LibROSA库提取MFCC特征的过程解析
目录
源码解析
获取梅尔频谱
分帧
加窗
快速傅里叶变换
梅尔滤波器
取对数
离散余弦变换
总结
LibROSA(本文使用的版本是0.6.3)中的mfcc函数可以用来提取音频的梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCCs)特征,MFCC被广泛应用于语音识别。LibROSA的mfcc函数源码如下:
# -- Mel spectrogram and MFCCs -- #
def mfcc(y=None, sr=22050, S=None, n_mfcc=20, dct_type=2, norm='ortho', **kwargs):
if S is None:
S = power_to_db(melspectrogram(y=y, sr=sr, **kwargs))
return scipy.fftpack.dct(S, axis=0, type=dct_type, norm=norm)[:n_mfcc]对于音频,经典的MFCC提取过程分为预加重、分帧、加窗、快速傅里叶变换(FFT)、梅尔滤波器组过滤、取对数、离散余弦变换(DCT)这几个步骤。从mfcc函数的代码能发掘的信息有限,因此我们需要进一步查看调用的函数代码。以下将从函数调用链的底层往上分析,直到mfcc函数。
源码解析
获取梅尔频谱
分帧
LibROSA提取MFCC的过程没有预加重步骤,而是直接进行了分帧。分帧函数为librosa.util.frame(),源码如下:
def frame(y, frame_length=2048, hop_length=512):
'''Slice a time series into overlapping frames.
This implementation uses low-level stride manipulation to avoid
redundant copies of the time series data.
Parameters
----------
y : np.ndarray [shape=(n,)]
Time series to frame. Must be one-dimensional and contiguous
in memory.
frame_length : int > 0 [scalar]
Length of the frame in samples
hop_length : int > 0 [scalar]
Number of samples to hop between frames
Returns
-------
y_frames : np.ndarray [shape=(frame_length, N_FRAMES)]
An array of frames sampled from `y`:
`y_frames[i, j] == y[j * hop_length + i]`
Raises
------
ParameterError
If `y` is not contiguous in memory, not an `np.ndarray`, or
not one-dimensional. See `np.ascontiguous()` for details.
If `hop_length < 1`, frames cannot advance.
If `len(y) < frame_length`.
'''
if not isinstance(y, np.ndarray):
raise ParameterError('Input must be of type numpy.ndarray, '
'given type(y)={}'.format(type(y)))
if y.ndim != 1:
raise ParameterError('Input must be one-dimensional, '
'given y.ndim={}'.format(y.ndim))
if len(y) < frame_length:
raise ParameterError('Buffer is too short (n={:d})'
' for frame_length={:d}'.format(len(y), frame_length))
if hop_length < 1:
raise ParameterError('Invalid hop_length: {:d}'.format(hop_length))
if not y.flags['C_CONTIGUOUS']:
raise ParameterError('Input buffer must be contiguous.')
# Compute the number of frames that will fit. The end may get truncated.
n_frames = 1 + int((len(y) - frame_length) / hop_length)
# Vertical stride is one sample
# Horizontal stride is `hop_length` samples
y_frames = as_strided(y, shape=(frame_length, n_frames),
strides=(y.itemsize, hop_length * y.itemsize))
return y_frames可以看到,LibROSA实际上调用了scipy库中的numpy.lib.stride_tricks.as_strided函数进行分帧(若不指定,帧长默认为2048,帧移默认为512),as_strided函数的实现就不细究了。LibROSA的frame是将X*1的音频向量处理成N*M的矩阵,即将一个时间序列转化为元素部分重叠的帧序列,若帧数不能整除,则最后补零成完整的帧。举个例子,假设一个音频向量为:[0, 1, 2, 3, 4, 5],若帧长为4,帧移为2,则分帧后得到的矩阵为:[[0, 2] , [1, 3], [2, 4], [3, 5]],每一帧都有4个基本元素。
加窗
对分帧后得到的矩阵,下一步进行加窗(奇怪的是,LibROSA是先加窗后分帧的,在下一个步骤:STFT的代码中会体现)。加窗的目的是为了一定程度消除分帧后出现的帧与帧之间的不连续性。LibROSA的librosa.filters.get_window即为加窗函数,源码如下:
def get_window(window, Nx, fftbins=True):
'''Compute a window function.
