yolo3的学习
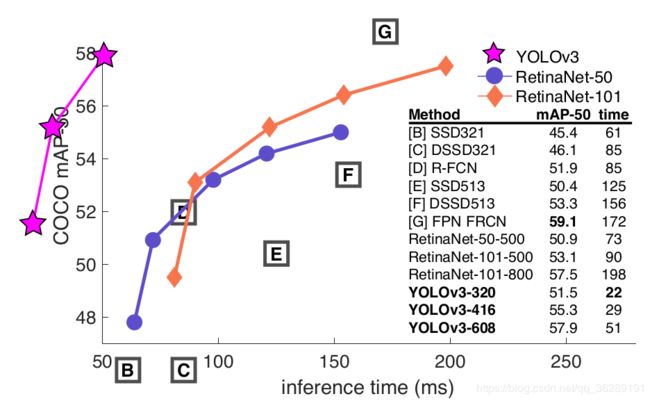
yolo3与SSD、retinaNet等在MAP和时间上的对比:
(关于MAP:MAP的全称为mean average precision,也就是均值平均精度,好多时候都直接称为准确度,它是的AP取的均值,比如在一个识别任务里面会有好多类目标,而每一类里面有多个不同的具体目标,每个目标的预测结果与真实结果之间的差别用precision来表示,对这一类平均就是AP,对每一类取均值,那就是MAP,还有一个作为网络评判的标注是recall,即召回率,召回率描述的是把正确结果找出来的程度。如40个男生,60个女生,要找50个女生,结果找出来的50个里有40个女生,10个男生,那她的precision就是40/50 ,而recall是40/60,precision的分母是找出结果的总数量,recall的分母是原有结构里面正确 数目之和)
yolo3论文上的内容比较少,更多的细节还是得分析代码。论文中主要讲了下面几点:
1.与yolo2相似的,yolo3仍旧使用dimension clusters来产生anchor box,预测位置上的4个值,也yolo2一致


yolo3使用logistic回归对每个bounding box给出是否为目标的置信度,如果某个bounding box的IOU最大就取为1,对于
其他的非极大值的就忽略。这样对于每个groud truth只分配一个最好的bounding box,对于没有分配的bounding box,对于位置和类别没有损失,只有判别是否有目标的置信度有损失。
2.考虑标签的重叠性(如女人和人),类别预测上不用softmax,因为softmax有个前提是是每个box对应一个标签,这对于多标签的数据很难处理,因此使用的是独立的logistic classifiers,训练时损失函数采用的是二分的交叉熵损失。
3.借鉴FPN,在不同的尺度上预测,在实验中在不同尺度上预测3个box,80个类别得到的是N*N*[3*(4+1+80)],上采样2x,与之前的通过element-wide相加的到merge,然后再接一些conv,具体细节请看下面代码部分。
首先,是yolo3的网络结构,如下图所示,主体部分被称为darknet53,右下脚部分借鉴FPN的思想,采用上采样与merge的方法进行预测。
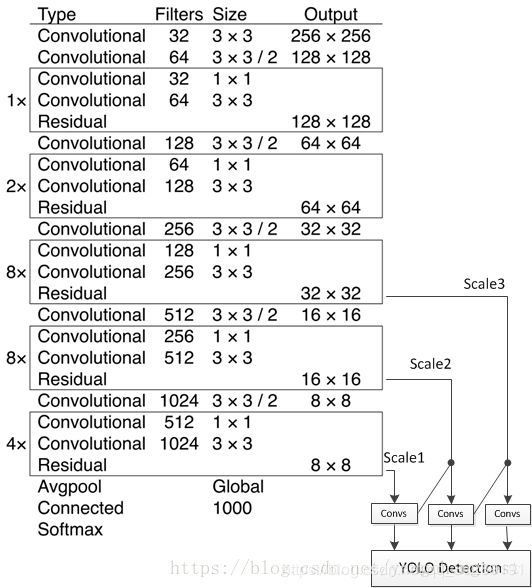
在代码中,作者先定义了DarknetConv2D函数,在此基础上又定义了DarknetConv2D_BN_Leaky,也就是在DarknetConv2D之后加上了bathnorm操作和LeakyReLU激活函数,并在此上定义resblock_body,让卷积成块。
compose(A,B,C)(x)=C(B(A(x)))
*args是不可变名参数,如一个固定值20;**kwargs是可变名参数,如k=20
def DarknetConv2D(*args, **kwargs):
"""Wrapper to set Darknet parameters for Convolution2D."""
