从零开始java数据库SQL优化(二):多个LEFT JOIN的SQL优化
一:场景
我代码里需要在用户登录时将所有用户相关的用户,角色,部门,岗位,权限(其中权限放在菜单中,每2张表有一张关联表),不多说直接上SQL
SELECT
a.fk_user_id AS "fk_user_id",
a.user_realname AS "user_realname",
a.user_name AS "user_name",
a.user_type AS "user_type",
a.sex AS "sex",
a.phone AS "phone",
a.password AS "password",
a.user_addr AS "user_addr",
a.avater AS "avater",
a.status AS "status",
fr.role_id as role_id,
fr.role_code as role_code,
fr.role_name as role_name,
fr.role_range as role_range,
fd.dept_id as dept_id,
fd.dept_name as dept_name,
fd.parent_id as dept_parent,
fd.parent_ids as dept_parents,
fd.company_name as company_name,
fp.post_id as post_id,
fp.post_name as post_name,
fp.post_split as post_split,
m.perms as perms
FROM fk_user a
LEFT JOIN fk_user_role fkur ON fkur.user_id = a.fk_user_id
LEFT JOIN fk_role fr ON fr.role_id = fkur.role_id
LEFT JOIN fk_role_menu rm ON rm.role_id = fr.role_id
LEFT JOIN fk_menu m ON m.menu_id = rm.menu_id
LEFT JOIN fk_dept fd ON fd.dept_id = a.dept_id
LEFT JOIN fk_user_post fup ON fup.user_id = a.fk_user_id
LEFT JOIN fk_post fp ON fp.post_id = fup.post_id
WHERE a.user_name ='admin'耗时:![]()
二:优化索引
1. 用户表优化
(1)用户表添加唯一索引
由于用户名在程序中控制为唯一,因此用户名创建唯一索引。(TIPS: 由于我程序使用的框架原因,登录先更具用户
名查出用户信息再比对密码。如果是用户名和密码一起查询,则可以在密码字段添加一个普通索引。)

(2)查询语句添加limit 1
至于原因,理由放在这篇从零开始java数据库SQL优化(番外):SQL执行性能分析

(3)优化结果:
![]() 用户表 Type级别已经达到效率最高了。
用户表 Type级别已经达到效率最高了。
查询一下计划: 
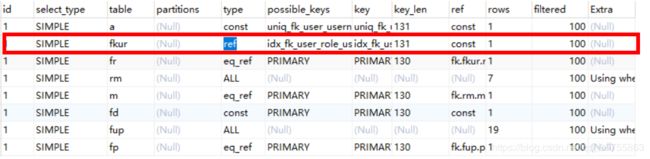
2. 优化用户角色表
上图可以看出来fkur(即用户角色表)的类型还是ALL,这里我们对这张表做一个优化。
(1)用户角色添加组合索引

(2)优化结果
![]() ,数据较少效果不明显,但是由查询计划看到Type
,数据较少效果不明显,但是由查询计划看到Type
3.优化角色菜单表
(1)添加组合索引

(2)优化结果
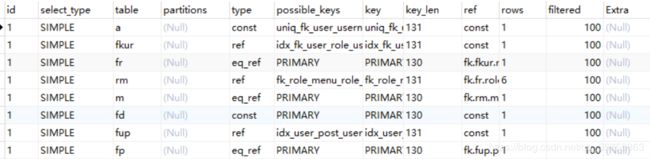
![]() 效果不明显,但是看一下查询计划的Type
效果不明显,但是看一下查询计划的Type

4.优化用户部门表
(1)添加索引

(2)优化结果
![]() 看一下查询计划,它的类型还是ALL(这里有个坑,如果数据过少,查询会自动判断走索引还是全表,因此表中数据要 > 2*查询出的数据索引才能有效果)
看一下查询计划,它的类型还是ALL(这里有个坑,如果数据过少,查询会自动判断走索引还是全表,因此表中数据要 > 2*查询出的数据索引才能有效果)

5.总结
到这里索引的添加就完成了,主要就是添加唯一索引和普通索引的问题。
三:多LEFT JOIN的SQL优化
目前,在阿里Java开发的规范手册上明确提到Left join表,最多不得超过3个。很尬尴的是在我们本例中后台采用的是Security的安全权限框架。至少需要将,用户、角色以及权限查询出来放入缓存以做权限检验。其次,由于数据权限,还需要将用户的部门,岗位查询出来,基本上表是没法少的。因此,才出现上面的优先添加索引的这个方法。但是这里我们提供一些优化多个Left Join的思路吧。
(1)Left Join查询的方式
顾名思义,Left join当然是以左边表作为查询条件,有以下几个特点:
第一点:左表为基准,右表做为关联,查不到返回NULL。比如说 User Left Join Dept。User有10条数据,Dept只有5条数据
那么查询出来的一定10条数据。那么这里查询的开销是多少?最接近User * Dept次查询(当然这个前提是没有索引)
接近2张表的笛卡尔开销。Left Join越多,笛卡尔开销越大。
第二点: Mysql中的Join的查询原理是一种叫做nested loop join的算法。这种算法是以驱动表作为循环依据,一条一条传入下一
个表作为查询。
第三点: ALL式查询,我们也是以这个SQL作为优化示例。在最初的 查询计划中所有关联都是采用ALL的方式,也就是没有添加
索引情况下。当然再添加完索引查询计划就被优化了。
(2) 优化建议
针对上述的3点我们提出一些优化建议:
第一点:这个没办法,只能说尽量减少多个Left Join。
第二点:在业务场景允许的情况下,将小数据的表作为左表关联。
第三点:首先,添加必要的索引。其次,如果出现Join表的查询条件把查询条件放入Join中。这点的原理实际上基于第二点的
查询算法,但是我把放入这里是因为它可以较低查询级别。举个简单的例子,比如 ...Left Join LEFT JOIN fk_menu m
ON m.menu_id = rm.menu_id,这个地方如果有只要查询出菜单类型为按钮的。不要在这个SQL最后添加
m.menu_type='BUTTON',而是在Left Join(select * from fk_menu where mene_type = 'BUTTON' ) m on ....。
四:预编译SQL-视图
好么,最好放出最有效的方法,预编译。使用临时表或者视图或者存储过程来存储SQL,代码直接调用即可。
1.创建视图
CREATE VIEW v_login_user
AS
SELECT
a.fk_user_id AS "fk_user_id",
a.user_realname AS "user_realname",
a.user_name AS "user_name",
a.user_type AS "user_type",
a.sex AS "sex",
a.phone AS "phone",
a.password AS "password",
a.user_addr AS "user_addr",
a.avater AS "avater",
a.status AS "status",
fr.role_id as role_id,
fr.role_code as role_code,
fr.role_name as role_name,
fr.role_range as role_range,
fd.dept_id as dept_id,
fd.dept_name as dept_name,
fd.parent_id as dept_parent,
fd.parent_ids as dept_parents,
fd.company_name as company_name,
fp.post_id as post_id,
fp.post_name as post_name,
fp.post_split as post_split,
m.perms as perms
FROM fk_user a
LEFT JOIN fk_user_role fkur ON fkur.user_id = a.fk_user_id
LEFT JOIN fk_role fr ON fr.role_id = fkur.role_id
LEFT JOIN fk_role_menu rm ON rm.role_id = fr.role_id
LEFT JOIN fk_menu m ON m.menu_id = rm.menu_id
LEFT JOIN fk_dept fd ON fd.dept_id = a.dept_id
LEFT JOIN fk_user_post fup ON fup.user_id = a.fk_user_id
LEFT JOIN fk_post fp ON fp.post_id = fup.post_id
2.调用视图
视图的本质就是一张临时表,
SELECT * FROM v_login_user WHERE user_name = 'admin'3.视图的更新
比较感人的是,表数据的更新并不会导致视图的更新。比如说,我将User的username改为Admin123.视图查询UserName=Adm
in123并没有 。需要我们手动更新:更新语句如同更新一个表的行一样。
4.视图新增和删除
从上面可以看出,新增和删除需要我们手动来喽,当然同新增/删除一张表一致。
5.说明视图的使用场景
视图的创建就是将当前数据缓存到一张临时表中,然后查询,一般不适用可以修改的数据,因为修改要改表,也要改视图很麻烦。那么视图有什么作用呢?作用就是对前一天或者几天数据做统计。很明显本例不适用。
五:创建存储过程
存储过程的SQL比较复杂,这里就不上传了。其实在本例中也不适用。Mysql的视图是一张临时表,它是将查询结果放入其中,当被查询的表出现改动,视图临时表数据不会改动。而Mysql的存储过程则是预先将SQL语句编译成可执行的机器语言,只用用的时候才去查询数据。