pytorch学习笔记(六)
pytorch学习笔记(六)
1.前言
这次我们来学习数据加载和处理,解决任何ml的问题的很多努力都在准备数据,而pytorch提供了很多工具来使数据加载变得简单并使我们的代码可读性增强,这次我们来看看怎样从数据集中加载和预处理数据
首先我们要保证自己装了scikit-image和pandas两个工具包,大家可以在anaconda里面看看自己装了没,没有就装一下
另外我们还需下载一个图像集放在我们创建的代码文件目录下
2.正文
2.1前期准备工作
老样子,载入库文件和初始任务并展示一些图像
from __future__ import print_function,division
import os
import torch
import pandas as pd
from skimage import io,transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms,utils
import warnings
warnings.filterwarnings("ignore")
plt.ion()
这里简单说一下plt.ion()的功能,python可视化库matplotlib有两种显示模式:
- 阻塞(block)模式
- 交互(interactive)模式
在Python Consol命令行中,默认是交互模式。而在python脚本中,matplotlib默认是阻塞模式。
在交互模式下:
- plt.plot(x)或plt.imshow(x)是直接出图像,不需要plt.show()
- 如果在脚本中使用ion()命令开启了交互模式,没有使用ioff()关闭的话,则图像会一闪而过,并不会常留。要想防止这种情况,需要在plt.show()之前加上ioff()命令。
在阻塞模式下:
- 打开一个窗口以后必须关掉才能打开下一个新的窗口。这种情况下,默认是不能像Matlab一样同时开很多窗口进行对比的。
- plt.plot(x)或plt.imshow(x)是直接出图像,需要plt.show()后才能显示图像
而ion函数功能就是打开交互模式,这样可以同时打开多个窗口显示图片
landmarks_frame = pd.read_csv('faces/face_landmarks.csv')
n = 65
img_name = landmarks_frame.iloc[n,0]
landmarks = landmarks_frame.iloc[n,1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1,2)
print('Image name:{}'.format(img_name))
print('Landmarks shape:{}'.format(landmarks.shape))
print('First 4 landmarks:{}'.format(landmarks[:4]))
这里iloc是pandas库里面提取数据的一个函数,i代表integer表示要按照索引去提取数据,区别于loc,这里首先提取了图片名字,然后提取其余参数并按我们的需求来重构数组
Image name:person-7.jpg
Landmarks shape:(68, 2)
First 4 landmarks:[[32. 65.]
[33. 76.]
[34. 86.]
[34. 97.]]
def show_landmarks(image,landmarks):
plt.imshow(image)
plt.scatter(landmarks[:,0],landmarks[:,1],s=10,marker='.',c='r')
plt.pause(0.001)
plt.figure()
show_landmarks(io.imread(os.path.join('faces/',img_name)),landmarks)
plt.show()
plt.scatter就是画散点图,这里用它画出了人脸的轮廓

蛮恐怖的其实,可以换个颜色试试

好点了(后边我又改成了绿色)
2.2数据集类
torch.utils.data.Dataset是表示数据集的抽象类,我们自定义的数据集应该要继承Dataset并有下面两个功能:
- __len__ 用来返回数据集的大小
- __getitem__ 用来获取dataset[i]的i样本
接下来我们为面部标记建立一个数据集,我们采用字典形式作为数据集样本
class FaceLandmarksDataset(Dataset):
def __init__(self,csv_file,root_dir,transform=None):
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self,idx):
img_name = os.path.join(self.root_dir,self.landmarks_frame.iloc[idx,0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx,1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1,2)
sample = {'image':image,'landmarks':landmarks}
if self.transform:
sample = self.transform(sample)
return sample
我们随便写写来看看这个函数运行的结果
face_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',root_dir='faces/')
fig = plt.figure()
for i in range(len(face_dataset)):
sample = face_dataset[i]
print(i,sample['image'].shape,sample['landmarks'].shape)
ax = plt.subplot(1,4,i+1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample)
if i==3:
plt.show()
break
结果:


