使用hive做单词统计
方法一(分步查询):
1、首先创建一个文件单词的文件,例如a.txt
kk,123,weiwei,123
hlooe,hadoop,hello,ok
h,kk,123,weiwei,ok
ok,h2、将文件上传到hdfs中
hdfs dfs -copyFromLocal ./a.txt /upload/wangwei/a.txt3、在hive中创建一个textline的表
create table textlines(text string);4、在hive中创建一个words表
create table words(word string);5、加载数据到textline中
load data inpath '/upload/wangwei/a.txt' into table textline;6、将textlines中的数据拆分根据','号拆分为单词,然后存入words表中
insert overwrite table words select explode(split(text,',')) as word from textline;7、进行单词统计
select word, count(*) from words group by word;
20180621更新
方法二(使用sql子查询语句一条语句搞定):
1、首先将textline表中的数据炸裂开
select explode(split(text,',')) from textline;
2、将上面的结果as表t,然后对表t进行单词统计
select t.word,count(*) from((select explode(split(text,',')) as word from textline) as t)group by t.word;
3、按照统计出来的单词的顺序,从大到小排列,取前面三个值。对上面的count(*)进行排序
select t.word,count(*) as c from((select explode(split(text,',')) as word from textline) as t)group by t.word order by c desc limit 3;
4、将统计出来的结果放在hive表中
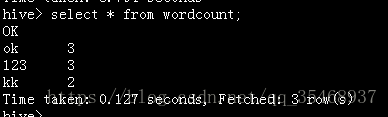
create table wordcount as select t.word,count(*) as c from((select explode(split(text,',')) as word from textline) as t)group by t.word order by c desc limit 3;
select * from wordcount;