近年热门目标检测(Object Detection)算法的总结
总结的算法包括:OverFeat、yolo 系列、SSD、Deformable-ConvNets、R-CNN系列、R-FCN、FPN、SPP-NET
算法综述:

解释one stage和 two stage:
前者是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类;后者则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理。前者在检测准确率和定位精度上占优,后者在算法速度上占优。
目标检测中的评价指标mAP (mean average precision):多个类别物体检测中,每一个类别都可以根据recall(TP/P,x轴)和precision(TP/~P,y轴)绘制一条曲线,AP就是该曲线下的面积,mAP是多个类别AP的平均值。理解目标检测当中的mAP
首先讲two stage
1)R-CNN
Regions with CNN features

缺点:
1)不能端到端;
2)存在大量重复计算(每个候选区域都送入CNN)
具体操作:
1) 输入一张图片,使用Selective Search算法生成2000个候选区域;
2) 对每个大小不同的候选区域,强行resize到227x227,用CNN(Alexnet)提取固定长度(4096维)的特征向量,使用了Fine-Tune的技巧;
3)对特征向量用SVM做二分类,判别目标是否存在,几个目标就训练几个SVM。
4)使用回归器精修候选框的位置;
Selective Search:
1)使用基于图的图像分割方法,生成原始候选区域;
2)从 颜色、纹理、尺寸和空间交叠 四个角度计算候选区域相似度,不断合并最相似的区域。
基于图的分割算法:
1)将图的每个顶点(单个像素点)作为原始分割区域,计算原始分割的内部差(最小边距);
2)计算边距(像素点之间的距离)并升序排序(权重越大,说明顶点的关联性越小);
3)每次处理一条边,如果不在同一分割区域内且小于这个两个区域的最小内部差,则合并这个两个区域;
2)SPP-NET
Spatital Pyramid Pooling 空间金字塔池化(如图d)

金字塔的结构主要是为了从多尺度输入中提取多尺度的信息,但是low level的分类性能较弱。

SPP layer:
对不同大小的输入特征图,用4 * 4、2 * 2、1 * 1的网格分别分割一遍,对每个网格做max pooling,再把这三种结果concat,则可以拿到固定的输出。
3)Fast R-CNN
Fast R-CNN ≈ R-CNN + SPP layer
Faster R-CNN基于R-CNN做出两个改进:
1)R-CNN的resize步骤容易损失图片信息,在Conv 和 FC之间加一层ROI Pooling(即SPP layer),可以输入任意尺寸图片,输出固定长度的特征向量;
2)只对原图片做一次卷积提取特征,不像R-CNN把每个候选框都送入CNN网络,而是通过候选位置去提取相应的特征,提速100倍以上。

缺点:
1)不能端到端。Faster R-CNN 反向传播非常低效,不适合fine-tune(todo,重新想清楚),因为CNN的提取基于一个batch的多张图像,而ROI Pooling每次处理一张图像。
2)selective search 方法生成候选框也十分耗时。
4)RPN
Region Proposal Network
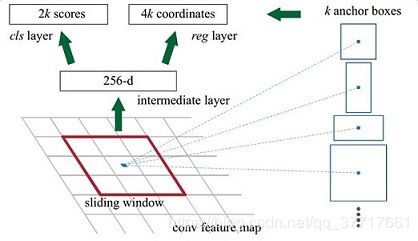
1)anchors。考虑不同的面积比和面积大小的组合,如论文中对每个feature选取k个候选框(k=9),三种比例1:1、1:2、2:1,三种面积128、256、512。
2)从CNN网络中获取图片特征,使用anchors来分割候选区域,根据候选框与任意target框的IOU值是否大于阈值来计算ground truth。
3)随机挑选128个正例,128个负例,做目标检测和边框回归。
5)Faster R-CNN
Faster R-CNN ≈ Fast R-CNN + RPN

- cls_score使用softmax loss,bbox使用smooth L1 loss(todo,为什么用这俩,再做补充)。
- RPN和ROI Pooling结合的细节如下图所示

