Tensorflow 图片爬虫和迁移学习代码示例
说到迁移学习,讲的通俗点就是,利用别人的已经训练过的,只要训练结尾,就可以快速训练模型,就是站在巨人的肩膀上做事的道理!话不多说,直接看代码!在这里重重感谢莫烦老师!注:我的开发环境是VS2017!
这个例子是区分猫和老虎的例子!首先,我们需要准备大量猫和老虎的照片,这里可以百度图片里爬虫得到!
def Search(name,localpath,page):
os.makedirs(localpath, exist_ok=True)
params = {
'tn' : 'resultjsonavatarnew',
'ie' : 'utf-8',
'cg' : '',
'itg' : '',
'z' : '0',
'fr' : '',
'width' : '',
'height' : '',
'lm' : '-1',
'ic' : '0',
's' : '0',
'word' : name,
'st' : '-1',
'gsm' : '',
'rn' : '30'
};
params['pn'] = '%d' % page
Request(params,localpath)
return ;
def Request(param,path):
searchurl = 'http://image.baidu.com/search/avatarjson'
response = requests.get(searchurl,params =param )
json = response.json()['imgs']
for i in range(0,len(json)):
filename = os.path.split(json[i]['objURL'])[1]
Download(json[i]['objURL'],filename,path)
def Download(url,filename,filepath):
path = os.path.join(filepath,filename)
try:
urlretrieve(url,path)
print('Downloading Images From ', url)
except:
print('Downloading None Images!')
if __name__ =='__main__':
for i in range(0,25):
Search('老虎','data/tiger',i)
Search('猫','data/cat',i)
运行 以上这个例子,就可以到很多图片,这里我会在发表一篇博客,详细解释和感谢给予我知识的人!或者直接到我的百度云里下载*************************链接:我们用到的训练样例---百度云:点击打开链接
下面步入我们的重点 -----迁移学习:我用的是 vgg16 别人训练好的一半模型,在加上一部分自己的,就构成了自己的一套模型!
我们用到的vgg16.npy --百度云:点击打开链接
我们逐行解释
代码如下:
import requests
from urllib.request import urlretrieve
import os
import numpy as np
import tensorflow as tf
import skimage.io
import skimage.transform
import matplotlib.pyplot as plt
#这段代码是将文件夹中的图片读出来,并且统一好规格,224*224的规格
def load_img(path):
img = skimage.io.imread(path)
img = img / 255.0
short_edge = min(img.shape[:2])
yy = int((img.shape[0] - short_edge) / 2)
xx = int((img.shape[1] - short_edge) / 2)
crop_img = img[yy: yy + short_edge, xx: xx + short_edge]
resized_img = skimage.transform.resize(crop_img, (224, 224))[None, :, :, :] # shape [1, 224, 224, 3]
return resized_img
#这里指从图片中读取数据,并且我们自己规定身体长度为一种结果特征,以此来进行区别和训练,注意这里只是指一种条件,方便训练,事实上也可以多种或者其他的条件!
def load_data():
imgs = {'tiger': [], 'cat': []}
for k in imgs.keys():
dir = 'data/' + k
for file in os.listdir(dir):
if not file.lower().endswith('.jpg'):
continue
try:
resized_img = load_img(os.path.join(dir, file))
except OSError:
continue
imgs[k].append(resized_img)
if len(imgs[k]) == 400:
break
print('***',k, len(imgs[k]))
tigers_y = np.maximum(36, np.random.randn(len(imgs['tiger']), 1) * 32 +180)
cat_y = np.maximum(10, np.random.randn(len(imgs['cat']), 1) * 8 + 40)
return imgs['tiger'], imgs['cat'], tigers_y, cat_y
#这里就是训练的和预测的主体部分了
class Vgg16:
vgg_mean = [103.939, 116.779, 123.68]
def __init__(self,vgg16_npy_path= None,restore_from=None, **kwargs):
try:
self.data_dict = np.load(vgg16_npy_path, encoding='latin1').item() #这里我们将vgg16.npy里的参数导入
except FileNotFoundError:
print('Something error about the vgg_npy')
self.tfx = tf.placeholder(tf.float32, [None, 224, 224, 3])
self.tfy = tf.placeholder(tf.float32, [None, 1])
red, green, blue = tf.split(axis=3, num_or_size_splits=3, value=self.tfx * 255.0)
#这里需要将图片的rgb格式转化为bgr格式。
bgr = tf.concat(axis=3, values=[
blue - self.vgg_mean[0],
green - self.vgg_mean[1],
red - self.vgg_mean[2],
])
#这里我们都是再用vgg16.npy中的参数来进行前面部分的训练和预测
conv1_1 = self.conv_layer(bgr, "conv1_1")
conv1_2 = self.conv_layer(conv1_1, "conv1_2")
pool1 = self.max_pool(conv1_2, 'pool1')
conv2_1 = self.conv_layer(pool1, "conv2_1")
conv2_2 = self.conv_layer(conv2_1, "conv2_2")
pool2 = self.max_pool(conv2_2, 'pool2')
