NLP学习记录——句法分析
句法分析
一般而言,句法分析分为两个主要的方向:
一是句法结构分析,或称成分句法分析、短语句法分析,亦即context-free grammers(CFGs),将语句视为嵌套的短语组合:
Basic unit: words
the, cat, cuddly, by, door
det, N, Adj, P, N
Words combine into phrases
the cuddly cat, by the door
NP -> Det Adj N,PP -> P NP
Phrases can combine into bigger phrases
the cuddly cat by the door
NP -> NP PP
使用语法树表示更为方便:

一是依存分析,研究单词之间的依赖关系:

同样,依存关系也适于用树来表达:
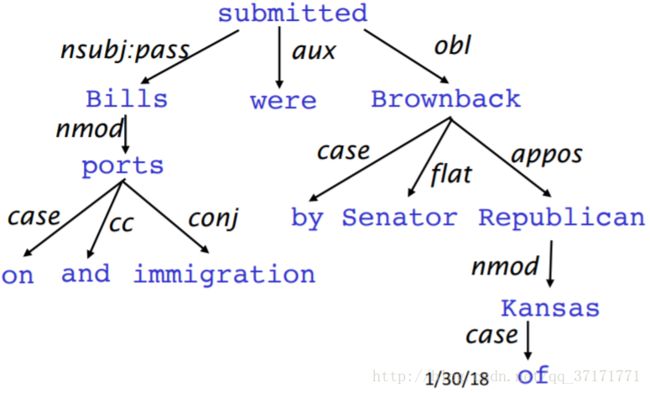
首先来看看CFGs。
CFGs
CFGs的定义包括四个集合:
N:有限的非终端语法标识的集合,亦即语法树上非叶子结点的集合。
S:起始标识
E:有限的终端标识集合,也是语句中所有单词的集合,位于句法树的叶子结点。但是要注意,句法树的叶子节点允许为空。
R:构建句法树的有限个规则的集合,表述了句法树的构建过程。
即G=(N,E,S,R)
例:

基于以上集合可构建句法树:
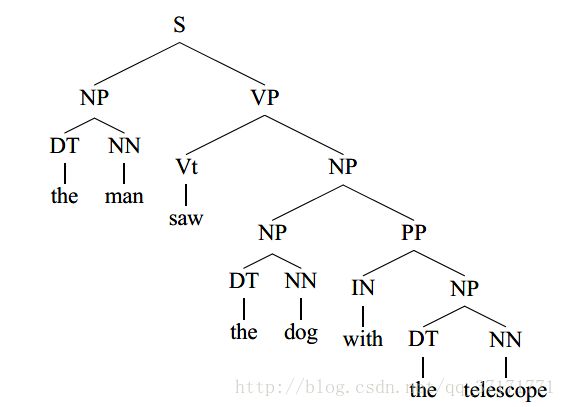
但是,构建过程也可能会有歧义:

left-most derivation是句法树构建过程中的一串序列,例:
s1=S
s2=NP VP.(基于规则s->NP VP)
s3=DT NN VP(nP->DT NN)
s4=the NN VP(DT->the)
s5=the man VP(NN->man)
s6=the man Vi(VP->Vi)
s7=the man sleeps(vi->sleeps)
上述s1,s2…s7即为以下句法树的left-most derivation:

(left-most )derivation实际上是CFGs包含的某一种特定句法树的构造过程,某CFGs有多少种可能的句法树,就有多少种derivation。
PCFGs
Probabilistic Context-Free Grammars ,深度学习爆发前性能最优秀的CFGs分析方法。
设语句s的某个CFGs为G,定义T为G中包含的所有可能的句法树(也可以说是left-most derivations)的集合,T中某一种deviration定义为t,且定义yield(t)=s。
若|T|>1,则语句s是有歧义的,若|T|>0,则语句s是合乎语法的。
RCFGs的核心思路是求T上的概率分布,即求p(t),其中:
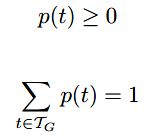
所以,我们的语句分析器就有了一个合理的输出:

定义q(a->b)为R中规则a->b在对非终端a作延伸时的条件概率,即:
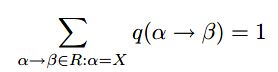
当然,q(a->b)>0。
若T中某个t包含n条规则,则有:
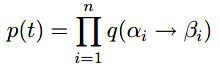
这样,上例对应的PCFGs为(q暂时是假设的):
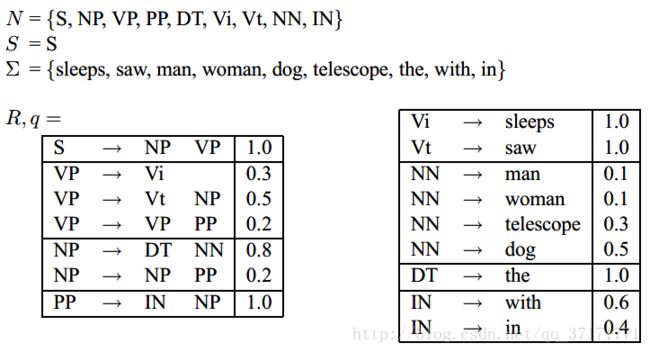
可以看到,从相同的语法标识出发的规则的概率和为1,每次选择规则时遵从一定的概率分布。
那么如何求得q呢?
假设我们的训练集包含句法树t1,t2…tm,其实也是m个devitations,m个规则串,定义训练集的RCFGs:
N为t1,t2…tm中出现过的所有非终端语法标识。
E为t1,t2…tm中所有的单词,即m个yield(t)语句中的单词的集合。
S为起始标识S。
R为t1,t2…tm中所有的规则a->b的集合。
依然利用频率估计:
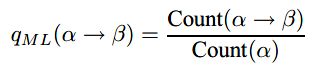
count(a->b)为规则a->b出现的次数,count(a)为a出现的次数。
最后使用CKY算法做以下决策:
![]()
CKY算法是一种动态规划算法,设语句为s=x1,x2…xn,定义T(i,j,X)为基于词序列xi…xj的所有句法树,X∈N是树的根结点。定义:

且当T(i,j,X)为空时π(i, j, X) =0。
显然,

即为所求。
接下来利用递归思想求解。
起始状态:

找到一个不为0的π后开始递归拓展:
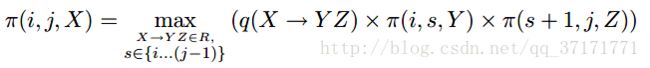
直到i=1,j=n。
以下为算法全貌:

目前这个PCFGs有两个主要的问题。
一是词法信息不敏感,单词的选取仅仅依赖最底层的句法标识,而不是跟整个句法树相关,这显然是不合理的。例如,统计显示,单词into直连PPs句法标识时继续向上连接VP的概率是连接NP概率的九倍,但是此模型并没有这种跨层的概率信息。
一是缺乏对结构偏好的敏感度。例如,对于”president of a company in Africa”,句法标识为PP的短语”in Africa”更倾向于修饰离他最近的NP”a company”,而不是远一些的”president”,这种结构偏好未在模型中体现。
针对第一个问题,提出了lexicalized PCFGs ,将非终端句法标识换成带单词的句法标识,即:
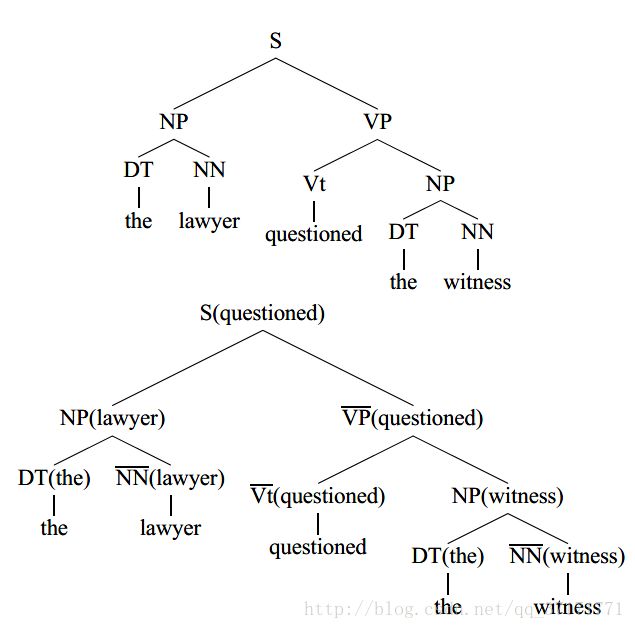
当然,句法标识上的单词并不是随便选择的,而是要选择规则的中心词,例如,”the lawyer”中的中心词显然是”lawyer”,在上例中,所有的中心词的句法标识都加上了横杠。
选择中心词的规则有很多,下面是一个从NP出发的中心词选择规则例子:

那么,现在可以给出lexicalized PCFGs的完整定义:
G=(N,E,R,S,q,y)
N:有限的非终端句法标识集合
E:有限的终端单词集合
S:起始标识
R:规则集合,此时规则有三种情况(X,Y1,Y2∈ N,h,m∈ E,h为中心词):
1.X(h)->Y1(h)Y2(m)
2.X(h)->Y1(m)Y2(h)
3.X(h)->h
q(r)为规则r在确定的规则起点的条件下的概率。
y为X∈ N和h∈ E的联合概率分布,y(X,h)>0且
![]()
这里要考虑到,一但起始标识S处的单词确定了,整棵句法树上的单词也就确定了,所以,对于deviration为r1,r2…rN的句法树,其概率为:
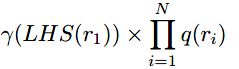
其中LHS(r1)指r1的起点。
句法树的起点单词可看作为整个语句的中心词,代表着语句的某种语义或者特征,这也是句法分析的一个作用,即提取语句的信息。
接下来以规则S(examined) →NP(lawyer) VP(examined))为例说明q的计算。
q(S(examined)→NP(lawyer) VP(examined))
=p(r=s->NP VP,m=lawyer|X=S,h=examined)
=p(r=s->NP VP|X=S,h=examined)*p(m=lawyer|r=s->NP VP,X=S,h=examined)
对于前一项概率,有:
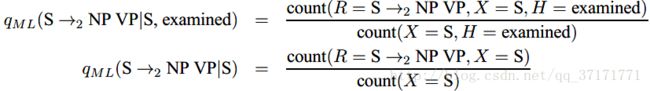
与语言模型中的平滑方法类似,所求概率利用
![]()
进行估计。
对于后一项概率,有:
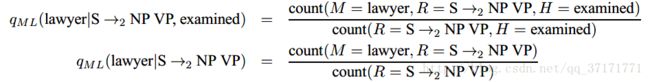
同样。利用
![]()
进行估计。
同样使用CKY算法,定义π(i,j,h,X)为基于词序列xi…xj的,以X为根节点且xh为根节点的单词的条件下,概率最大的句法树。
那么,所求为:
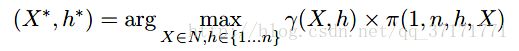
以下为lexicalized PCFGs的算法全貌:

其中figure 8指:

目前出现了很多基于句法树构建神经网络的方法,可以有效利用句法生成单词之上的更高层次的语义向量,例如短语向量和语句向量。
transition-based dependency parser
接下来介绍一种目前最高效的依存分析方法——基于转移的依存分析。
首先定义一个栈σ和一个队列β,栈σ初始化后仅含[ROOT]标记,即依存关系树的根结点标记,队列β初始化为输入词序列。
然后定义一个集合A:表现依存关系的箭头,即依存弧的集合,初始为空。
以wi表示栈或队列中的某个单词,最后定义三种操作:

例:
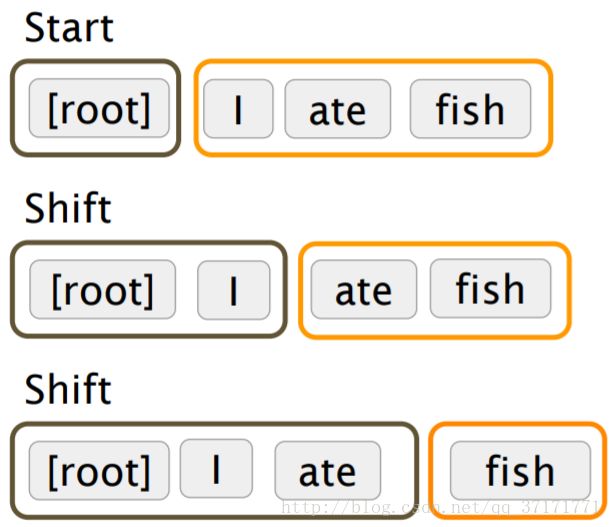

这样就成功建立了依存关系树,那么核心问题就来到如何预测三种操作。
14年提出了一个非常简单高效的神经网络预测方法,模型如下:

原方法中,输入是栈顶的两个单词和他们的四个子结点单词,加上队列头部的一个单词,以此贪心地预测下一个操作。
不过,输入中每个单词的并不是单纯以词向量表示,还包括句法标记和已有的依存弧信息,均已向量化:
