Faster-RCNN论文原理理解
从RCNN,SPPNET,Fast-RCNN,到Faster-RCNN,实现了端到端网络框架(rg和何凯明从互怼到合作)。
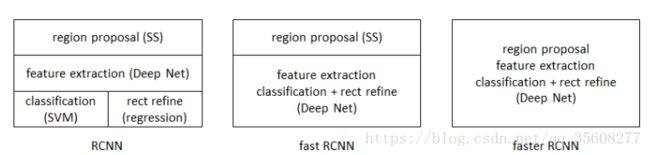
faster RCNN可以简单地看做“区域生成网络(RPN)+fast RCNN“的系统,用区域生成网络代替fast RCNN中的Selective Search(SS)方法。
本篇论文着重解决了这个系统中的三个问题:
1. 如何设计区域生成网络
2. 如何训练区域生成网络
3. 如何让区域生成网络和fast RCNN网络共享特征提取网络
整个过程:

1.Conv layers。作为一种CNN网络目标检测方法,Faster R-CNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
2.Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals。
3.Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
4.Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
候选区域(anchor)
特征可以看做一个尺度51*39的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:
三种面积{128^2,256^2,512^2}×三种比例{1:1,1:2,2:1}。
所以这样计算,最小的anchor三种尺寸为:128*128;181*91;91*181.
这些候选窗口称为anchors。
根据图像大小计算滑窗中心点对应原图区域的中心点,通过中心点和size就可以得到滑窗位置和原图位置的映射关系,由此原图位置并根据与Ground Truth重复率贴上正负标签,让RPN学习该Anchors是否有物体即可。
下图示出51*39个anchor中心,以及9种anchor示例。

对论文中使用的ZFnet,输入图像尺寸600*800;conv5输出的特征图尺寸为50*38*256,也就是每个点的维度是256维。
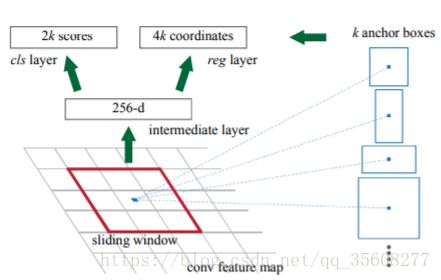
假设特征图每个点有k个anchor(k=9),而每个anhcor要分目标foreground和背景background,所以cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates
RPN
从特征图再经过n=3的3*3感受野进行卷积.然后通过1*1卷积输出分为两路,其中一路输出是目标和非目标的概率,另一路输出box相关的四个参数,包括box的中心坐标x和y,box宽w和长h。

整个过程
生成anchors -> softmax分类器提取fg anchors -> bbox reg回归fg anchors -> Proposal Layer生成proposals。
前传过程:
1 生成anchors,利用[d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A)]对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
2 按照输入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的foreground anchors。
3 限定超出图像边界的foreground anchors为图像边界(防止后续roi pooling时proposal超出图像边界)
4 剔除非常小的foreground anchors
5 进行nonmaximum suppression
6 再次按照nms后的foreground softmax scores由大到小排序fg anchors,提取前post_nms_topN(e.g. 300)结果作为proposal输出。
随后就是Fast-RCNN:
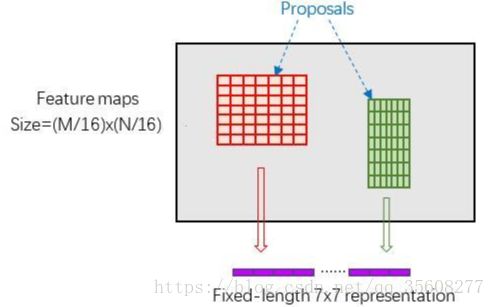
RoI pooling
借鉴的SPP,fast-RCNN。
RPN网络生成的proposals的方法:对foreground anchors进行bounding box regression,那么这样获得的proposals也是大小形状各不相同,使得经过POI POOling后输出的图像尺寸是固定值( pooled_w=pooled_h=7,为7*7)。
分类回归
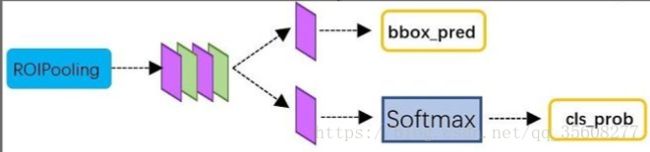
1 通过全连接和softmax对proposals进行分类识别。
2 再次对proposals进行bounding box regression,获取更高精度的rect box
整个Faster-RCNN网络训练
分段训练的过程,RPN和Fast-RCNN
1.在已经训练好的model上,训练RPN网络,对应stage1_rpn_train.pt
2.利用步骤1中训练好的RPN网络,收集proposals,对应rpn_test.pt
3.第一次训练Fast RCNN网络,对应stage1_fast_rcnn_train.pt
4.第二训练RPN网络,对应stage2_rpn_train.pt
5.再次利用步骤4中训练好的RPN网络,收集proposals,对应rpn_test.pt
6.第二次训练Fast RCNN网络,对应stage2_fast_rcnn_train.pt
RPN训练
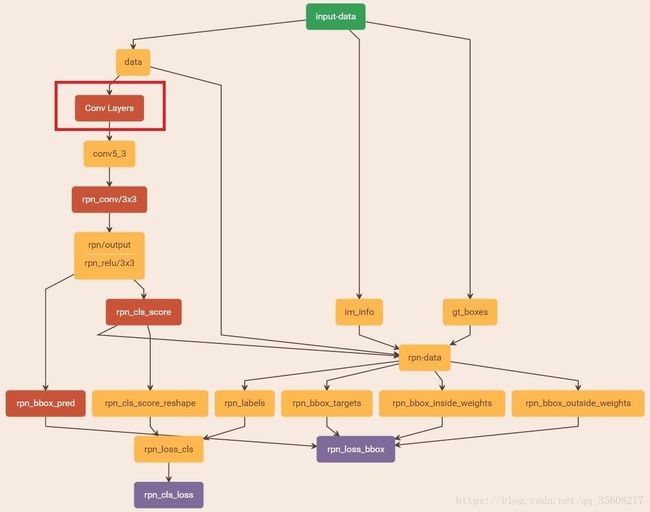
1 正负样本选择
我们分配正标签给两类anchor:(i)与某个ground truth(GT)包围盒有最高的IoU(Intersection-over-Union,交集并集之比)重叠的anchor(也许不到0.7),(ii)与任意GT包围盒有大于0.7的IoU交叠的anchor。注意到一个GT包围盒可能分配正标签给多个anchor。我们分配负标签给与所有GT包围盒的IoU比率都低于0.3的anchor。非正非负的anchor对训练目标没有任何作用。
2.损失函数
i是一个mini-batch中anchor的索引,Pi是anchor i是目标的预测概率,cls层和reg层的输出分别由{pi}和{ti}组成,这两项分别由Ncls和Nreg以及一个平衡权重λ归一化(早期实现及公开的代码中,λ=10,cls项的归一化值为mini-batch的大小,即Ncls=256,reg项的归一化值为anchor位置的数量,即Nreg~2,400,这样cls和reg项差不多是等权重的。

![]()
REF:https://zhuanlan.zhihu.com/p/31426458赞!
https://github.com/facebookresearch/Detectron