darknet_conv_kwargs = {'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
def DarknetConv2D_BN_Leaky(*args, **kwargs):
"""Darknet Convolution2D followed by BatchNormalization and LeakyReLU."""
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
def resblock_body(x, num_filters, num_blocks):
'''A series of resblocks starting with a downsampling Convolution2D'''
# Darknet uses left and top padding instead of 'same' mode
x = ZeroPadding2D(((1,0),(1,0)))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (3,3), strides=(2,2))(x)
for i in range(num_blocks):
y = compose(
DarknetConv2D_BN_Leaky(num_filters//2, (1,1)),
DarknetConv2D_BN_Leaky(num_filters, (3,3)))(x)
x = Add()([x,y])
return x在此基础上darknet很简洁
def darknet_body(x):
'''Darknent body having 52 Convolution2D layers'''
x = DarknetConv2D_BN_Leaky(32, (3,3))(x)
x = resblock_body(x, 64, 1)
x = resblock_body(x, 128, 2)
x = resblock_body(x, 256, 8)#92层
x = resblock_body(x, 512, 8)#152层
x = resblock_body(x, 1024, 4)
return x右下角部分,先是定义make_last_layers,四层和六层卷积
def make_last_layers(x, num_filters, out_filters):
'''6 Conv2D_BN_Leaky layers followed by a Conv2D_linear layer'''
x = compose(
DarknetConv2D_BN_Leaky(num_filters, (1,1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D_BN_Leaky(num_filters, (1,1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D_BN_Leaky(num_filters, (1,1)))(x)
y = compose(
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D(out_filters, (1,1)))(x)
return x, y利用make_last_layers定义yolo_body,scale1处四层conv得到x,x再通过两层conv得到y1,另一方面x通过一层conv和x2的上采样与scale2处merge,经过4层conv得到x,x再通过两层conv得到y2,同理得到y3,最后输出y1,y2,y3用作预测。
yolo_head按照如下公式,(feats[..., :])中0到3是tx,ty,tw,th,4是confidence,之后是class_probs,grid是cx,cy,K.title是在维度上进行复制操作。
def yolo_head(feats, anchors, num_classes, input_shape, calc_loss=False):
"""Convert final layer features to bounding box parameters."""
num_anchors = len(anchors)
# Reshape to batch, height, width, num_anchors, box_params.
anchors_tensor = K.reshape(K.constant(anchors), [1, 1, 1, num_anchors, 2])
grid_shape = K.shape(feats)[1:3] # height, width
grid_y = K.tile(K.reshape(K.arange(0, stop=grid_shape[0]), [-1, 1, 1, 1]),
[1, grid_shape[1], 1, 1])
grid_x = K.tile(K.reshape(K.arange(0, stop=grid_shape[1]), [1, -1, 1, 1]),
[grid_shape[0], 1, 1, 1])
grid = K.concatenate([grid_x, grid_y])
grid = K.cast(grid, K.dtype(feats))
feats = K.reshape(
feats, [-1, grid_shape[0], grid_shape[1], num_anchors, num_classes + 5])
