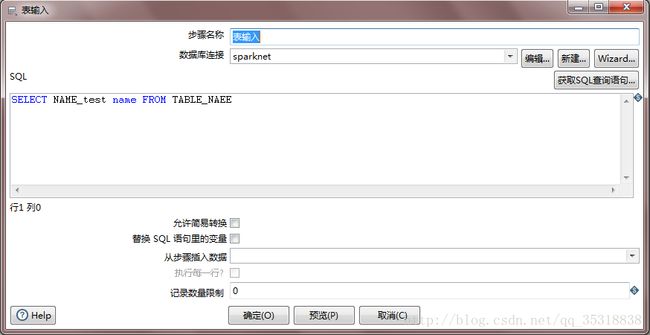
我是将需要抽取的表分成三部分:表名不变的,表名+后缀1,表名+后缀2,并分别存在TABLE_NAEE这个表中,因为这三种情况是分别配置的,所以配置哪个就使用TABLE_NAEE表的相关列就行了
表输入:
复制记录到结果,这一步的目的是将表名列表放入一个集合并可以传递到下一个流程,方便获取,同时还能实现循环输入
3.抽取数据
抽取数据的图已经放在(三)中了,这步就是这个抽取的核心了,也就是需要循环的地方,循环的设置看下图
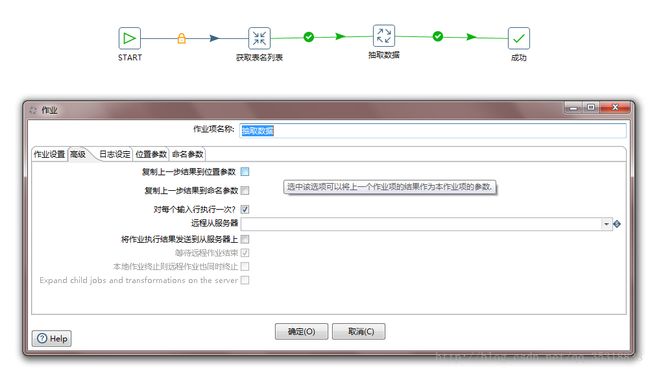
4.设置表名变量
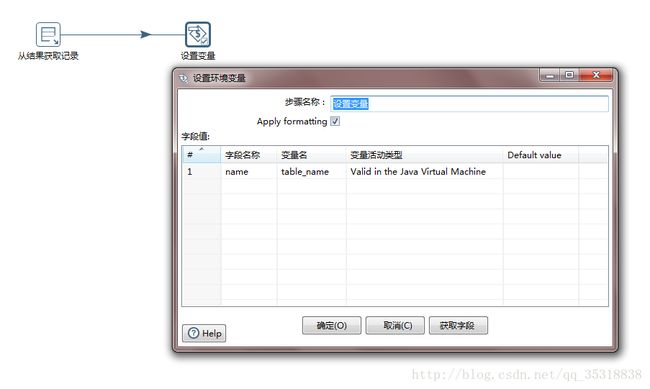
首先从上一步的结果中获取记录,注意它是从上面的一列表名中一个一个的获取,而不是所有的拿过来,所以才能实现循环,然后将拿到的表名设置为变量,方便下面表输入和表输出的使用
5.计算表中的记录数、表不存在或表中没有数据
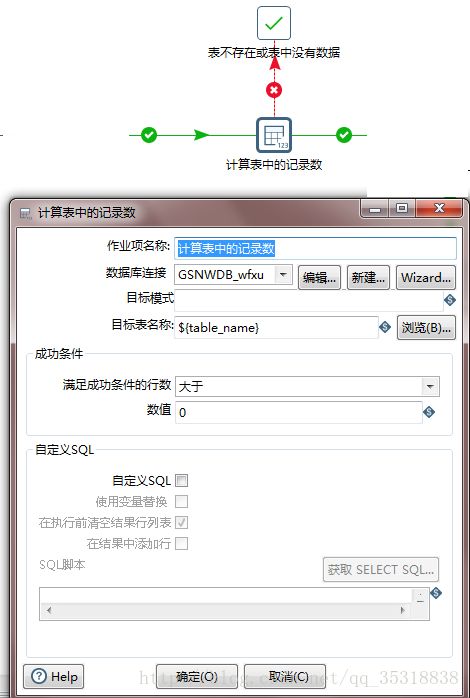
在原平台中查询出该表的总数,好比select count(*) from table ,如果count大于0就继续进行下一步,如果不是大于0(也就表示这个表不存在或者表中没有数据)就会指向“表不存或表中没有数据步骤”,跳过后面步骤,进行下一个循环。
这一步的目的就是过滤掉那些平台没有的表或表中没有数据的表,只进行有必要抽取的表
6.获取PRIMARY_VALUE,设置org
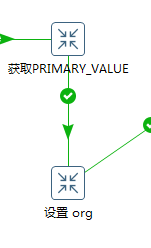
上面这两步,没有什么可借鉴的,因项目的不同而不同
获取PRIMARY_VALUE是获取每个表的主键值并放在一个字段里,这个是通过语句获取的
设置org也是通过语句获取的,就是每个平台对应的平台值,用于区分平台
7.抽取基本表
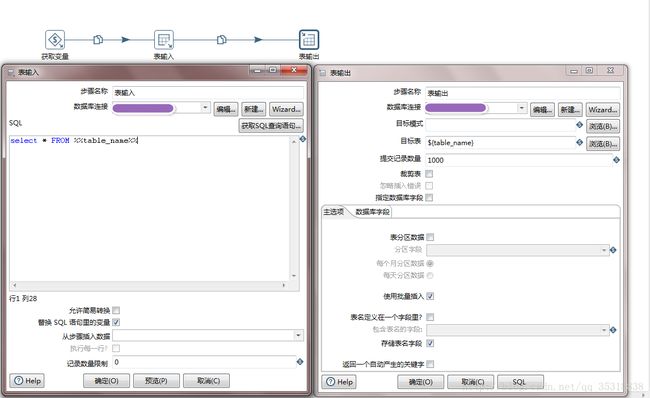
抽取基本表主要就是三步,获取表名,表输入,表输出。
需要注意的是表名用的都是变量,而且表输出的表名是根据你选择的不同而不同
a.如果你选择的是平台表名和数据仓库表名一样的,那就是” tablename”b.如果你选择的是+后缀名的,那就是“ {table_name}”后面加上后缀名,比如在表输出的目标表里直接填上“${table_name}_1”
而且如果这一步出现了错误,比如字段过大,唯一性错误,就会停止抽取这个表并指向“失败 新增history”
8.新增历史表
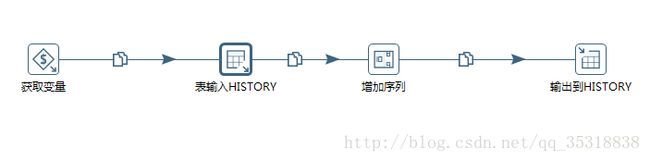
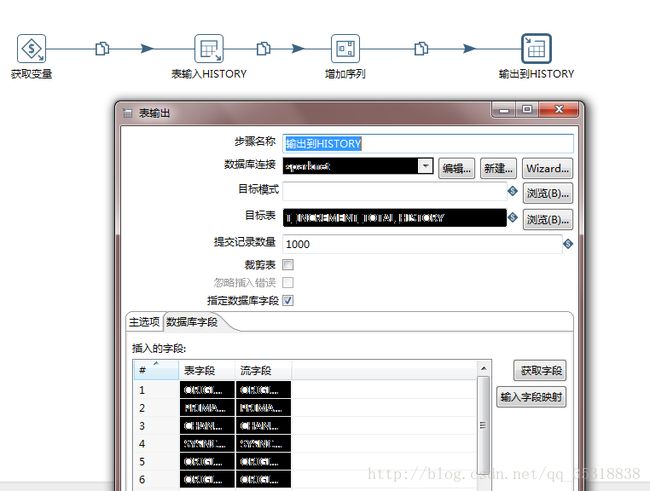
