Metrics Server
从Kubernetes 1.8开始,Kubernetes通过Metrics API提供资源使用指标,例如容器CPU和内存使用。这些度量可以由用户直接访问,例如通过使用kubectl top命令,或者由群集中的控制器(例如Horizontal Pod Autoscaler)使用来进行决策。
root@k8s-master-1:~# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
192.168.2.10 215m 5% 1679Mi 43%
192.168.2.11 119m 2% 1383Mi 36%
192.168.2.12 116m 2% 912Mi 23%
192.168.2.13 292m 7% 1573Mi 41%
root@k8s-master-1:~# kubectl top pod
NAME CPU(cores) MEMORY(bytes)
kube-resource-report-6d6ddfcfbc-sxg4k 0m 65Mi
myapp-c78bcd8fb-dt87s 0m 10Mi
myapp-envoy-696b6d764d-s8gvs 5m 30Mi
Metrics API
通过Metrics API,您可以获得给定节点或给定pod当前使用的资源量。此API不存储Metrics Value,因此例如在10分钟前获取给定节点使用的资源量是不可能的。
API与任何其他API没有区别:
- 它可以通过与
/apis/metrics.k8s.io/路径下的其他Kubernetes API相同的端点发现 - 它提供相同的安全性,可扩展性和可靠性保证
API在k8s.io/metrics 存储库中定义。您可以在那里找到有关API的更多信息。
注意: API要求在群集中部署Metrics Server。否则它将无法使用。
Metrics Server
Metrics Server 实现了Metrics API。
Metrics Server 是集群范围资源使用数据的聚合器。 从 Kubernetes 1.8 开始,它作为一个 Deployment 对象默认部署在由 kube-up.sh 脚本创建的集群中。 如果你使用了其他的 Kubernetes 安装方法,您可以使用 Kubernetes 1.7+ (请参阅下面的详细信息) 中引入的 deployment yamls 文件来部署。
Metrics Server 从每个节点上的 Kubelet 公开的 Summary API 中采集指标信息。
通过在主 API server 中注册的 Metrics Server Kubernetes 聚合器 来采集指标信息, 这是在 Kubernetes 1.7 中引入的。在 设计文档 中可以了解到有关 Metrics Server 的更多信息。
Custom Metrics API
custom-metrics-apiserver 该 API 允许消费者访问通过任意指标描述的 Kubernetes 资源。如果你想实现这个 API Service,这是一个用来实现 Kubernetes 自定义指标的框架。
Horizontal Pod Autoscaler
Horizontal Pod Autoscaler根据观察到的CPU利用率(或者,通过Custom Metrics API 支持,根据其他一些应用程序提供的指标)自动调整复制控制器,部署或副本集中的pod数 。请注意,Horizontal Pod Autoscaling不适用于无法缩放的对象,例如DaemonSet。
Horizontal Pod Autoscaler实现为Kubernetes API资源和控制器。资源确定控制器的行为。控制器会定期调整复制控制器或部署中的副本数,以使观察到的平均CPU利用率与用户指定的目标相匹配。
Horizontal Pod Autoscaler如何工作
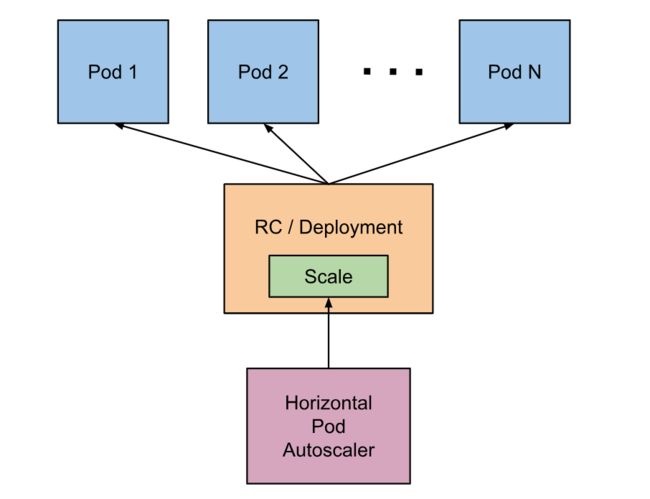
Horizontal Pod Autoscaler实现为循环监测,其周期由控制器管理器的--horizontal-pod-autoscaler-sync-period标志控制(默认值为15秒)。
在每个期间,控制器管理器根据每个HorizontalPodAutoscaler定义中指定的度量查询资源利用率。控制器管理器从资源指标API(针对每个窗格资源指标)或自定义指标API(针对所有其他指标)获取指标。
- 对于每个pod资源指标(如CPU),控制器从HorizontalPodAutoscaler所针对的每个pod获取资源指标API中的指标。然后,如果设置了目标利用率值,则控制器将利用率值计算为每个容器中容器上的等效资源请求的百分比。如果设置了目标原始值,则直接使用原始度量标准值。然后,控制器在所有目标pod中获取利用率的平均值或原始值(取决于指定的目标类型),并产生用于缩放所需副本数量的比率。
请注意,如果某些pod的容器没有设置相关的资源请求,则不会定义pod的CPU利用率,并且autoscaler不会对该度量标准采取任何操作。有关自动调节算法如何工作的更多信息,请参阅下面的算法详细信息部分。
对于每个pod自定义指标,控制器的功能与每个pod资源指标类似,不同之处在于它适用于原始值,而不是使用值。
对于对象度量和外部度量,将获取单个度量,该度量描述相关对象。将该度量与目标值进行比较,以产生如上所述的比率。在
autoscaling/v2beta2API版本中,可以选择在进行比较之前将此值除以pod的数量。
所述HorizontalPodAutoscaler通常由一系列的API聚集(的获取度量metrics.k8s.io, custom.metrics.k8s.io和external.metrics.k8s.io)。该metrics.k8s.ioAPI通常是通过Metrics Server,其需要单独启动提供。有关说明,请参阅 metrics-server。HorizontalPodAutoscaler还可以直接从Heapster(从Kubernetes 1.11开始,不推荐从Heapster获取指标。)获取指标。
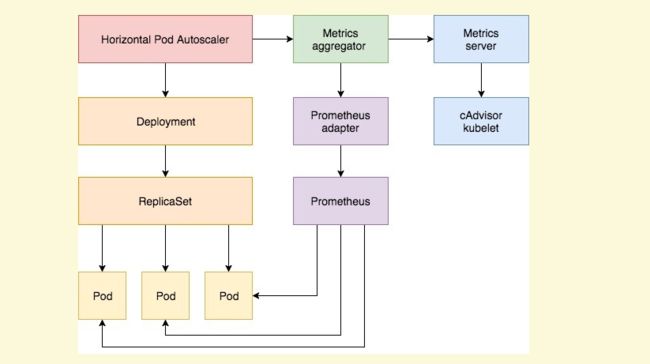
安装 Metrics Server
安装官方文档 metrics server yaml
创建metrics-server pod