This is a wrapper for `scipy.signal.get_window` that additionally
supports callable or pre-computed windows.
Parameters
----------
window : string, tuple, number, callable, or list-like
The window specification:
- If string, it's the name of the window function (e.g., `'hann'`)
- If tuple, it's the name of the window function and any parameters
(e.g., `('kaiser', 4.0)`)
- If numeric, it is treated as the beta parameter of the `'kaiser'`
window, as in `scipy.signal.get_window`.
- If callable, it's a function that accepts one integer argument
(the window length)
- If list-like, it's a pre-computed window of the correct length `Nx`
Nx : int > 0
The length of the window
fftbins : bool, optional
If True (default), create a periodic window for use with FFT
If False, create a symmetric window for filter design applications.
Returns
-------
get_window : np.ndarray
A window of length `Nx` and type `window`
See Also
--------
scipy.signal.get_window
Notes
-----
This function caches at level 10.
Raises
------
ParameterError
If `window` is supplied as a vector of length != `n_fft`,
or is otherwise mis-specified.
'''
if six.callable(window):
return window(Nx)
elif (isinstance(window, (six.string_types, tuple)) or
np.isscalar(window)):
# TODO: if we add custom window functions in librosa, call them here
return scipy.signal.get_window(window, Nx, fftbins=fftbins)
elif isinstance(window, (np.ndarray, list)):
if len(window) == Nx:
return np.asarray(window)
raise ParameterError('Window size mismatch: '
'{:d} != {:d}'.format(len(window), Nx))
else:
raise ParameterError('Invalid window specification: {}'.format(window))从源码中可以看出,LibROSA实际调用了scipy.signal.windows.get_sindow()来进行加窗。scipy库中提供了多种窗函数,如汉明窗、汉宁窗、矩形窗、三角窗等等(想了解scipy库提供的窗函数请点击https://docs.scipy.org/doc/scipy/reference/signal.windows.html?highlight=scipy%20signal%20windows#module-scipy.signal.windows)。LibROSA默认使用汉宁窗,窗函数的详细步骤在此就不细说了。
快速傅里叶变换
经上一步处理后,得到的结果会逐帧进行快速傅里叶变换(fast Fourier transform,FFT)。逐帧进行快速傅里叶变换的过程被称为短时傅里叶变换(short-time Fourier transform 或 short-term Fourier transform,STFT)。LibROSA的librosa.core.stft()源码如下:
def stft(y, n_fft=2048, hop_length=None, win_length=None, window='hann',
center=True, dtype=np.complex64, pad_mode='reflect'):
"""Short-time Fourier transform (STFT)
Returns a complex-valued matrix D such that
`np.abs(D[f, t])` is the magnitude of frequency bin `f`
at frame `t`
`np.angle(D[f, t])` is the phase of frequency bin `f`
at frame `t`
Parameters
----------
y : np.ndarray [shape=(n,)], real-valued
the input signal (audio time series)
n_fft : int > 0 [scalar]
FFT window size
hop_length : int > 0 [scalar]
number audio of frames between STFT columns.
If unspecified, defaults `win_length / 4`.
win_length : int <= n_fft [scalar]
Each frame of audio is windowed by `window()`.
The window will be of length `win_length` and then padded
with zeros to match `n_fft`.
If unspecified, defaults to ``win_length = n_fft``.
window : string, tuple, number, function, or np.ndarray [shape=(n_fft,)]
- a window specification (string, tuple, or number);
see `scipy.signal.get_window`
- a window function, such as `scipy.signal.hanning`
- a vector or array of length `n_fft`
.. see also:: `filters.get_window`
center : boolean
- If `True`, the signal `y` is padded so that frame
`D[:, t]` is centered at `y[t * hop_length]`.