2.3图像变换
我们从上面的图可以看出样本的大小是有所区别的,所以我们来定义一些类让它们来预处理图像
- Rescale:缩放图像
- RandomCrop:随机裁剪
- ToTensor:数据类型转换
class Rescale(object):
def __init__(self,output_size):
assert isinstance(output_size,(int,tuple))
self.output_size = output_size
def __call__(self,sample):
image,landmarks = sample['image'],sample['landmarks']
h,w = image.shape[:2]
if isinstance(self.output_size,int):
if h>w:
new_h,new_w = self.output_size*h/w,self.output_size
else:
new_h,new_w = self.output_size,self.output_size*w/h
else:
new_h,new_w = self.output_size
new_h,new_w = int(new_h),int(new_w)
img = transform.resize(image,(new_h,new_w))
landmarks = landmarks*[new_w/w,new_h/h]
return {'image':img,'landmarks':landmarks}
class RandomCrop(object):
def __init__(self,output_size):
assert isinstance(output_size,(int,tuple))
if isinstance(output_size,int):
self.output_size = (output_size,output_size)
else:
assert len(output_size)==2
self.output_size = output_size
def __call__(self,sample):
image,landmarks = sample['image'],sample['landmarks']
h,w = image.shape[:2]
new_h,new_w = self.output_size
top = np.random.randint(0,h-new_h)
left = np.random.randint(0,w-new_w)
image = image[top:top+new_h,left:left+new_w]
landmarks = landmarks-[left,top]
return {'image':image,'landmarks':landmarks}
class ToTensor(object):
def __call__(self,sample):
image,landmarks = sample['image'],sample['landmarks']
image = image.transpose((2,0,1))
return {'image':torch.from_numpy(image),'landmarks':torch.from_numpy(landmarks)}
这里面就是做一些图像变换的运算w,h就是宽和高
现在我们来实例化看看,我们想把一个图像缩放到256,然后从中随机裁剪一个224大小的正方形,这里我们就要用到之前说过的Compose函数,这个相当于把函数嵌套:
scale = Rescale(256)
crop = RandomCrop(128)
composed = transforms.Compose([Rescale(256),RandomCrop(224)])
fig = plt.figure()
sample = face_dataset[65]
for i,tsfrm in enumerate([scale,crop,composed]):
transformed_sample = tsfrm(sample)
ax = plt.subplot(1,3,i+1)
plt.tight_layout()
ax.set_title(type(tsfrm).__name__)
show_landmarks(**transformed_sample)
plt.show()
可以看到前面是分别缩放到256和裁剪一个128,后面是做一个嵌套
看看输出:

2.4迭代数据集
我们接下来把它们放在一起,而且要达到以下目的:
- 实时读取图像
- 对读取的图像实时变换
- 由于一个变换是随机的,在采样时会增加数据
transformed_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',
root_dir='faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample = transformed_dataset[i]
print(i,sample['image'].size(),sample['landmarks'].size())
if i==3:
break
但是这样的简单循环我们无法实现很多功能,例如:
- 批量处理数据集
- 重洗数据
torch.utils.data.Dataset可以提供这些功能
dataloader = DataLoader(transformed_dataset,batch_size=4,
shuffle=True,num_workers=4)
def show_landmarks_batch(sample_batched):
images_batch,landmarks_batch=\
sample_batched['image'],sample_batched['landmarks']
batch_size = len(images_batch)
im_size = images_batch.size(2)
grid = utils.make_grid(images_batch)
plt.imshow(grid.numpy().transpose((1,2,0)))
for i in range(batch_size):
plt.scatter(landmarks_batch[i,:,0].numpy()+i*im_size,
landmarks_batch[i,:,1].numpy(),
s=10,marker='.',c='g')
plt.title('Batch from dataloader')
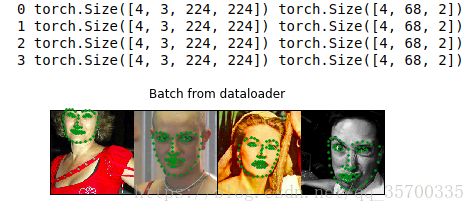
for i_batch,sample_batched in enumerate(dataloader):
print(i_batch,sample_batched['image'].size(),
sample_batched['landmarks'].size())
if i_batch==3:
plt.figure()
show_landmarks_batch(sample_batched)
plt.axis('off')
plt.ioff()
plt.show()
break
里面的代码也都比较基础
输出:
3 小结
这次学习数据加载以及预处理主要是通过图像面部标记来作为例子讲解,就是要考虑多种情况,比如图像的缩放裁剪等,其实比较简单,没涉及什么无法理解的东西,我们下次再见