浅析GPU计算——CPU和GPU的选择
原文地址:https://blog.csdn.net/breaksoftware/article/details/79275626,为了自己用手机看方便,所以转载了,希望博主勿怪
目前市面上介绍GPU编程的博文很多,其中很多都是照章宣科,让人只能感受到冷冷的技术,而缺乏知识的温度。所以我希望能写出一篇可以体现技术脉络感的文章,让读者可以比较容易理解该技术,并可以感悟到cuda编程设计及优化的原理。(转载请指明出于breaksoftware的csdn博客)
谈到计算,我们一般都会先想到CPU。CPU的全称是Central Processing Unit,而GPU的全称是Graphics Processing Unit。在命名上。这两种器件相同点是它们都是Processing Unit——处理单元;不同点是CPU是“核心的”,而GPU是用于“图像”处理的。在我们一般理解里,这些名称的确非常符合大众印象中它们的用途——一个是电脑的“大脑核心”,一个是图像方面的“处理器件”。但是聪明的人类并不会被简单的名称所束缚,他们发现GPU在一些场景下可以提供优于CPU的计算能力。
于是有人会问:难道CPU不是更强大么?这是个非常好的问题。为了解释这个疑问,我们需要从CPU的组织架构说起。由于Intel常见的较新架构如broadwell、skylake等在CPU中都包含了一颗GPU,所以它们不能作为经典的CPU架构去看待。我们看一款相对单纯的CPU剖面图

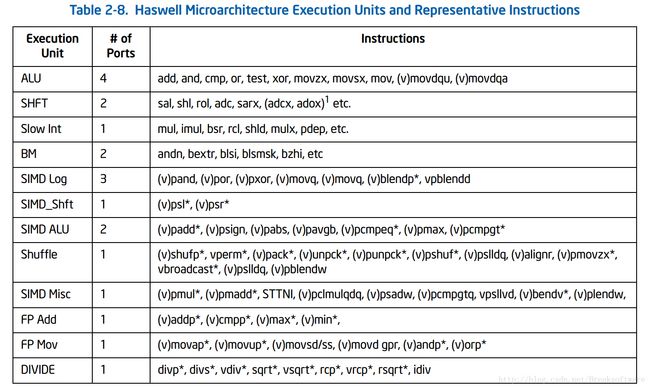
这款CPU拥有8颗处理核心,其他组件有L3缓存和内存控制器等。可以见得该款CPU在物理空间上,“核心”并不是占绝大部分。就单颗Core而言(上图CPU属于Haswell-E架构,下面截图则为Haswell的Core微架构。“Intel processors based on the Haswell-E microarchitecture comprises the same processor cores as described in the Haswell microarchitecture, but provides more advanced uncore and integrated I/O capabilities. ”——《64-ia-32-architectures-optimization-manual》)

可以看到,其有20多种“执行单元”(Execution Units),如ALU、FMA、FP add和FP mul等。每个“执行单元”用于处理不同的指令
可以见得CPU是个集各种运算能力的大成者。这就如同一些公司的领导,他们可能在各个技术领域都做到比较精通。但是一个公司仅仅只有这样的什么都可以做的领导是不行的,因为领导的价值并不只是体现在一线执行能力上,还包括调度能力。
我们以Intel和ARM的CPU为例。比如我手上有一台国产号称8核心,每颗核心可达2GHz的手机,目前打开两个应用则卡顿严重。而我这台低等配置的两核心,最高睿频2.8GHz的笔记本,可以轻轻松松运行多个应用。抛开系统和应用的区别,以及CPU支持的指令集来思考,到底是什么让Intel的CPU使用起来越来越流畅?
有人可能说是主频,我们看下CPU主频的发展图
可以见得CPU的主频在2000年以前还是符合摩尔定律的。但是在2005年左右,各大厂商都没有投放更高主频的CPU(理论上现在主频应该达到10GHz了),有的反而进行了降频。为什么?一是CPU的主频发展在当前环境下已经接近极限,而且功耗也会随着主频增加而增加。但是我们感觉到电脑越来越慢了么?
