(董付国)Python 学习笔记---Python文件操作(1)
第七章:文件操作
- 为了长期保存数据以便重复使用、修改和共享,必须将数据以文件的形式存储到外部存储介质中(如磁盘、U盘、光盘或云盘、网盘、快盘等)中。
- 文件操作在各类应用软件的开发应用中均占有重要的地位:
√ 管理信息系统是使用数据库来存储数据的,而数据库最终还是以文件的形式存储到磁盘或其他存储介质上。
√ 应用程序的配置信息往往也是使用文件来存储的,图形、图像、音频、视频、可执行文件等等也都是以文件的形式存储在磁盘上的。 - 按文件中数据的组织形式把文件分为二进制文件和文本文件两类。
√ 文本文件:文本文件存储的是常规的字符串,由若干文本行组成,通常每行以换行符’\n‘结尾。常规字符串是指记事本或其他文本编辑器能正常显示、编辑并且人类能够直接阅读并理解的字符串,如英文字母、汉字、数字字符串。文本文件可以使用字处理软件如gedit、记事本进行编辑。
√ 二进制文件:二进制文件把对象内容以**字节串(bytes)**进行存储,无法用记事本或其他普通字处理软件直接进行编辑,通常也无法被人类直接阅读和理解,需要使用专门的软件进行解码后读取、显示、修改或执行。常见的如图行图像文件、音视频文件、可执行文件、资源文件、各种数据库文件、各类Office文档等都属于二进制文件。 - 文件内容操作三部曲:打开、读写、关闭
open(file,mode = ‘r’,buffering = -1,encoding = None,errors = None,newline = None,closefd = True,opener = None)
√ 文件名指定了被打开的文件名称。
√ 打开模式指定了打开文件后的处理方式。
√ 缓冲区指定了读写读写文件的缓存模式。0表示不缓存,1表示缓存,如大于1则表示缓冲区的大小。默认值是缓存模式。
√ 参数encoding指定对文本进行编码和解码的方式,只适用于文本模式,可以使用Python支持的任何格式,如GBK、utf8、CP936等等。 - 如果执行正常,open()函数返回1个可迭代的文件对象,通过该文件对象可以对文件进行读写操作。如果指定文件不存在、访问权限不够、磁盘空间不够或其他原因导致创建文件对象失败则抛出异常。
- 下面的代码分别以读、写方式打开了两个文件并创建了与之对应的文件对象。
f1 = open(‘file1.txt’,‘r’)
f2 = open(‘file2.txt’,‘w’) - 当对文件内容操作完成以后,一定要关闭文件对象,这样才能保证所做的任何修改都确实被保存到文件中。
f1.close() - 需要注意的是,即使写了关闭文件的代码,也无法保证文件一定能够正常关闭。例如,如果在打开文件之后和关闭文件之前发生了错误导致程序崩溃,这是文件就无法正常关闭。在管理文件对象时推荐使用with关键字,可以有效避免这个问题。
- 用于文件内容读写时,with语句的用法如下:
with open(filename,mode,encoding) as fp:
#这里写通过文件对象fp读写文件内容的语句 - 另外,上下文管理语句with还支持下面的用法,进一步简化了代码的编写。
with open(‘test.txt’,‘r’) as src,open(‘test_new.txt’,‘w’) as dst:
dst.write(src.read())
7.1 文件基本操作
-
文件打开方式

-
文件对象常用属性

-
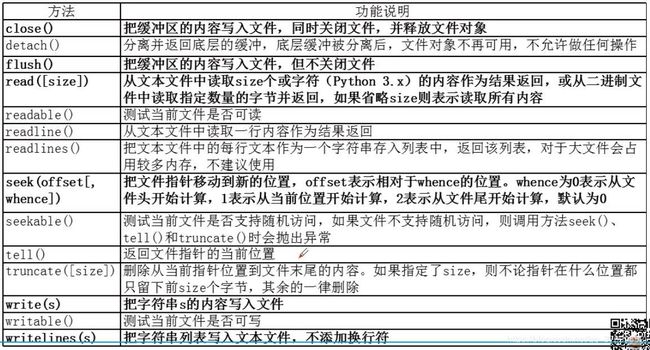
文件对象常用方法
7.2 文本文件操作案例精选
例 7-1 向文本文件中写入内容,然后再读出。
>>> s = 'Hello world\n文本文件的读取方法\n文本文件的写入方法\n'
>>> with open('sample.txt','w') as fp: #默认使用cp936编码
... fp.write(s)
...
32
>>> with open('sample.txt') as fp: #默认使用cp936编码
... print(fp.read())
...
Hello world
文本文件的读取方法
文本文件的写入方法
例 7-4 移动文件指针。
√ Python 2.x和Python 3.x对于seek()方法的理解和处理是一致的,都是把文件指针定位到文件指定字节的位置上。但是由于对中文的支持程度不一样,可能会导致在Python 2.x和Python 3.x中的运行结果有所不同。例如下面的代码实在Python 3.x中运行的,当遇到无法解码的字符会抛出异常。
>>> s = '中国山东烟台SDIBT'
>>> fp = open(r'D:\sample.txt','w')
>>> fp.write(s)
11
>>> fp.close()
>>> fp = open(r'D:\sample.txt','r')
>>> print(fp.read(3))
中国山
>>> fp.seek(2) #移动指针
2
>>> print(fp.read(1))
国
>>> fp.seek(13)
13
>>> print(fp.read(1))
D
>>> fp.seek(3)
3
>>> print(fp.read(1))
Traceback (most recent call last):
File "", line 1, in
UnicodeDecodeError: 'gbk' codec can't decode byte 0xfa in position 0: illegal multibyte sequence
#Python 2.x是以字节为单位,Python 3.x是以字符为单位
例 7.2 读取文本文件data.txt(文件中每行存放一个整数)中所有整数,将其按升序排序后再写入文本文件data_asc.txt中。
with open('data.txt','r') as fp:
data = fp.readlines()
data = [int(line.strip()) for line in data]
data.sort()
data = [str(i) + '\n' for i in data]
with open('data_asc.txt','w') as fp:
fp.writelines(data)
7.3 二进制文件操作案例精选
- 数据库文件、图像文件、可执行文件、音视频文件、Office文档等等均属于二进制文件。
- 必须正确理解二进制文件结构和序列化规则,才能准确地理解二进制文件内容并且设计出正确的反序列化规则。
- 对象序列化后的形式经过正确的反序列过程应该能够准确无误的恢复为原来的对象
- Python中常用的序列化模块有struct、pickle、Marshal和shelve。
>>> import pickle
>>>
>>> i = 13000000
>>> a = 99.056
>>> s = '中国人民123abc'
>>> lst = [[1,2,3],[4,5,6],[7,8,9]]
>>> tu = (-5,10,8)
>>> coll = {4,5,6}
>>> dic = {'a':'apple','b':'banana','g':'grape','o':'orange'}
>>> data = [i,a,s,lst,tu,coll,dic]
>>>
>>> with open('sample_pickle.dat','wb') as f:
... try:
... pickle.dump(len(data),f) #表示后面要写入数据的个数
... for item in data:
... pickle.dump(item,f)
... except:
... print('写文件异常!') #如果写文件异常,则跳到此处执行
例 7.9 读取二进制文件。
>>> import pickle
>>>
>>> i = 13000000
>>> a = 99.056
>>> s = '中国人民123abc'
>>> lst = [[1,2,3],[4,5,6],[7,8,9]]
>>> tu = (-5,10,8)
>>> coll = {4,5,6}
>>> dic = {'a':'apple','b':'banana','g':'grape','o':'orange'}
>>> data = [i,a,s,lst,tu,coll,dic]
>>>
>>> with open('sample_pickle.dat','wb') as f:
... try:
... pickle.dump(len(data),f) #表示后面要写入数据的个数
... for item in data:
... pickle.dump(item,f)
... except:
... print('写文件异常!') #如果写文件异常,则跳到此处执行
...
>>> import pickle
>>> with open('sample_pickle.dat','rb') as f:
... n = pickle.load(f) #读出文件的数据个数
... for i in range(n):
... x = pickle.load(f)
... print(x)
...
13000000
99.056
中国人民123abc
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
(-5, 10, 8)
{4, 5, 6}
{'a': 'apple', 'b': 'banana', 'g': 'grape', 'o': 'orange'}
例 7-10 使用struct模块写入二进制文件。
>>> n = 1300000000
>>> x = 96.45
>>> b = True
>>> s = 'a1@中国'
>>> sn = struct.pack('if?',n,x,b) #序列化
>>> f = open('sample_struct.dat','wb')
>>> f.write(sn)
9
>>> f.write(s.encode()) #字符串直接编码为字节串写入
9
>>> f.close()
>>>>
>>> import struck
Traceback (most recent call last):
File "", line 1, in
ModuleNotFoundError: No module named 'struck'
>>> import struct
>>> f = open('sample_struct.dat','rb')
>>> sn = f.read(9)
>>> tu = struct.unpack('if?',sn)
>>> print(tu)
(1300000000, 96.44999694824219, True)
>>> n,x,bl = tu
>>> print('n = ',n)
n = 1300000000
>>> print('x = ',x)
x = 96.44999694824219
>>> print('bl = ',bl)
bl = True
>>> s = f.read(9).decode()
>>> f.close()
>>> print('s = ',s)
s = a1@中国
7.3.3 使用shelve序列化
>>> import shelve
>>> zhangsan = {'age':38,'Sex':'Male','address':'SXLF'}
>>> lisi = {'age':40,'sex':'Male','qq':'1234567','tel':'7654321'}
>>> with shelve.open('shelve_test.dat') as fp:
... fp['zhangsan'] = zhangsan #以字典形式把数据写入文件
... fp['lisi'] = lisi
... for i in range(5):
... fp[str(i)] = str(i)
...
>>> with shelve.open('shelve_test.dat') as fp:
... print(fp['zhangsan'])
... print(fp['zhangsan']['age'])
... print(fp['lisi']['qq'])
... print(fp['3'])
...
{'age': 38, 'Sex': 'Male', 'address': 'SXLF'}
38
1234567
3
7.3.4 使用marshal序列化
Python标准库marshal也可以进行对象的序列化和反序列化。
>>> import marshal #导入模块
>>> x1 = 30
>>> x2 = 5.0
>>> x3 = [1,2,3]
>>> x4 = (4,5,6)
>>> x5 = {'a':1,'b':2,'c':3}
>>> x6 = {7,8,9}
>>> x = [eval('x'+str(i)) for i in range(1,7)]
>>> x
[30, 5.0, [1, 2, 3], (4, 5, 6), {'a': 1, 'b': 2, 'c': 3}, {8, 9, 7}]
>>> with open('test.dat','wb') as fp:
... marshal.dump(len(x),fp) #先写入对象个数
... for item in x:
... marshal.dump(item,fp)
...
5
5
9
20
17
26
20
>>> with open('test.dat','rb') as fp: #打开二进制文件
... n = marshal.load(fp) #获取对象个数
... for i in range(n):
... print(marshal.load(fp)) #反序列化,输出结果
...
30
5.0
[1, 2, 3]
(4, 5, 6)
{'a': 1, 'b': 2, 'c': 3}
{8, 9, 7}