conv3_1 = self.conv_layer(pool2, "conv3_1")
conv3_2 = self.conv_layer(conv3_1, "conv3_2")
conv3_3 = self.conv_layer(conv3_2, "conv3_3")
pool3 = self.max_pool(conv3_3, 'pool3')
conv4_1 = self.conv_layer(pool3, "conv4_1")
conv4_2 = self.conv_layer(conv4_1, "conv4_2")
conv4_3 = self.conv_layer(conv4_2, "conv4_3")
pool4 = self.max_pool(conv4_3, 'pool4')
conv5_1 = self.conv_layer(pool4, "conv5_1")
conv5_2 = self.conv_layer(conv5_1, "conv5_2")
conv5_3 = self.conv_layer(conv5_2, "conv5_3")
pool5 = self.max_pool(conv5_3, 'pool5')
#事实上,我们训练的部分只有一下两个神经网络层,但这两个就足以我们训练自己的模型了
self.flatten = tf.reshape(pool5,[-1,7*7*512])
self.fc_6 = tf.layers.dense(self.flatten,256,tf.nn.relu,name = 'fc6')
self.out = tf.layers.dense(self.fc_6,1,name = 'fc_out')
self.sess = tf.Session()
#这里我们进行判断是 区分训练还是预测,这两个方法都要用到整个类,所以这里通过有无文件路径进行了判断
if restore_from:
saver = tf.train.Saver()
saver.restore(self.sess, restore_from)
else: # training graph
self.loss = tf.losses.mean_squared_error(labels=self.tfy, predictions=self.out)
self.train_op = tf.train.RMSPropOptimizer(0.001).minimize(self.loss)
self.sess.run(tf.global_variables_initializer())
return super().__init__(**kwargs)
#这里我们添加我们的卷积层,注意我们里面的参数都是来自于vgg16.npy
def conv_layer(self,conv_in,name):
with tf.variable_scope(name):
conv = tf.nn.conv2d(conv_in,self.data_dict[name][0],[1,1,1,1],padding = 'SAME')
l_out = tf.nn.relu(tf.nn.bias_add(conv,self.data_dict[name][1]))
return l_out
#池化层
def max_pool(self,conv_in,name):
return tf.nn.max_pool(conv_in, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name=name)
#类中的训练函数
def train(self,x,y):
loss,_ = self.sess.run([self.loss, self.train_op], {self.tfx: x, self.tfy: y})
return loss
#类中预测函数
def predict(self,paths):
fig, axs = plt.subplots(1, 2)
for i, path in enumerate(paths):
x = load_img(path)
length = self.sess.run(self.out, {self.tfx: x})
axs[i].imshow(x[0])
if length<80:
animal_ = 'This is a cute cat!'
else:
animal_ = 'This is a fucking tiger!'
axs[i].set_title(animal_+' body length: %.1f cm'% length)
axs[i].set_xticks(()); axs[i].set_yticks(())
plt.show()
#类中保存模型函数
def save(self, path='model/transform_learning'):
saver = tf.train.Saver()
saver.save(self.sess, path, write_meta_graph=False)
#这里是主函数的训练函数,进行整体训练
def main_train():
tigers_x, cats_x, tigers_y, cats_y = load_data()
plt.hist(tigers_y, bins=20, label='Tigers')
plt.hist(cats_y, bins=10, label='Cats')
plt.legend()
plt.xlabel('length')
plt.ion()
plt.show() #显示猫和老虎的身长直方图
xs = np.concatenate(tigers_x+cats_x, axis =0)
ys = np.concatenate((tigers_y,cats_y), axis =0) #这里将数据混合,注意顺序
vgg16 = Vgg16(vgg16_npy_path = 'vgg16.npy') #这里将vgg16.npy添加进来,初始化类
for i in range(100):
batch_idx = np.random.randint(0,len(xs),6)
loss = vgg16.train(xs[batch_idx],ys[batch_idx])
print(i,":get the train loss/",loss)
vgg16.save('model/transform_learning')#这里结束时保存模型
#这是预测函数,我们采用了两张图片来进行预测
def main_to_pred():
vgg_pred = Vgg16(vgg16_npy_path = 'vgg16.npy',restore_from = 'model/transform_learning')
vgg_pred.predict(['pred_data/pred_cat.jpg','pred_data/pred_tiger.jpg'])
#注意主函数,先爬图片,后训练,在预测,分开完成!!!!!!
if __name__ =='__main__':
#for i in range(20,25):
# Search('老虎','data/tiger',i)
# Search('猫','data/cat',i)
main_train()
main_to_pred()
训练得是的样子是这样的:
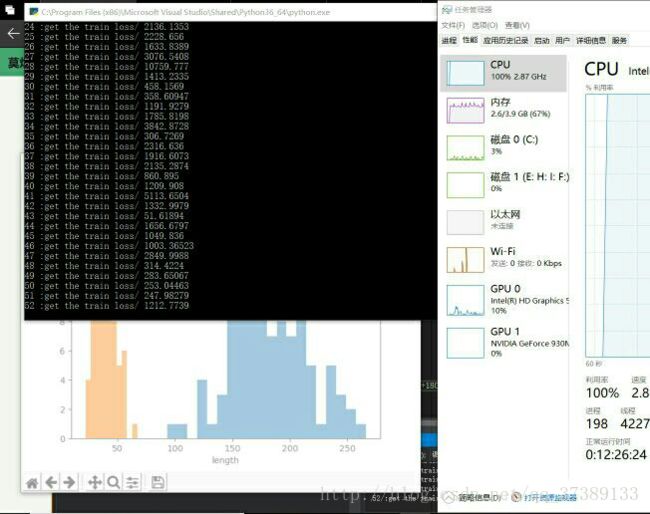
预测时候得样子是这样的

是不是很神奇啊!!
以上就是代码的全部内容,有了一定的Tensorflow CNN得基础,就可以尝试这个代码啦,我只注释了关键得部分,其他语句详细的内容参考:点击打开链接
VGG得相关内容网址:点击打开链接
在这里我要再次感谢莫烦老师,希望大家可以去支持他的工作,他的迁移学习视频链接:点击打开链接