python3 scrapy实战(简单实现爬取下载图片原理)
这篇scrapy简单实现爬取并下载图片文章是为了后面一篇图片数据分析文章收集数据,后面我将做一个图片数据分析以及算法,这里顺便在复习一下之前学的scrapy语法以及原理,也是为了做个笔记和分享经验。
虽然我之前学过而且这是个简单的scrapy实现,但是编程过程并不是一帆风顺,有的错误还是有必要参考长经验的。
前言:个人很喜欢李小冉演的电视剧,最近刚看了《美好生活》,很触动人心,有深度。所以我决定爬点她的图片,这里对于图片的匹配,我选择的是xpath,所以在爬去的网页上你应该先看看是否可以使用查看到属性,找个简单的网页。
可以根据自己的需求,选择爬去的网页,只需要修改代码中的url和xpath路径就差不多了,具体情况具体分析,下面为具体实现:
这里就不再涉及scrapy太基础的内容了,如果需要请看前面的文章,前面有讲解scrapy的实现原理以及操作代码。
过程中我们需要设计几个.py文件:spider.py、items.py、pipelines.py、settings.py以及自己编写的main.py(为了方便调用代码) 等五个文件。
以下文件中涉及有较多注释代码,这里是为了更好的说明错误的步骤(个人错误),项目代码其实不多。
spider.py:
# -*- coding: utf-8 -*-
import scrapy
import sys
sys.path.append("D:\PYscrapy\get_lixiaoran") #这里添加Items文件和main文件的路径,下面能调用
from get_lixiaoran.items import GetLixiaoranItem #使用容器类的方法
import main
class LixiaoranSpider(scrapy.Spider):
name = "lixiaoran"
allowed_domains = ["www.27270.com"]
start_urls = ['http://www.27270.com/star/102293.html']
def download(self,link): #不要在这里面返回item,这样pipeline的process_item函数
item = GetLixiaoranItem() #是不能被调用的,应该在parse中yield item
item['picture'] = link #这里需要特别强调一下!!!
print(link)
return item
def parse(self, response): #就使用这一个函数,download是个不正确例子
data = response.xpath('//*[@id="imgList"]/ul/li[*]/div/a/img/@src')
links = data.extract()
item = GetLixiaoranItem() #实例化容器对象
for link in links:
# self.download(link) #调用自己编写的函数没法yield item
# request = scrapy.Request(link,callback=self.download) #这里是src不是href,搞错了一开始
# yield request
item['picture'] = link
yield item #切记在parse中yield item,否则通道使用有误items.py
import scrapy
class GetLixiaoranItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
picture = scrapy.Field() #这里我只装了src连接,其它的信息,可以自己设置容器来装 如:title = scrapy.Field()pipelines.py
# Don't forget to add your pipeline to the ITEM_PIPELINES setting #原始文件的提醒,注意设置settings
from urllib.request import urlretrieve
import os
import urllib.request
global page #全局定义page
class Getlixiaoranpipeline(object): #我重新编写的类
def __init__(self):
self.path = "D:\PYscrapy\get_lixiaoran\picture" #图片保存路径
self.page = 0 #图片名我用数字代替
if not os.path.exists(self.path): #检查文件是否存在
os.mkdir(self.path)
def question(self,a,b,c): #附赠一个观察下载进度的函数方法,当然也可以不调用
per = 100*a*b/c #在方法一中调用
if per>=100:
per = 100
print("下载完成!!")
print("%.2f%%" % per)
def process_item(self, item, spider):
src = item['picture']
try: #下载图片方法一,在使用urlretrieve直接下载,这个代码量少
urlretrieve(src,"D:\PYscrapy\get_lixiaoran\picture\%s.jpg" % self.page,self.question)
self.page +=1
except Exception as e:
print(e)
# pathname = os.path.join(self.path,str(self.page)+'.jpg')
# try:
# res = urllib.request.urlopen(src) #下载图片方法二,在文件中写入请求内容,这个好理解
# with open(pathname,'wb') as f:
# f.write(res.read())
# self.page +=1
# except Exception as e:
# print(e)
return itemsettings.py(需要开启pipeline的通道,程序才能调用)
ITEM_PIPELINES = { #在settings中找到并取消注释
# 'get_lixiaoran.pipelines.GetLixiaoranPipeline': 300, #这是原来的通道函数
'get_lixiaoran.pipelines.Getlixiaoranpipeline':30, #我使用我编写的 后面的数字表示通道类的优先级,越小越先执行
}main.py(我自己编写的,里面就是调用开始程序的命令,否则需要到cmd中执行)
from scrapy import cmdline
cmdline.execute("scrapy crawl lixiaoran --nolog".split()) #这也是一个技巧,程序员是最懒的人。这样你就可以在spider中直接运行程序以上就是全部.py文件的内容,若有修改具体情况具体分析。内容中包含许多与项目无关的内容,只是为了更好的展现思路,不需要的朋友可以删去。
部分爬取内容如下(李小冉beautiful):
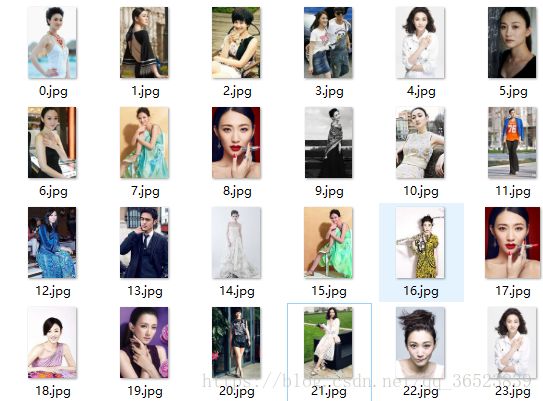
好了scrapy这里已经基本完成了,有问题的朋友可以留言。
接下来就是更大的工程了,图片数据分析,想想都chi激!!!