Java定时爬取数据
刚刚入职一家教育机构,被要求爬取一些学校的新闻到数据库来丰富公司对外系统的页面丰富性,接下来是一些简单的教程。
一.配置文件
applicationContent如下
1000
600000
*/5 * * * * ?
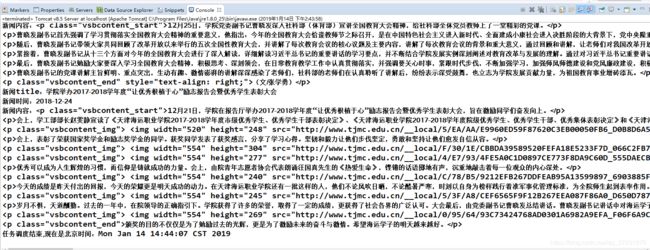
二.了解需要爬取界面的结构。
因为是通过jsoup来获取页面标签对象的,对于不同的网页,需要修改不同的参数。
如果我们需要爬取这个界面的学院新闻模块,应该怎么起手?
因为这个界面比较复杂,一般界面标签会设置id,很容易就定位,但是这个很难做到,而且页面的class都会有重复,最后我实在没办法 只能从单挑新闻起手,doc.getElementsByAttributeValue("class", "c50319")得到对象后获取父类对象.parent(),然后再下一个.nextElementSibling();(如果想要熟练爬取,需要了解jsoup的各种api)
完整代码如下
核心代码
package utils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import entity.News;
public class JsoupTest
{
// public static String url1 = "http://www.zjtongji.edu.cn/xyxw.htm?tdsourcetag=s_pcqq_aiomsg";
// public static String url2 = "http://www.zjtongji.edu.cn/ysdwxx.htm?tdsourcetag=s_pcqq_aiomsg";
public static String url2 = "http://www.tjmc.edu.cn/";
public static void getNewsContent()
{
// List urls = new ArrayList();
// urls.add(url2);
// urls.add(url1);
Document doc = null;
try {
doc = Jsoup.connect(url2).timeout(5000).get();
Elements list = doc.getElementsByAttributeValue("class", "c50319");
for(Element e : list) {
Element time = e.parent().nextElementSibling();
String times = time.text();
System.out.println("新闻title:" + e.attr("title"));
String y = times.substring(1, 3);
if(y.equals("12") || y.equals("08")) {
times = "2018-"+times.substring(1, times.length()-1);
}else {
times = "2019-"+times.substring(1, times.length()-1);
}
System.out.println("新闻时间:" + times);
String element_a_href = e.attr("href");
doc = Jsoup.connect("http://www.tjmc.edu.cn/" + element_a_href).timeout(5000).get();
Element econtent = doc.getElementById("vsb_content");
if(null == econtent) {
econtent = doc.getElementById("vsb_content_2");
}
String content = econtent.html();
content = content.replaceAll("../../images/", "http://www.tjmc.edu.cn/images/");
content = content.replaceAll("/__local/", "http://www.tjmc.edu.cn/__local/");
System.out.println("新闻内容:" + content);
News entity = new News();
entity.setLlbm(properties.getPropertiesByString("xyxwbbm"));
entity.setTitle(e.attr("title"));
entity.setCreateTime(times);
entity.setAuthor("");
entity.setSource("");
entity.setContent(content);
entity.setRemotelogourl(element_a_href);
// jdbcInsertUtils.insertNews(entity);
}
// for(String url: urls) {
// doc = Jsoup.connect(url).timeout(5000).get();
// Elements listDiv = doc.getElementsByAttributeValue("class", "list");
// System.out.println(listDiv.size());
// for(Element listDivElement:listDiv){
// Elements list_li = listDivElement.getElementsByTag("li");
// System.out.println(list_li.size());
// for (Element element_li : list_li) {
// try {
// //获取标题
// Element element_a = element_li.getElementsByTag("a").get(0);
// Element element_span = element_li.getElementsByTag("span").get(0);
// if (element_a.attr("title") != null) if (element_a.attr("title") != "") {
// News entity = new News();
// entity.setTitle(element_a.attr("title"));
// entity.setCreateTime(element_span.text());
// System.out.println("新闻title:" + element_a.attr("title"));
// System.out.println("新闻时间:" + element_span.text());
//
// String element_a_href = element_a.attr("href");
// entity.setLlbm(properties.getPropertiesByString("xyxwbbm"));
// if(element_a_href.contains("1055")){
// entity.setLlbm(properties.getPropertiesByString("xyxwbbm"));
// }else if(element_a_href.contains("1056")){
// entity.setLlbm(properties.getPropertiesByString("ysdwxxbbm"));
// }
//
// doc = Jsoup.connect("http://www.zjtongji.edu.cn/" + element_a_href).timeout(5000).get();
//
// Element econtent = doc.getElementById("vsb_content");
// if(null == econtent) {
// econtent = doc.getElementById("vsb_content_2");
// }
// String content = econtent.html();
//
// content = content.replaceAll("/images/", "http://www.zjtongji.edu.cn/images/");
// content = content.replaceAll("/__local/", "http://www.zjtongji.edu.cn/__local/");
// System.out.println("新闻内容:" + content);
// entity.setAuthor("");
// entity.setSource("");
// entity.setContent(content);
// entity.setRemotelogourl(element_a.attr("href"));
// jdbcInsertUtils.insertNews(entity);
// }
// } catch (Exception e) {
// System.out.println(e.fillInStackTrace());
// }
// }
// }
// }
}
catch (Exception e)
{
System.out.println(e.fillInStackTrace());
}
}
public static void main(String[] args)
throws Exception
{
getNewsContent();
// String x = "[12-31]";
// System.out.println(x.substring(1, 2));
}
}
上面的jdbcInsertUtils.insertNews(entity);是将我爬取的新闻保存到数据库,还有对于图片路径的处理,爬取的时候一定要加上域名!!!
定时任务的代码,顺便将爬取时间统计
package jobs;
import java.util.Calendar;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.scheduling.quartz.QuartzJobBean;
import service.ITellingTheTimeService;
import utils.JsoupTest;
public class TellingTheTimeJob extends QuartzJobBean
{
private ITellingTheTimeService tellingTheTimeService = null;
protected void executeInternal(JobExecutionContext arg0)
throws JobExecutionException
{
Calendar now = Calendar.getInstance();
System.out.println("任务调度开始,现在是北京时间:" + now.getTime());
System.out.println("1213");
JsoupTest test = new JsoupTest();
JsoupTest.getNewsContent();
System.out.println("任务调度结束,现在是北京时间:" + now.getTime());
}
public ITellingTheTimeService getTellingTheTimeService() {
return this.tellingTheTimeService;
}
public void setTellingTheTimeService(ITellingTheTimeService tellingTheTimeService)
{
this.tellingTheTimeService = tellingTheTimeService;
}
}
接下来把项目部署到tomcat服务器下面,只要目标url新闻更新,就会插入到数据库里面了;美滋滋啊