- If `False`, then `D[:, t]` begins at `y[t * hop_length]`
dtype : numeric type
Complex numeric type for `D`. Default is 64-bit complex.
pad_mode : string
If `center=True`, the padding mode to use at the edges of the signal.
By default, STFT uses reflection padding.
Returns
-------
D : np.ndarray [shape=(1 + n_fft/2, t), dtype=dtype]
STFT matrix
See Also
--------
istft : Inverse STFT
ifgram : Instantaneous frequency spectrogram
np.pad : array padding
Notes
-----
This function caches at level 20.
"""
# By default, use the entire frame
if win_length is None:
win_length = n_fft
# Set the default hop, if it's not already specified
if hop_length is None:
hop_length = int(win_length // 4)
fft_window = get_window(window, win_length, fftbins=True)
# Pad the window out to n_fft size
fft_window = util.pad_center(fft_window, n_fft)
# Reshape so that the window can be broadcast
fft_window = fft_window.reshape((-1, 1))
# Check audio is valid
util.valid_audio(y)
# Pad the time series so that frames are centered
if center:
y = np.pad(y, int(n_fft // 2), mode=pad_mode)
# Window the time series.
y_frames = util.frame(y, frame_length=n_fft, hop_length=hop_length)
# Pre-allocate the STFT matrix
stft_matrix = np.empty((int(1 + n_fft // 2), y_frames.shape[1]),
dtype=dtype,
order='F')
fft = get_fftlib()
# how many columns can we fit within MAX_MEM_BLOCK?
n_columns = int(util.MAX_MEM_BLOCK / (stft_matrix.shape[0] *
stft_matrix.itemsize))
for bl_s in range(0, stft_matrix.shape[1], n_columns):
bl_t = min(bl_s + n_columns, stft_matrix.shape[1])
stft_matrix[:, bl_s:bl_t] = fft.rfft(fft_window *
y_frames[:, bl_s:bl_t],
axis=0)
return stft_matrix从stft源码可以看到,LibROSA实际上是先加窗后分帧的,其中原因我也没有仔细研究,留待后续补充吧。源码中,变量fft的类型是一个numpy库的ndarray。逐帧进行快速傅里叶变换时,调用的是scipy或numpy的fft函数,rfft就是实数范围的fft。
经过短时傅里叶变换后,还需要取绝对值,再平方后才能得到能量谱图。这一步骤在librosa.core.spectrum._spectrogram()中:
def _spectrogram(y=None, S=None, n_fft=2048, hop_length=512, power=1,
win_length=None, window='hann', center=True, pad_mode='reflect'):
'''Helper function to retrieve a magnitude spectrogram.
This is primarily used in feature extraction functions that can operate on
either audio time-series or spectrogram input.
Parameters
----------
y : None or np.ndarray [ndim=1]
If provided, an audio time series
S : None or np.ndarray
Spectrogram input, optional
n_fft : int > 0
STFT window size
hop_length : int > 0
STFT hop length
power : float > 0
Exponent for the magnitude spectrogram,
e.g., 1 for energy, 2 for power, etc.
win_length : int <= n_fft [scalar]
Each frame of audio is windowed by `window()`.
The window will be of length `win_length` and then padded
with zeros to match `n_fft`.
If unspecified, defaults to ``win_length = n_fft``.
window : string, tuple, number, function, or np.ndarray [shape=(n_fft,)]
- a window specification (string, tuple, or number);
see `scipy.signal.get_window`
- a window function, such as `scipy.signal.hanning`
- a vector or array of length `n_fft`
.. see also:: `filters.get_window`
center : boolean
- If `True`, the signal `y` is padded so that frame
`t` is centered at `y[t * hop_length]`.
- If `False`, then frame `t` begins at `y[t * hop_length]`
pad_mode : string
If `center=True`, the padding mode to use at the edges of the signal.
By default, STFT uses reflection padding.