生成 metrics.k8s.io/v1beta1

查看 nodes 指标

查看 pods 指标

安装Custom Metrics Server
需要在集群内有Prometheus 从中收集指标并将其存储为 Prometheus 时间序列数据库。
安装 custom metrics apiserver 提供的 metrics 来扩展 Kubernetes 自定义指标 API
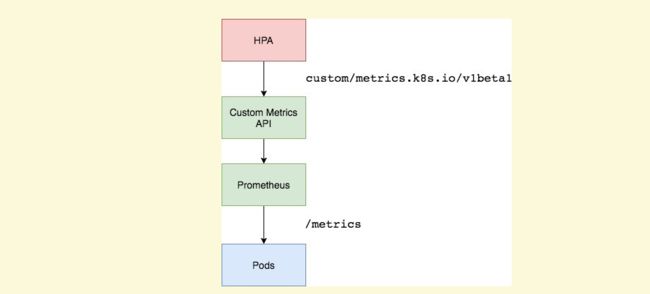
基于自定义指标的自动扩容
CoreDns本身也是可以基于cpu负载来做HPA,但是实际测试下来波动较大,所以考虑通过自定义指标来弹性伸缩
CoreDns 作为Kubernetes 1.11版本之后的默认dns插件之后,本身9153端口提供/metrics接口
-
coredns_build_info{version, revision, goversion}- 有关CoreDNS本身的信息。 -
coredns_panic_count_total{}- 恐慌总数。 -
coredns_dns_request_count_total{server, zone, proto, family}- 总查询次数。 -
coredns_dns_request_duration_seconds{server, zone}- 处理每个查询的持续时间。 -
coredns_dns_request_size_bytes{server, zone, proto}- 请求的大小(以字节为单位)。 -
coredns_dns_request_do_count_total{server, zone}- 设置了DO位的查询 -
coredns_dns_request_type_count_total{server, zone, type}- 每个区域和类型的查询计数器。 -
coredns_dns_response_size_bytes{server, zone, proto}- 响应大小(字节)。 -
coredns_dns_response_rcode_count_total{server, zone, rcode}- 每个区域和rcode的响应。 -
coredns_plugin_enabled{server, zone, name}- 指示是否基于每个服务器和区域启用插件。
这次我就利用coredns_dns_request_count_total{server, zone, proto, family} Prometheus adapter(即 custom-metrics-apiserver)删除了 _total 后缀并将该指标标记为 coredns_dns_request_count
从Custom Metrics API 获取每秒的总查询次数:
root@k8s-master-1:~/k8s_manifests# kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/kube-system/pods/*/coredns_dns_request_count" | jq .
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/kube-system/pods/%2A/coredns_dns_request_count"
},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "kube-system",
"name": "coredns-dc8bbbcf9-5jdqc",
"apiVersion": "/v1"
},
"metricName": "coredns_dns_request_count",
"timestamp": "2019-05-13T08:25:00Z",
"value": "911m"
},
{
"describedObject": {
"kind": "Pod",
"namespace": "kube-system",
"name": "coredns-dc8bbbcf9-fp7wx",
"apiVersion": "/v1"
},
"metricName": "coredns_dns_request_count",
"timestamp": "2019-05-13T08:25:00Z",
"value": "577m"
}
]
}
m 表示 毫,例如,911m 表示911 毫次/每秒
创建一个 HPA,如果请求数超过每秒 1000 次将扩大 coredns 副本数:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: coredns
namespace: kube-system
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: coredns
minReplicas: 2
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: coredns_dns_request_count
targetAverageValue: 1000
总结
不是所有的应用都可以适用依靠 CPU 和Memory指标做弹性伸缩来满足系统的负载,大多数 Web 应用的后端都需要基于每秒的请求数量QPS进行弹性伸缩来处理突发流量。而一些 ETL 应用程序,可以通过设置 Job 队列长度超过某个阈值来触发弹性伸缩工作pod。
通过 Prometheus 来监控应用程序并暴露出用于弹性伸缩的指标/metric,可以微调应用程序以更好地处理突发事件,从而确保其高可用性。
参考文档:
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
https://github.com/coredns/coredns/tree/master/plugin/metrics
https://github.com/kubernetes-incubator/metrics-server
https://github.com/DirectXMan12/k8s-prometheus-adapter
https://github.com/coreos/prometheus-operator