# Adjust preditions to each spatial grid point and anchor size.
box_xy = (K.sigmoid(feats[..., :2]) + grid) / K.cast(grid_shape[::-1], K.dtype(feats))
box_wh = K.exp(feats[..., 2:4]) * anchors_tensor / K.cast(input_shape[::-1], K.dtype(feats))
box_confidence = K.sigmoid(feats[..., 4:5])
box_class_probs = K.sigmoid(feats[..., 5:])
if calc_loss == True:
return grid, feats, box_xy, box_wh
return box_xy, box_wh, box_confidence, box_class_probsyolo_correct_boxes是将训练时用的(416,416)得出的bbox转化成原图size的bbox
def yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape):
'''Get corrected boxes'''
box_yx = box_xy[..., ::-1]
box_hw = box_wh[..., ::-1]
input_shape = K.cast(input_shape, K.dtype(box_yx))
image_shape = K.cast(image_shape, K.dtype(box_yx))
new_shape = K.round(image_shape * K.min(input_shape/image_shape))
offset = (input_shape-new_shape)/2./input_shape
scale = input_shape/new_shape
box_yx = (box_yx - offset) * scale
box_hw *= scale
box_mins = box_yx - (box_hw / 2.)
box_maxes = box_yx + (box_hw / 2.)
boxes = K.concatenate([
box_mins[..., 0:1], # y_min
box_mins[..., 1:2], # x_min
box_maxes[..., 0:1], # y_max
box_maxes[..., 1:2] # x_max
])
# Scale boxes back to original image shape.
boxes *= K.concatenate([image_shape, image_shape])
return boxes在preprocess_true_boxes中,true_boxes批次数m,最大框数T,每个框5个值,y_true的第0和1位是中心点xy,范围是(0~13/26/52),第2和3位是宽高wh,范围是0~1,第4位是置信度1或0,第5~n位是类别为1其余为0。
def preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes):
'''Preprocess true boxes to training input format
Parameters
----------
true_boxes: array, shape=(m, T, 5)
Absolute x_min, y_min, x_max, y_max, class_id relative to input_shape.
input_shape: array-like, hw, multiples of 32
anchors: array, shape=(N, 2), wh
num_classes: integer
Returns
-------
y_true: list of array, shape like yolo_outputs, xywh are reletive value
'''
assert (true_boxes[..., 4]0#存在box的为true
for b in range(m):
# Discard zero rows.
wh = boxes_wh[b, valid_mask[b]]#对于每个batch中,任何一个框存在box,则得到其坐标
if len(wh)==0: continue
# Expand dim to apply broadcasting.
wh = np.expand_dims(wh, -2)#扩充倒数第二维,由(num,2)到(num,1,2)
box_maxes = wh / 2.
box_mins = -box_maxes
intersect_mins = np.maximum(box_mins, anchor_mins)#得到的是(num,9,2)
intersect_maxes = np.minimum(box_maxes, anchor_maxes)
intersect_wh = np.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
box_area = wh[..., 0] * wh[..., 1]
anchor_area = anchors[..., 0] * anchors[..., 1]
iou = intersect_area / (box_area + anchor_area - intersect_area)#(num,9)
# Find best anchor for each true box
best_anchor = np.argmax(iou, axis=-1)
for t, n in enumerate(best_anchor):#t是box的序号;n是最优anchor的序号;l是层号;
for l in range(num_layers):
if n in anchor_mask[l]:
i = np.floor(true_boxes[b,t,0]*grid_shapes[l][1]).astype('int32')
j = np.floor(true_boxes[b,t,1]*grid_shapes[l][0]).astype('int32')
k = anchor_mask[l].index(n)
c = true_boxes[b,t, 4].astype('int32')
y_true[l][b, j, i, k, 0:4] = true_boxes[b,t, 0:4]
y_true[l][b, j, i, k, 4] = 1
y_true[l][b, j, i, k, 5+c] = 1
return y_true 对于IOU的计算与preprocess_true_boxes中IOU的计算类似
def box_iou(b1, b2):
'''Return iou tensor
Parameters
----------
b1: tensor, shape=(i1,...,iN, 4), xywh
b2: tensor, shape=(j, 4), xywh
Returns
-------
iou: tensor, shape=(i1,...,iN, j)
'''
# Expand dim to apply broadcasting.
b1 = K.expand_dims(b1, -2)