Returns
-------
S_out : np.ndarray [dtype=np.float32]
- If `S` is provided as input, then `S_out == S`
- Else, `S_out = |stft(y, ...)|**power`
n_fft : int > 0
- If `S` is provided, then `n_fft` is inferred from `S`
- Else, copied from input
'''
if S is not None:
# Infer n_fft from spectrogram shape
n_fft = 2 * (S.shape[0] - 1)
else:
# Otherwise, compute a magnitude spectrogram from input
S = np.abs(stft(y, n_fft=n_fft, hop_length=hop_length,
win_length=win_length, center=center,
window=window, pad_mode=pad_mode))**power
return S, n_fft_spectrogram函数的power虽然默认值为1,但被上层函数melspectrogram调用时传入的值为2(后面讲到)。
梅尔滤波器
在获得音频的能量谱的同时,还需要构造一个梅尔滤波器组,并与能量谱进行点积运算。梅尔滤波器的作用是将能量谱转换为更接近人耳机理的梅尔频率。LibROSA将其实现于librosa.filters.mel()中:
def mel(sr, n_fft, n_mels=128, fmin=0.0, fmax=None, htk=False,
norm=1, dtype=np.float32):
"""Create a Filterbank matrix to combine FFT bins into Mel-frequency bins
Parameters
----------
sr : number > 0 [scalar]
sampling rate of the incoming signal
n_fft : int > 0 [scalar]
number of FFT components
n_mels : int > 0 [scalar]
number of Mel bands to generate
fmin : float >= 0 [scalar]
lowest frequency (in Hz)
fmax : float >= 0 [scalar]
highest frequency (in Hz).
If `None`, use `fmax = sr / 2.0`
htk : bool [scalar]
use HTK formula instead of Slaney
norm : {None, 1, np.inf} [scalar]
if 1, divide the triangular mel weights by the width of the mel band
(area normalization). Otherwise, leave all the triangles aiming for
a peak value of 1.0
dtype : np.dtype
The data type of the output basis.
By default, uses 32-bit (single-precision) floating point.
Returns
-------
M : np.ndarray [shape=(n_mels, 1 + n_fft/2)]
Mel transform matrix
Notes
-----
This function caches at level 10,
"""
if fmax is None:
fmax = float(sr) / 2
if norm is not None and norm != 1 and norm != np.inf:
raise ParameterError('Unsupported norm: {}'.format(repr(norm)))
# Initialize the weights
n_mels = int(n_mels)
weights = np.zeros((n_mels, int(1 + n_fft // 2)), dtype=dtype)
# Center freqs of each FFT bin
fftfreqs = fft_frequencies(sr=sr, n_fft=n_fft)
# 'Center freqs' of mel bands - uniformly spaced between limits
mel_f = mel_frequencies(n_mels + 2, fmin=fmin, fmax=fmax, htk=htk)
fdiff = np.diff(mel_f)
ramps = np.subtract.outer(mel_f, fftfreqs)
for i in range(n_mels):
# lower and upper slopes for all bins
lower = -ramps[i] / fdiff[i]
upper = ramps[i+2] / fdiff[i+1]
# .. then intersect them with each other and zero
weights[i] = np.maximum(0, np.minimum(lower, upper))
if norm == 1:
# Slaney-style mel is scaled to be approx constant energy per channel
enorm = 2.0 / (mel_f[2:n_mels+2] - mel_f[:n_mels])
weights *= enorm[:, np.newaxis]
# Only check weights if f_mel[0] is positive
if not np.all((mel_f[:-2] == 0) | (weights.max(axis=1) > 0)):
# This means we have an empty channel somewhere
warnings.warn('Empty filters detected in mel frequency basis. '
'Some channels will produce empty responses. '
'Try increasing your sampling rate (and fmax) or '
'reducing n_mels.')
return weights在未指定时,LibROSA默认的梅尔滤波器个数为128。关于梅尔滤波器的知识将在另一篇博文中介绍。
点积运算后即可得到梅尔频谱图,这一步骤体现在librosa.feature.melspectrogram()中:
def melspectrogram(y=None, sr=22050, S=None, n_fft=2048, hop_length=512,
win_length=None, window='hann', center=True, pad_mode='reflect',
power=2.0, **kwargs):
"""Compute a mel-scaled spectrogram.
If a spectrogram input `S` is provided, then it is mapped directly onto
the mel basis `mel_f` by `mel_f.dot(S)`.
If a time-series input `y, sr` is provided, then its magnitude spectrogram
`S` is first computed, and then mapped onto the mel scale by
`mel_f.dot(S**power)`. By default, `power=2` operates on a power spectrum.
Parameters
----------
y : np.ndarray [shape=(n,)] or None
audio time-series
sr : number > 0 [scalar]
sampling rate of `y`
S : np.ndarray [shape=(d, t)]
spectrogram
n_fft : int > 0 [scalar]
length of the FFT window
hop_length : int > 0 [scalar]
number of samples between successive frames.
See `librosa.core.stft`
win_length : int <= n_fft [scalar]
Each frame of audio is windowed by `window()`.
The window will be of length `win_length` and then padded
with zeros to match `n_fft`.
If unspecified, defaults to ``win_length = n_fft``.
window : string, tuple, number, function, or np.ndarray [shape=(n_fft,)]
- a window specification (string, tuple, or number);
see `scipy.signal.get_window`
- a window function, such as `scipy.signal.hanning`
- a vector or array of length `n_fft`
.. see also:: `filters.get_window`
center : boolean
- If `True`, the signal `y` is padded so that frame
`t` is centered at `y[t * hop_length]`.
- If `False`, then frame `t` begins at `y[t * hop_length]`
pad_mode : string
If `center=True`, the padding mode to use at the edges of the signal.
By default, STFT uses reflection padding.
power : float > 0 [scalar]
Exponent for the magnitude melspectrogram.
e.g., 1 for energy, 2 for power, etc.
kwargs : additional keyword arguments
Mel filter bank parameters.
See `librosa.filters.mel` for details.
Returns
-------
S : np.ndarray [shape=(n_mels, t)]
Mel spectrogram
See Also
--------
librosa.filters.mel
Mel filter bank construction
librosa.core.stft
Short-time Fourier Transform
"""
S, n_fft = _spectrogram(y=y, S=S, n_fft=n_fft, hop_length=hop_length, power=power,
win_length=win_length, window=window, center=center,
pad_mode=pad_mode)
# Build a Mel filter
mel_basis = filters.mel(sr, n_fft, **kwargs)
return np.dot(mel_basis, S)取对数
对微小的声音,只要响度稍有增加人耳即可感觉到,但是当声音响度已经大到一定程度后,即使再有较大的增加,人耳的感觉却无明显变化。我们把人耳对声音响度的这种听觉特性称为“对数式”特性。因此,对梅尔频谱图取对数的原因就是为了模拟人耳的“对数式”特性。
LibROSA将这一步骤实现在librosa.core.power_to_db()中:
def power_to_db(S, ref=1.0, amin=1e-10, top_db=80.0):
"""Convert a power spectrogram (amplitude squared) to decibel (dB) units
This computes the scaling ``10 * log10(S / ref)`` in a numerically
stable way.
Parameters
----------
S : np.ndarray
input power
ref : scalar or callable
If scalar, the amplitude `abs(S)` is scaled relative to `ref`:
`10 * log10(S / ref)`.
Zeros in the output correspond to positions where `S == ref`.
If callable, the reference value is computed as `ref(S)`.
amin : float > 0 [scalar]
minimum threshold for `abs(S)` and `ref`
top_db : float >= 0 [scalar]
threshold the output at `top_db` below the peak:
``max(10 * log10(S)) - top_db``
Returns
-------
S_db : np.ndarray
``S_db ~= 10 * log10(S) - 10 * log10(ref)``
See Also
--------
perceptual_weighting
db_to_power
amplitude_to_db
db_to_amplitude
Notes
-----
This function caches at level 30.
"""
S = np.asarray(S)
if amin <= 0:
raise ParameterError('amin must be strictly positive')
if np.issubdtype(S.dtype, np.complexfloating):
warnings.warn('power_to_db was called on complex input so phase '
'information will be discarded. To suppress this warning, '
'call power_to_db(np.abs(D)**2) instead.')
magnitude = np.abs(S)
else:
magnitude = S
if six.callable(ref):
# User supplied a function to calculate reference power
ref_value = ref(magnitude)
else:
ref_value = np.abs(ref)
log_spec = 10.0 * np.log10(np.maximum(amin, magnitude))
log_spec -= 10.0 * np.log10(np.maximum(amin, ref_value))
if top_db is not None:
if top_db < 0:
raise ParameterError('top_db must be non-negative')
log_spec = np.maximum(log_spec, log_spec.max() - top_db)
return log_spec离散余弦变换
最后一步是离散余弦变换(Discrete Cosine Transform,DCT),这一步的目的是改变数据分布,将冗余数据分开。变换后,大部分信号数据将集中在低频区,因此我们通常只需要取变换后的前面一部分数据就可以了(LibROSA的mfcc函数默认取前20个)。
# -- Mel spectrogram and MFCCs -- #
def mfcc(y=None, sr=22050, S=None, n_mfcc=20, dct_type=2, norm='ortho', **kwargs):
"""Mel-frequency cepstral coefficients (MFCCs)
Parameters
----------
y : np.ndarray [shape=(n,)] or None
audio time series
sr : number > 0 [scalar]
sampling rate of `y`
S : np.ndarray [shape=(d, t)] or None
log-power Mel spectrogram
n_mfcc: int > 0 [scalar]
number of MFCCs to return
dct_type : None, or {1, 2, 3}
Discrete cosine transform (DCT) type.
By default, DCT type-2 is used.
norm : None or 'ortho'
If `dct_type` is `2 or 3`, setting `norm='ortho'` uses an ortho-normal
DCT basis.
Normalization is not supported for `dct_type=1`.
kwargs : additional keyword arguments
Arguments to `melspectrogram`, if operating
on time series input
Returns
-------
M : np.ndarray [shape=(n_mfcc, t)]
MFCC sequence
See Also
--------
melspectrogram
scipy.fftpack.dct
"""
if S is None:
S = power_to_db(melspectrogram(y=y, sr=sr, **kwargs))
return scipy.fftpack.dct(S, axis=0, type=dct_type, norm=norm)[:n_mfcc]这一步中LibROSA调用了scipy.fftpack.dct()来做DCT,并取每一帧的前n_mfcc个元素值。
至此,MFCC的提取就完成了。
总结
LibROSA提取MFCC的函数调用链如下图所示:
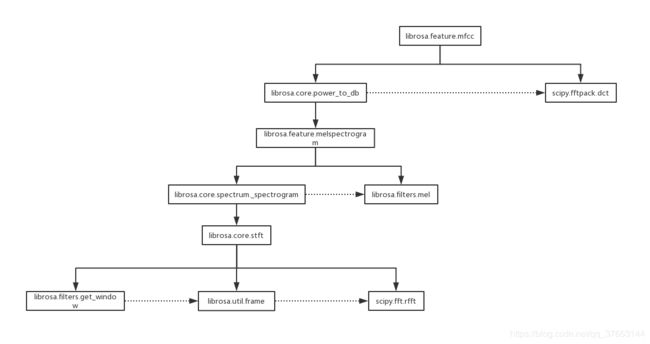 LibROSA提取音频MFCC特征的函数调用链
LibROSA提取音频MFCC特征的函数调用链
前面按照MFCC提取的步骤,逆着调用链解析,发现LibROSA实现的两个特点:没有预加重的过程;不同于其他库从stft→mel就完成了数据降维,LibROSA是留到最后才进行降维。对于第二个特点,这么做的原因、对性能是否会有影响我还没有去深究。
本文的代码摘自LibROSA的官方GitHub:https://github.com/librosa/librosa