由于是细节问题,我就不方便展示了,大体的流程就是获取变量(包括表名变量,主键值),表输入(查询基本表并且通过判断字段、拼接字段、获取系统时间等得到历史表需要的字段),增加序列(这一步是提出序列号作为每条记录的主键),输出到历史表(由于有多变量传入,并且只是使用变量的转换值,所以需要勾上指定数据库字段并且将各个字段对应上,见下图)
如果是基本表抽取失败后新增历史表,跟上面这个历史表的流程是一样的,只不过在表输入的时候只需要将表名,出入即可,其它的字段可以设为默认值比如空值,而且只需要插入一条记录就可以了(你只需要一条记录就可以知道这个表抽取失败了,而不是像成功抽取一样几下每条抽取成功的信息)
9.新增清洗表

到这一步就比较简单了,获取变量、表输入、表输出就可以。核心就在表输入,从历史表中获取数据并加入条件判断将数据合理分配给某个清洗服务器就可以了,可以使用平均表数量的分配方法,也可以使用固定平台对应固定清洗服务器的方法(推荐),还可以使用随机抽取的方法(当然不推荐这个)
以上就是抽取的整个流程和细节,因为涉及到项目的一些信息,所以后面只是给出了流程和思路,并没有将每个转换里的内容都呈现出来,如果有朋友遇到类似的问题需要像我上面那样去解决,可以留言给我,大家一起讨论讨论,而不是想我这样连续通宵搞
五、项目总结
由于这个需求来得很快很急,所以是通宵搞的,而需要通宵搞得原因有几个,整理如下,希望大家可以借鉴避免入坑:
1.明确需求,最好有份比较清晰详细的需求分析说明书(针对这次需求的)
我接到这个需求的时候是项目经理直接来找我,让我“试试看”,然后就大体的介绍了数据的抽取情况,大体到什么程度呢,就是文章开头的需求简介,不过没有这么精简罢了。然后遇到什么问题我看出来了,我就去问需求和经理,但是没有看出来的问题就操蛋了,直接报错到我的流程里,调试了半天才发现是需求没有说清楚,漏了一些问题产生bug,最后的最后,即使到了现场,需求也没有把所有的细节都告诉我,到了现场我还要调整流程。为了这些“不清楚”我花费了太多的时间和经历,所以首先是要明确需求,最好有份文档(因为人总有遗漏的地方,有忘问的,有忘答的,只要有一方没有说清楚或问清楚,出了问题还得你来解决,耽误真个流程的编写和测试)
2.测试
测试,测试,测试,重要的事情说三遍。我们公司的人天天抱怨测试,但是测试是必须的而且很重要。自测和测试人员测试都有必要,这次因为没有时间所以没有走测试人员测试,有些问题到了现场才发现,又是一笔时间,而且现场数据不可以乱动,你也不好调试
3.了解每个组件
了解每个组件的使用功能和使用环境,不要到了做的时候再一个一个试,伤不起。
感谢大家的阅读,如果有什么关于交流的方式或途径、文档、群体,可以在下方留言,人多好办事,一个人解决不了的就让一百个人来解决,总能解决的。同时欢迎大家提出文章的错处和可优化处!