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
# Expand dim to apply broadcasting.
b2 = K.expand_dims(b2, 0)
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
intersect_mins = K.maximum(b1_mins, b2_mins)
intersect_maxes = K.minimum(b1_maxes, b2_maxes)
intersect_wh = K.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
iou = intersect_area / (b1_area + b2_area - intersect_area)
return iouargs中是yolo_outputs和y_true的组合,两者格式一致,都是[(?, 13, 13, 3*85), (?, 26, 26, 3*85), (?, 52, 52, 3*85)],前者是网络的预测值,后者是真值。input_shape是[13,13]*32也就是416*416,grid_shape就是[(13,13),(26,26),(52,52)]。mf就是batchsize。整体的损失函数可以参照yolo1中的损失函数。
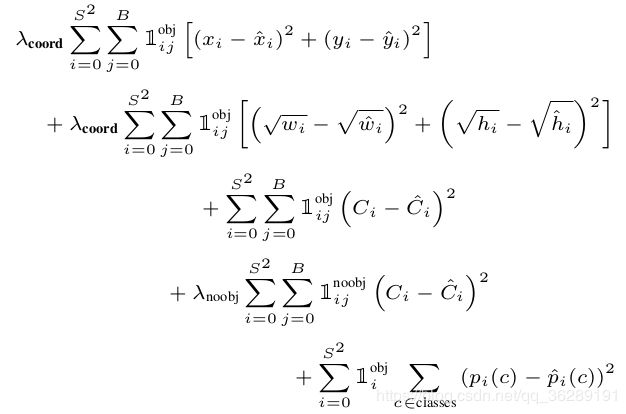
但在yolo3中,作者将平方损失改成了交叉熵的损失。权值取得是2-w*h
def yolo_loss(args, anchors, num_classes, ignore_thresh=.5, print_loss=False):
'''Return yolo_loss tensor
Parameters
----------
yolo_outputs: list of tensor, the output of yolo_body or tiny_yolo_body
y_true: list of array, the output of preprocess_true_boxes
anchors: array, shape=(N, 2), wh
num_classes: integer
ignore_thresh: float, the iou threshold whether to ignore object confidence loss
Returns
-------
loss: tensor, shape=(1,)
'''
num_layers = len(anchors)//3 # default setting
yolo_outputs = args[:num_layers]
y_true = args[num_layers:]
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]]
input_shape = K.cast(K.shape(yolo_outputs[0])[1:3] * 32, K.dtype(y_true[0]))
grid_shapes = [K.cast(K.shape(yolo_outputs[l])[1:3], K.dtype(y_true[0])) for l in range(num_layers)]
loss = 0
m = K.shape(yolo_outputs[0])[0] # batch size, tensor
mf = K.cast(m, K.dtype(yolo_outputs[0]))
for l in range(num_layers):
object_mask = y_true[l][..., 4:5]#是否有目标的置信度
true_class_probs = y_true[l][..., 5:]#在有目标情况下,各类别出现的概率
grid, raw_pred, pred_xy, pred_wh = yolo_head(yolo_outputs[l],
anchors[anchor_mask[l]], num_classes, input_shape, calc_loss=True)
pred_box = K.concatenate([pred_xy, pred_wh])
# Darknet raw box to calculate loss.
raw_true_xy = y_true[l][..., :2]*grid_shapes[l][::-1] - grid#与yolo_head对比来看
raw_true_wh = K.log(y_true[l][..., 2:4] / anchors[anchor_mask[l]] * input_shape[::-1])
raw_true_wh = K.switch(object_mask, raw_true_wh, K.zeros_like(raw_true_wh)) # avoid log(0)=-inf
box_loss_scale = 2 - y_true[l][...,2:3]*y_true[l][...,3:4]#2-w*h
# Find ignore mask, iterate over each of batch.
ignore_mask = tf.TensorArray(K.dtype(y_true[0]), size=1, dynamic_size=True)
object_mask_bool = K.cast(object_mask, 'bool')
def loop_body(b, ignore_mask):
true_box = tf.boolean_mask(y_true[l][b,...,0:4], object_mask_bool[b,...,0])
iou = box_iou(pred_box[b], true_box)
best_iou = K.max(iou, axis=-1)
ignore_mask = ignore_mask.write(b, K.cast(best_iou