Sqoop全量增量将数据从SqlServer/MySQL导入HDFS/Hive,再从HDFS/Hive导出到数据库最全总结
最近总结了很全的sqoop应用,有以下内容
1.SqlServer/MySQL全量增量导入HDFS/Hive,
2.HDFS导入hive
3.hdfs导出到SqlServer/MySQL
4.hive导出到hdfs
5.hive导出到SqlServer/MySQL
6.还有以上过程的注意事项、操作过程中可能遇到的错误、改正方法
如有不正确的地方,欢迎各位指正^_^;有不太清楚的地方也可以咨询我哦。
目录
1.参数说明
2.全量导入
2.1SqlServer表全量导入hdfs
2.2MySQL表全量导入hdfs
2.3SqlServer表全量导入hive
2.4表全量导入hive
2.5补充说明
3.增量导入
3.1SqlServer表增量导入hdfs
3.1.1 Append模式
3.1.2lastmodified模式
3.2 SqlServer表增量导入hive
4新增其他
4.1HDFS导入Hive
4.2HDFS导出到MySQL
4.3 Hive导出到HDFS
4.4 Hive导出到MySQL
4.5 Hive导出到SqlServer
5语法总结
6问题总结
6.2 ERROR sqoop.Sqoop: Got exception running Sqoop: java.lang.RuntimeException: Could not load db driver
6.3ERROR tool.ImportTool: Import failed: No primary key could be found for table Outwork. Please specify one with --split-by or perform a sequential import with '-m 1'.
6.4ERROR hive.HiveConfig: Could not load org.apache.hadoop.hive.conf.HiveConf. Make sure HIVE_CONF_DIR is set correctly.
6.5Error: java.io.IOException: Cannot run program "mysqldump": error=2, No such file or directory
6.6ERROR manager.SqlManager: Error executing statement: com.microsoft.sqlserver.jdbc.SQLServerException: 在有預期條件的內容中指定的非布林類型運算式,接近 '('
6.7WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification
1.参数说明
--connect : 要连接的数据库JDBC-URL
--username:登录数据库的用户名
--password:登录数据的密码
--table : 需要导出的表
--target-dir :目标目录
--delete-target-dir hdfs导入的目录存在的话先删除
--split-by:字段的分隔符
--columns <列名> :指定列
--where<条件>:指定条件
--query
-m 2 :表示由两个mapper作业执行
--hive-import:导入hive时一定要加此参数,否则无法成功导入hive中
--fields-terminated-by "\t" :是设置每列之间的分隔符
--lines-terminated-by "\n" :设置的是每行之间的分隔符,此处为换行符,也是默认的分隔符
查看hdfs里的文件:hadoop fs -ls hdfs://nameservice/user/root/
删除hdfs里面的文件:hadoop fs -rmr hdfs://nameservice/user/root/t00_test
查看导入hdfs的数据:hadoop fs -cat hdfs://nameservice/user/root/t00_test/part-m-00000
查看导入hive表数据:
hadoop fs -ls hdfs://nameservice/user/hive/warehouse/testhive.db
删除hive表数据:
hadoop fs -rmr hdfs://nameservice/user/hive/warehouse/testhive.db
2.全量导入
2.1SqlServer表全量导入hdfs
直接导入全表
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --table t00_test --fields-terminated-by '\t' -m 1
导入指定列
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --table t00_test --columns 'v00, v01' --where 'v01>5' --fields-terminated-by '\t' -m 1
SQL语句导入指定列
(有条件)
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --target-dir 'hdfs://nameservice/user/root/t00_test1' --query "select v00, v01 from t00_test where v01<50 and \$CONDITIONS" --fields-terminated-by '\t' -m 1
(无条件)
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --target-dir 'hdfs://nameservice/user/root/t00_test1' --query "select v00, v01 from t00_test where \$CONDITIONS" --fields-terminated-by '\t' -m 1
注意
(1)SQL语句必须要用双引号,其他引号可单可双。
(2)必须制定目标文件的位置,--target-dir HDFS目标目录,目录如果设定在本地,则可能会提示权限不足导入失败。
(3)用sql选择导入则必须加入where \$CONDITIONS。
(4)SQL导入就不能再加--table tablename 语句了。
2.2MySQL表全量导入hdfs
跟SqlServer一样,只是数据库这里要稍作一下改变:
sqoop import --connect 'jdbc:mysql://192.168.1.1:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false' --username test --password wells@Test123 --table t00_test --fields-terminated-by "\t" -m 1
2.3SqlServer表全量导入hive
直接导入全表
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --table t00_test --hive-database testhive --hive-import --hive-table t00_test --fields-terminated-by '\t' -m 1
导入指定列
sqoop import --connect 'jdbc:sqlserver://192.168.100.1.1:1433;database=HisData00' --username aaa --password 123 --table t00_test --hive-database testhive --hive-import --hive-table t00_test --columns 'v00, v01' --where 'v01>30' --fields-terminated-by '\t' -m 1
SQL语句导入指定列
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --target-dir 'hdfs://nameservice/user/hive/warehouse/testhive.db/t00_test' --query "select v00, v01 from t00_test where v01<50 and \$CONDITIONS" --hive-database testhive --hive-import --hive-table t00_test --fields-terminated-by '\t' -m 1
2.4MySQL表全量导入hive
直接导入全表
sqoop import --connect 'jdbc:mysql://192.168.1.1:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false' --username test --password wells@Test123 --table t00_test --hive-database testhive --hive-import --hive-table t00_test --direct --fields-terminated-by "\t" -m 1
2.5补充说明
- 重要的前提:要进行导入和导出,首先必须要有访问和写入权限。
- Sqoop直接从MySQL/SQLServer导入表给Hive的时候,如果HDFS里面存在这个表,即使Hive里面没有这个表,也不成功,要删掉HDFS的表才能成功。因为Sqoop直接从MySQL/SQLServer导入到Hive本质是先到HDFS,再到Hive。
- -m后面的数字表示map任务数,如果设为大于1的数,即表示导入方式为并发导入,这时我们必须同时指定- -split-by参数指定根据哪一列来实现哈希分片,从而将不同分片的数据分发到不同 map 任务上去跑,避免数据倾斜。
- 生产环境中,为了防止主库被Sqoop抽崩,我们一般从备库中抽取数据。一般RDBMS的导出速度控制在60~80MB/s,每个map任务的处理速度5~10MB/s 估算,即-m 参数一般设置4~8,表示启动4~8个map任务并发抽取。
- 查看导入成功后的HDFS对应目录上的文件(此HDFS目录事先不需要自己建立,Sqoop会在导入的过程中自行建立,若是不写--target-dir 则默认是hdfs上的user/username/tablename 路径)
3.增量导入
3.1SqlServer表增量导入hdfs
-check-column #指定检索列
-last-value #从该值所在行开始导入
-incremental #指定导入模式
append模式:基于递增列的增量导入(将递增列值大于阈值的所有数据增量导入),只对数据进行附加,不支持更改
lastmodified模式:基于时间列的增量导入(将时间列大于等于阈值的所有数据增量导入),适用于对源数据进行更改,对于变动数据收集,必须记录变动时间
3.1.1 Append模式
增量导入所有列:
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --table t00_test --check-column v00 --last-value '2019-03-6' --incremental append --fields-terminated-by '\t' -m 1
增量导入指定列:
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --table t00_test --check-column v00 --last-value '2019-03-17' --incremental append --columns 'v00, v01' --where 'v01>1' --fields-terminated-by '\t' -m 1
SQL语句增量导入指定列:
(有条件)
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --check-column v00 --last-value '2019-03-17' --incremental append --target-dir 'hdfs://nameservice/user/root/t00_test1' --query "select v00, v01 from t00_test where v01<50 and \$CONDITIONS" --fields-terminated-by '\t' -m 1
(无条件)
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --target-dir 'hdfs://nameservice/user/root/t00_test1' --query "select v00, v01 from t00_test where \$CONDITIONS" --fields-terminated-by '\t' -m 1
3.1.2lastmodified模式
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --table t00_test --check-column v00 --last-value '2019-03-17' --incremental lastmodified --merge-key v00 --fields-terminated-by '\t' -m 1
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --table t00_copy1 --check-column occur --last-value '2015-09-05 13:35:00' --incremental lastmodified --merge-key occur --columns 'occur, v00, v01' --fields-terminated-by '\t' -m 1
特别的
如果last-value指定的值不在表中,则会对这个值进行比较,导出比这个值大的部分,比如这张表
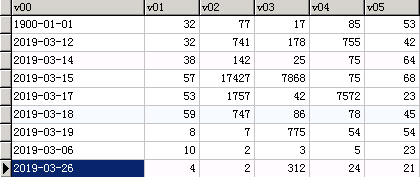
执行--last-value '2019-03-07
3.2 SqlServer表增量导入hive
增量导入所有列:
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --table t00_test --check-column v00 --last-value '2019-03-18' --incremental append --hive-database testhive --hive-import --hive-table t00_test --fields-terminated-by '\t' -m 1
增量导入指定列:
sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --table t00_test --check-column v00 --last-value '2019-03-17' --incremental append --columns 'v00, v01' --where 'v01>1' --hive-database testhive --hive-import --hive-table t00_test --fields-terminated-by '\t' -m 1
4新增其他
4.1HDFS导入Hive
注意:HDFS导入Hive需要提前在Hive中建好要导入的表,可以用SqlServer直接导入一张空表。
hive //进入hive
>use testhive; //进入数据库
>load data inpath 'hdfs://nameservice/user/root/t00_test' into table t00_test;
退出hive用quit;
HDFS导入
4.2HDFS导出到MySQL
MySQL导出的表必须已经存在
sqoop export --connect 'jdbc:mysql://192.168.1.1:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false' --username test --password wells@Test123 --table t00_test1 --export-dir hdfs://nameservice/user/root/t00_test -input-fields-terminated-by '\t' -m 1
4.3 Hive导出到HDFS
>insert overwrite directory 'hdfs://nameservice/user/root/t00_test' row format delimited fields terminated by '\t' select * from t00_test ;
4.4 Hive导出到MySQL
MySQL导出的表必须已经存在
sqoop export --connect 'jdbc:mysql://192.168.1.1:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false' --username test --password wells@Test123 --table t00_test1 --export-dir hdfs://nameservice/user/hive/warehouse/testhive.db/t00_test -input-fields-terminated-by '\t' -m 1
4.5 Hive导出到SqlServer
sqoop export --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --table t00_test1 --export-dir hdfs://nameservice/user/hive/warehouse/testhive.db/t00_test -input-fields-terminated-by '\t' -m 1
5语法总结
(1)对比SqlServer导入hdfs和hive,导入hive只是增加hive数据库和表的说明,即:
--hive-database testhive --hive-import --hive-table t00_test
(2)对比MySQL和SqlServer,连接数据库的方式不完全一样,MySQL要多一些规则:
'jdbc:mysql:// client1:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false'
(3)对比Append和lastmodified,lastmodified因为可以对源数据进行更改,多了唯一主键:--merge-key key
(4)导入hive不支持增量lastmodified方式。会出现如下错误提示:
--incremental lastmodified option for hive imports is not supported. Please remove the parameter --incremental lastmodified.
6问题总结
6.1navicat 连接sql server出现错误提示:未发现数据源名称并且未指定默认驱动程序
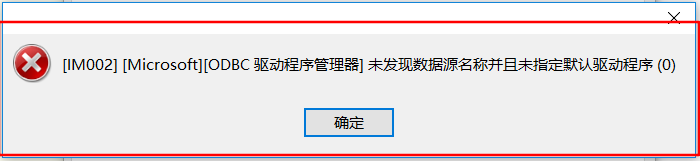
原因是navicat没有安装sqlserver驱动,就在navicat安装目录下,找到如下文件双击安装即可。
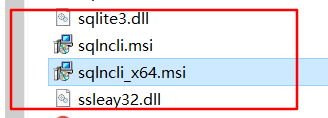
6.2 ERROR sqoop.Sqoop: Got exception running Sqoop: java.lang.RuntimeException: Could not load db driver
解决:把mysql-connector-java 的jar包 复制到 /sqoop/lib 的目录下
cd /opt/cloudera/parcels/CDH-6.0.0/lib/sqoop/lib/
6.3ERROR tool.ImportTool: Import failed: No primary key could be found for table Outwork. Please specify one with --split-by or perform a sequential import with '-m 1'.
解决:在命令中加上-m 1
6.4ERROR hive.HiveConfig: Could not load org.apache.hadoop.hive.conf.HiveConf. Make sure HIVE_CONF_DIR is set correctly.

解决:将hive 里面的lib下的hive-exec-**.jar 放到sqoop 的lib 下
6.5Error: java.io.IOException: Cannot run program "mysqldump": error=2, No such file or directory
命令:sqoop import --connect 'jdbc:mysql://192.168.1.1:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false' --username test --password wells@Test123 --table t00_test --hive-database testhive --hive-import --hive-table t00_test --direct --fields-terminated-by "\t" -m 1
错误:
ERROR manager.SqlManager: Error executing statement: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
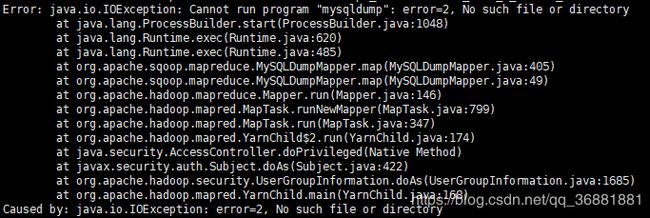
解决方案:
在安装了mysql的节点中使用ROOT用户查找mysqldump在哪个目录下
find / -name mysqldump
将查找到的路径下复杂mysqldump至数据节点B、C、D中
结论:这说明了sqoop导入的2种方式的底层实现不一致,direct的方式需要使用mysqldump命令实现,具体的实现带后续研究
6.6ERROR manager.SqlManager: Error executing statement: com.microsoft.sqlserver.jdbc.SQLServerException: 在有預期條件的內容中指定的非布林類型運算式,接近 '('
命令:sqoop import --connect 'jdbc:sqlserver://192.168.1.1:1433;database=HisData00' --username aaa --password 123 --target-dir 'hdfs://nameservice/user/root/t00_test1' --query 'select v00, v01 from t00_test where \$CONDITIONS' --fields-terminated-by '\t' -m 1

解决:SQL语句改为用双引号。
6.7WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification
解决:这里MySQL数据库信息后面加useUnicode=true&characterEncoding=utf-8&useSSL=false
例:jdbc:mysql:// 192.168.1.1:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false