也有人说是核心数。最近10来年,市面上桌面版intel系列CPU还是集中在2、4、8核心数上。以2005年的奔腾D系列双核处理器和现在core i3 双核处理器来对比,奔腾D应该难以顺畅的运行Win10吧(它的执行效率连2006年发布的Core 2 Duo都不如)。
还有人会说是乱序执行(out of order)。一个比较经典的乱序执行例子是这样的
-
class_name * p = NULL; -
…… -
p = new class_name;
我们一般理解这个过程可以分解为:1 分配空间;2 调用构造函数;3 空间地址赋值给p。然后CPU可能会将2,3两个顺序颠倒。
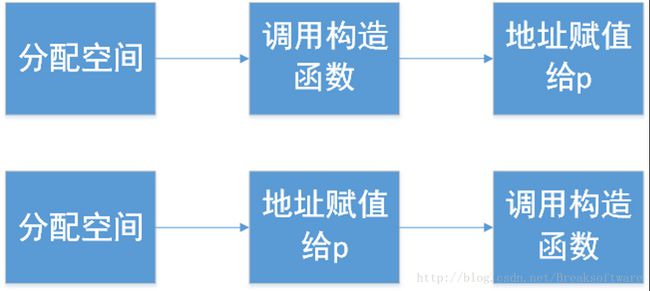
这样做有什么好处呢?比如另外一个线程B要检测p是否为NULL,如果不为NULL则调用相应方法。如果按照先构造再赋值的顺序,线程B要等待上述流程结束后才能开始前进。而如果采用先赋值再构造,线程B在赋值结束后就开始前进了,而此时new操作所在的线程可能也同步完成了构造函数的调用。(当然这和我们理解不同,可能会引起bug)
然而ARM也有这样的功能
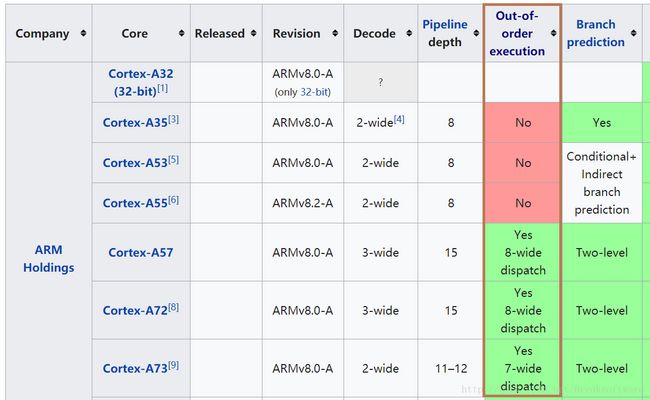
除了上述观点外,还有缓存存取速率、缓存大小等影响因素。但是这些因素,ARM系列CPU也可以做到,但是为什么还是没Intel快呢?
当然因素肯定是多样的。接下来我只是罗列出个人认为比较重要的原因
分支预测(Branch predictor)。再以一段代码为例
-
int b = 3; -
int c = 4; -
bool a = memory_enough(); -
if (a) { -
b *= c; -
} -
else { -
b += c; -
}
如果按照一般的想法,CPU执行的流程是:获取a的值后选择一个分支去执行。假如a的逻辑可能比较耗时(比如存在IO等待操作),CPU要一直等待下去么?现在CPU的做法则相对智能,它会预测a的值,执行预测对应的分支。然后等到a的值返回后再校验是否猜测正确,如果正确,我们将节省一个分支执行的等待时间。如果猜测错误,则回退回去再执行正确的流程。
可能有人会怀疑分支在代码逻辑中的比例那么高么?需要独立设计这么一个功能来优化?据我对部分项目做得统计分析,很多业务代码的分支占比在80%左右。
可能还有人会怀疑这种猜测靠谱么?据尚未考证的消息,intel号称准确率超过90%。虽然ARM也有分支预测功能,但是其准确率有这么高么?我尚未找到相应数据。
说了这么多,我只想说明一个观点:CPU是一个拥有多种功能的优秀领导者。它的强项在于“调度”而非纯粹的计算。而GPU则可以被看成一个接受CPU调度的“拥有大量计算能力”的员工。
为什么说GPU拥有大量计算能力。我们看一张NV GPU的架构图

这款GPU拥有4个SM(streaming multiprocessor),每个SM有4*8个Core,一共有4*4*8=64个Core(此处的Core并不可以和CPU结构图中的Core对等,它只能相当于CPU微架构中的一个“执行单元”。之后我们称GPU的Core为cuda核)。
再对比一下CPU的微架构和架构图,以FP mul“执行单元为例”,一个CPU的Core中有2个,六核心的CPU有12个。虽然我们不知道GPU cuda核的内部组成,但是可以认为这样的计算单元至少等于cuda核数量——60。
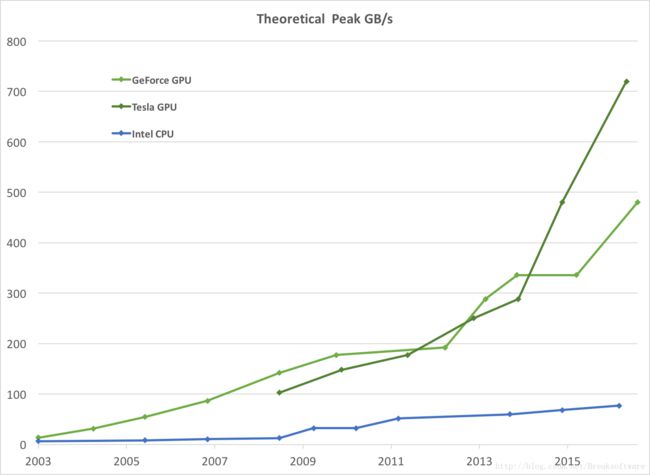
60和12的对比还不强烈。我们看一张最新的NV显卡的数据

5120这个和12已经不是一个数量级了!
如果说cuda核心数不能代表GPU的算力。那我们再回到上图,可以发现这款GPU提供了640个Tensor核心,该核心提供了浮点运算能力。我并不太清楚CPU中有多少类似的核心,但是从NV公布的一幅图可以看出两者之间的差距——也差一个量级。
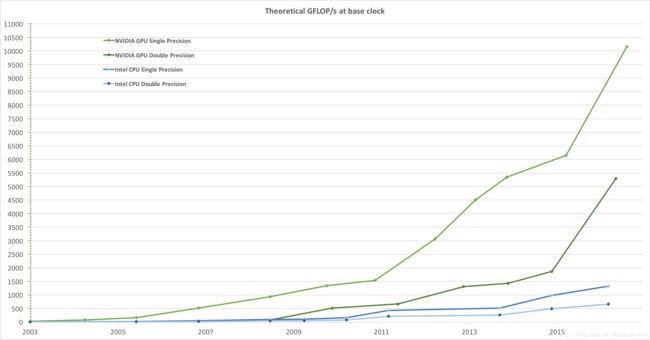
除了计算能力,还有一个比较重要的考量因素就是访存的速率。当我们进行大量计算时,往往只是使用寄存器以及一二三级缓存是不够的。
目前Intel的CPU在设计上有着三级缓存,它们的访问速度关系是:L1>L2>L3,而它们的容积关系则相反:L1 然而GPU对应的显存带宽则比CPU对应内存高出一个数量级! 通过本文的讲述,我们可以发现GPU具有如下特点: 1 提供了多核并行计算的基础结构,且核心数非常多,可以支撑大量并行计算 2 拥有更高的访存速度 3 更高的浮点运算能力 如果我们在使用CPU运行代码时遇到上述瓶颈,则是考虑切换到GPU执行的时候了。 下节我们将结合cuda编程来讲解GPU计算相关知识。 参考资料: