基于Tensorflow和DCGAN生成动漫头像实践(二)
本篇内容为动漫头像生成的主要代码部分,第一次写这种代码,从读取数据到生成走了一个完整的流程。创建TFrecord过程可以看上一篇内容。
代码内容:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import importlib,sys
import matplotlib.pyplot as plt
stdi,stdo,stde=sys.stdin,sys.stdout,sys.stderr #编码问题,重载sys,不然读取图片会报错
importlib.reload(sys)
#sys.setdefaultencoding('utf-8')
sys.stdin,sys.stdout,sys.stderr=stdi,stdo,stde
noises_size = 128 #定义噪声的维度大小
def gen_deconv(batch_input,out_channels):
return tf.layers.conv2d_transpose(batch_input,out_channels,4,2,padding='same') #解卷积操作,这里的参数可以理解为把图像长宽x2
#tensorflow的解卷积方式有layer和nn下两种方式,
#nn下的可以指定输出的维度大小,但是使用时老是
#报错,输出维度可以可根据解卷积核和步长推理出
def batchnorm(inputs): #batch normalization
return tf.layers.batch_normalization(inputs, axis=3, epsilon=1e-5, momentum=0.1,
training=True, gamma_initializer=tf.random_normal_initializer(1.0, 0.02))
def lrelu(x, a): #lrelu激活函数,看不懂的可以将x正负时代入试试
with tf.name_scope("lrelu"):
x = tf.identity(x)
return (0.5 * (1 + a)) * x + (0.5 * (1 - a)) * tf.abs(x)
def generator(noises,base=128,output_channels=3):
layers =[]
# Linear_layer: [batch, 1, 1, base*8]=> [batch, 3, 3, base*8]
with tf.variable_scope("Linear_layer"):
W = tf.get_variable("w", [noises_size, 3*3*8*base], tf.float32,tf.random_normal_initializer(stddev=0.02))
b = tf.get_variable("b", [3*3*8*base])
output = tf.matmul(noises,W) + b #一开始是一个全连接层
output = tf.reshape(output,[-1,3,3,base*8]) #[batch,3*3*base*8] -> [batch,3,3,base*8]
output = batchnorm(output)
print("gen_layer_%d" % (len(layers)+1))
print(output.shape)
layers.append(output)
layers_specs =[
(base * 8,0.5), # deconv_2: [batch, 3, 3, base*8] => [batch, 6, 6, base*8]
(base * 4,0.5), # deconv_3: [batch, 6, 6, base*8] => [batch, 12, 12, base*4]
(base * 2,0.0), # deconv_4: [batch, 12, 12, base*4] => [batch, 24, 24, base*2]
(base * 1,0.0) # deconv_5: [batch, 24, 24, base*2] => [batch, 48, 48, base*1]
]
for (out_channels,dropout) in layers_specs:
with tf.variable_scope("deconv_%d" % (len(layers)+1)):
temp = tf.nn.relu(layers[-1]) #relu激活函数
output = gen_deconv(temp,out_channels) #解卷积
output = batchnorm(output) #batch normalization
#if dropout> 0.0:
# output = tf.nn.dropout(output,keep_prob=1-dropout) #这个drop操作我忽略掉了
print("gen_layer_%d" % (len(layers)+1))
print(output.shape)
layers.append(output)
# deconv_6: [batch, 48, 48, base*2] => [batch, 96, 96, output_channels]
with tf.variable_scope("deconv_6"):
temp = layers[-1]
output = tf.nn.relu(temp)
output = gen_deconv(output,output_channels)
output = tf.tanh(output) #tanh函数将输出转化为(-1,1)
print("gen_layer_%d" % (len(layers)+1))
print(output.shape)
layers.append(output)
return layers[-1]
def dis_conv(batch_input,out_channels):
in_channels = int(batch_input.shape[3])
kernel = tf.get_variable(initializer=tf.random_normal(shape=[4,4,in_channels,out_channels]),name='kernel') #卷积操作,把图像长宽缩小为1/2,输出通道数为out_channels
return tf.nn.conv2d(batch_input,kernel,strides=[1,2,2,1],padding='SAME')
def discriminator(dis_input,base=128):
layers = []
# layer_1: [batch, 96, 96, 3] => [batch, 48, 48, base]
with tf.variable_scope("layer_1"):
output = dis_conv(dis_input,base)
output = lrelu(output,0.2)
print("layer_1")
print(output.shape)
layers.append(output)
layers_spec = [
base*2, # layer_2: [batch, 48, 48, base] => [batch, 24, 24, base*2]
base*4, # layer_3: [batch, 24, 24, base*2] => [batch, 12, 12, base*4]
base*8, # layer_4: [batch, 12, 12, base*4] => [batch, 6, 6, base*8]
base*8 # layer_5: [batch, 6, 6, base*8] => [batch, 3, 3, base*8]
]
for out_channels in layers_spec:
with tf.variable_scope("layer_%d" % (len(layers)+1)):
output = dis_conv(layers[-1],out_channels) #进行卷积
output = batchnorm(output) #进行batch normalization
output = lrelu(output,0.2) #激活函数为lrelu
print("layer_%d" % (len(layers)+1))
print(output.shape)
layers.append(output)
# layer_5: [batch, 3, 3, base*8] => [batch, 1]
with tf.variable_scope("layer_%d" % (len(layers)+1)):
output = tf.reshape(layers[-1],[-1,3*3*base*8]) #[batch,3,3,base*8] -> [batch,3*3*8]
W = tf.get_variable("w", [3*3*8*base,1], tf.float32,tf.random_normal_initializer(stddev=0.02))
b = tf.get_variable("b", [1])
output = tf.matmul(output,W) + b #这里是一个全连接层
output = tf.sigmoid(output) #sigmoid函数转化输出为0-1
print("layer_%d" % (len(layers)+1))
print(output.shape)
layers.append(output)
return layers[-1]
def create_model(gen_inputs,dis_inputs,learning_rate):
EPS = 1e-12
with tf.variable_scope("generator"):
gen_outputs = generator(gen_inputs)
with tf.variable_scope("discriminator"):
predict_real = discriminator(dis_inputs)
with tf.variable_scope("discriminator",reuse=True):
predict_fake = discriminator(gen_outputs)
with tf.name_scope("discriminator_loss"):
dis_loss = tf.reduce_mean(-tf.log(predict_real+EPS)-tf.log(1-predict_fake+EPS)) #这里加上EPS防止出现log(0),否则loss会变成nan
with tf.name_scope("generator_loss"):
gen_loss = tf.reduce_mean(-tf.log(predict_fake+EPS))
all_var = tf.trainable_variables()
with tf.name_scope("discriminator_train"):
dis_var = [var for var in all_var if var.name.startswith("discriminator")]
dis_optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(dis_loss, var_list=dis_var) #定义D的优化
with tf.name_scope("generator_train"):
gen_var = [var for var in all_var if var.name.startswith("generator")]
gen_optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(gen_loss, var_list=gen_var) #定义G的优化
return dis_optimizer,gen_optimizer,dis_loss,gen_loss,gen_outputs
def read():
files = tf.train.match_filenames_once("./TFrecord/data-tfrecords-*")
filename_queue = tf.train.string_input_producer(files,shuffle=True) #将files输入到一个队列
reader =tf.TFRecordReader()
_,serialize_example = reader.read(filename_queue) #从队列中读出数据
features = tf.parse_single_example(
serialize_example,
features={
'height':tf.FixedLenFeature([],tf.int64),
'width':tf.FixedLenFeature([],tf.int64),
'channel':tf.FixedLenFeature([],tf.int64),
'image_raw':tf.FixedLenFeature([],tf.string)
})
image_raw = features['image_raw'] #读入图片数据
decoded_image = tf.decode_raw(image_raw,tf.uint8) #将字符串形式的数据解码
images = tf.reshape(decoded_image,[96,96,3]) #重新定义shape
return images
def main():
batch_size = 64 #定义一个batch的大小
gen_inputs = tf.placeholder(tf.float32,[None,noises_size]) #定义Generator的输入
dis_inputs = tf.placeholder(tf.float32,[None,96,96,3]) #定义Discriminator的输入
dis_optimizer,gen_optimizer,dis_loss,gen_loss,gen_output= create_model(gen_inputs,dis_inputs,0.0002) #创建模型
gen_images = (gen_output + 1) * 127.5 #将Generator的输出转化为可以显示的图像
gen_images = tf.cast(gen_images,tf.int32)
images = read()
images = tf.cast(images,tf.float32)
images_input = images / 127.5 - 1 #将图像数据范围变成-1-1之间
images_batch = tf.train.batch([images_input],batch_size=batch_size,capacity=5000) #把image按batch输出,这里会按多线程加快读取速度
#注意这里的[]不可省略
saver = tf.train.Saver()
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8) #定义占用GPU的内存比例
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) as sess:
tf.local_variables_initializer().run()
tf.global_variables_initializer().run() #变量初始化
coord =tf.train.Coordinator() #Coordinator类用来帮助多个线程协同工作,多个线程同步终止
threads = tf.train.start_queue_runners(coord=coord)
steps = 0
while True:
cur_batch = sess.run(images_batch) #产生一个batch
noises = np.random.uniform(-1,1,size=(batch_size,noises_size)).astype(np.float32) #产生一个噪声
for i in range(2):
_,discriminator_loss = sess.run([dis_optimizer,dis_loss],feed_dict={gen_inputs:noises,dis_inputs:cur_batch}) #训练Discriminator
_,generator_loss = sess.run([gen_optimizer, gen_loss],feed_dict={gen_inputs:noises}) #训练Generator
#训练过程会出现D过弱或过强的现象,可以通过加大D的训练次数
#或者调整learning rate 来达到平衡
if steps % 20 == 0:
print("%d steps: gen_loss is %f; dis_loss is %f" % (steps,float(generator_loss),float(discriminator_loss))) #每训练20个batch输出一遍loss
if steps % 100 == 0: #每训练100个batch保存一张图片
now_image =sess.run(gen_images,{gen_inputs:noises})
plt.imshow(now_image[0].astype(np.uint32))
#plt.show()
plt.savefig("./result/R_%d.png" % steps)
saver.save(sess,"./Models1/model.ckpt")
steps += 1
coord.request_stop()
coord.join(threads) #终止线程
main()
生成的结果:
我选取了几张比较成功的:



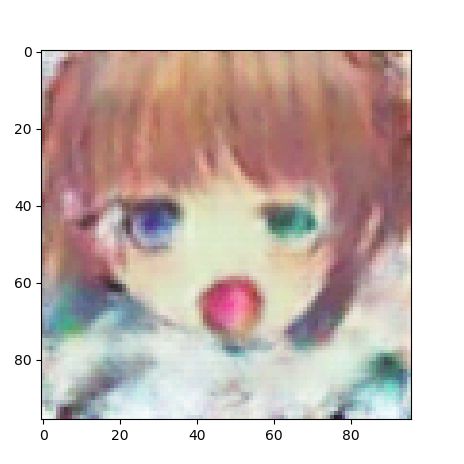


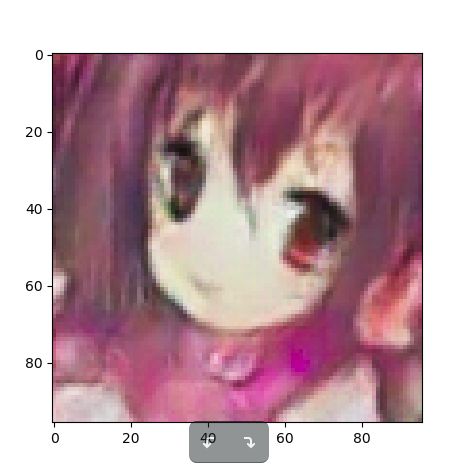

可以看到训练效果还算可以,但还是比不上训练的数据好。实际上,一开始我的网络并不是DCGAN,是从pix2pix抄取了一部分,也能生成类似的结果,但是后来我把网络改造了一下比之前参数更多更强,希望生成更好的结果,但是却再也没训练出来头像,所以网络还是不能乱改的,这大概是一门玄学,我还需学习。
然后列几个心得吧:
1.学习写tensorflow时候,首先要搞清楚基本概念,计算图和variable,在程序开始训练的时候计算图是已经构建好的,写的generator和discriminator这些函数只是在构建计算图的时候运行了一次,这之后再也不会运行,因为计算图已经保存好了,写成函数的目的主要是更好地分隔不同的功能以及不必再写相同重复使用的步骤,比如卷积解卷积。模型在训练的时候只会训练variable类型的tensor,variable_scope的作用是把变量放入文件夹里,比如我把G的变量全部放进generator命名的文件夹里,训练的时候我把generator文件夹里的所有变量拿出来训练即可。
2.然后是一开始写代码的时候,如果没有自己的套路最好先参考别人的写法,我是借鉴了两个代码的,虽然都没完全看懂,但是写法还是学习到了的,只要形成了自己的写法,剩下的就是改造网络的事情,另外tensorflow的api有点多,特别是解卷积的比较复杂,我尝试的几个api都会报一些错误,所以我就不停的换,所以很多时间是花在这些细节上面的。
最后,为我的第一篇博客撒花 ^ - ^