缺点:
RPN生成的候选框输入到ROI Pooling,做池化后浮点数取整产生了精度问题。
速度对比

6)Mask R-CNN
ICCV 2017,何凯明
Mask R-CNN ≈ Faster R-CNN + 分割任务
改进:
- ROI Pooling 改成ROI Align;
先不做池化, 把RPN生成的边框输入CNN网络得到一个浮点数w和h的feature map,分成k * k网格,对于每个网格采样4份,使用双线性插值计算网格中每一份的中心点,对计算出来的中心点再做最大池化,最后输出的就是k * k的结果,不是浮点数的w和h。参考ROI Align笔记
one stage 算法
7)SSD
8)Yolo v1
9)Yolo v2
10)Yolo v3
OverFeat
论文:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
作者:Yann Lecun及纽约大学团队
年份:CVPR 2013
评价:2013年ImageNet 定位任务冠军,利用滑动窗口和规则块生成候选框,首次将分类、定位以及检测三个计算机视觉任务放在一起解决,解决图像目标形状复杂、尺寸不一问题。
参考博客:论文笔记、OverFeat学习
做法:
- 用一个共享的CNN来同时处理图像分类,定位,检测三个任务,可以提升三个任务的表现。
- 用CNN有效地实现了一个
多尺度(实验最多输入了6个不同尺度的图像)的滑动窗口(使用FCN,预测加入offset max-pooling,但是证明了提升效果不明显)来处理任务。 - 提出
累积预测来求bounding boxes(而不是传统的非极大值抑制)。
分类任务的网络分为两个版本,一个快速版,一个精确版。下图是精确版的网络结构图。
类似于AlexNet,有几点不同,一是没有使用LRN(局部响应归一化),二是没有使用重叠的池化,三是stride的超参用2代替了4,大stride可以提升速度,减小精度。
解释FCN(全卷积,即将全连接层更换为1✖️1卷积)
- 参数量不变;
- 相比传统的滑动窗口一次滑动生成一个窗口,只需要执行一次。

解释offset max-pooling
采用1维做示例,假设在x轴上有20个神经元,如果我们选择池化size=3的非重叠池化,从1位置开始进行分组,每3个连续的神经元为一组,然后计算每组的最大值(最大池化),19、20号神经元将被丢弃,如下图所示:
如果我们只分6组的话,我们除了以1作为初始位置进行连续组合之外,也可以从位置2或者3开始进行组合。也就是说我们其实有3种池化组合方法:
A、△=0分组:[1,2,3],[4,5,6],……,[16,17,18];
B、△=1分组:[2,3,4],[5,6,7],……,[17,18,19];
C、△=2分组:[3,4,5],[6,7,8],……,[18,19,20];
对应图片如下:

拓展到2维(△x,△y),一共9种预测结果,取最大值作为最后结果。
验证集上的分类结果

其中coarse stride表示Δ=0,fine stride表示Δ=0,1,2。
- 使用fine stride可以提升模型表现,但是提升不大,说明实际上offset-pooling在这里的作用不大;
- 使用多scale,增加scale可以提升模型表现;
- 最后多模型融合,又提升了表现。
定位任务把分类任务网络结构的layer 6~output给重新设计一下,把分类改成回归问题,然后在各种不同尺度上训练预测物体的bounding box,根据box和真实box之间的l2损失进行训练。

解释累积预测

累积预测是通过在每个类别计算两个框之间的最短距离进行合并,非极大值抑制每次淘汰与最大概率的框距离近的框。
累积预测不仅去冗余(淘汰低置信度的框),还可以淘汰低连续(多个box相差很远)的类别,会更加鲁棒。
Yolo系列
Yolo v1
论文:You Only Look Once: Unified, Real-Time Object Detection
作者:Joseph Redmon
年份:CVPR 2016
参考博客:论文笔记
You Only Look Once,言简意赅,将目标检测看做是单一的回归问题,将整张图作为输入,直接输入框的四个坐标和类别。
做法:
- 将一幅图像分成
SxS个网格(grid cell),每个网格要预测B个bounding box和类别信息C,一共是B*5+C个值 - 每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值,共
5个值;
注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。
eg:图像输入为448x448,取S=7,B=2,一共有20个类别(C=20)。则输出就是7x7x30的一个tensor。
Ref
知乎专栏:深度学习时代的目标检测算法综述