从爬取豆瓣影评到基于朴素贝叶斯的电影评论情感分析(下)
基于朴素贝叶斯的电影评论情感分析
用到的包:pandas、jieba(分词工具)
file=open(r"review.txt",'r',encoding='utf-8')
reviews=file.readlines()
data=[]
for r in reviews:
data.append([r[0],r[2:]])
d1=pd.DataFrame(data)
pd.set_option('max_colwidth',200)
d1.columns=['sentiment','comment']#修改列名
print('修改列名后的数据(只显示前5行):\n'+str(d1.head()))
print(d1.shape)读取评论文件,转换为DataFrame结构,输出如下:

可以看到评论内容没有标点符号,比较干净。
表有1851行,2列。
接下来将文本分词:
# 清洗数据,通过jieba分词
def word_clean(mytext):
return ' '.join(jieba.lcut(mytext))
x=d1[['comment']]
x['cutted_comment']=x.comment.apply(word_clean)
print(x.shape)
#查看分词后的结果
print('数据分词后的结果:\n'+str(x.cutted_comment[:5]))
y=d1.sentiment
print(y.shape)
print(x.head())输出结果:
 下一步将数据按3:1分为训练集和测试集。
下一步将数据按3:1分为训练集和测试集。
# 将数据集拆开为测试集和训练集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=1)
print('训练集:'+str(x_train.shape)+' '+str(y_train.shape))
print('测试集:'+str(x_test.shape)+' '+str(y_test.shape))可以发现,文本数据中许多词属于无意义词,比如:一些、一个、如果、非常等等,这些称之为停用词,需要将这些词去除。网上可以下载到stopwords.txt文件。
首先,获取停用词表
#获取停用词列表
def get_custom_stopwords(fpath):
with open(fpath) as f:
stopwords=f.read()
stopwords_list=stopwords.split('\n')
return stopwords_list
stopwords=get_custom_stopwords(r'stopwords.txt')然后对比一下不去停用词和去掉停用词后矩阵的特征数量的变化:
#不去停用词
from sklearn.feature_extraction.text import CountVectorizer
vect=CountVectorizer()
term_matrix=pd.DataFrame(vect.fit_transform(x_train.cutted_comment).toarray(),columns=vect.get_feature_names())
print('原始的特征数量:'+str(term_matrix.shape))输出:![]()
#去除停用词
vect = CountVectorizer(stop_words=frozenset(stopwords))
term_matrix = pd.DataFrame(vect.fit_transform(x_train.cutted_comment).toarray(), columns=vect.get_feature_names())
print('去掉停用词的特征数量:'+str(term_matrix.shape))输出: ![]()
特征数量从7225下降到6807,有点效果,但还需进一步处理。
一个特征词如果在80%以上的评论中都出现了,那么这个词就没有很好的区分度(过于平凡),如果出现的过于稀少同样不合适(过于独特),所以我们把特征词出现的频率进行一些限制:
max_df=0.8 # 在超过这一比例的文档中出现的关键词(过于平凡),去除掉。
min_df=3 # 在低于这一数量的文档中出现的关键词(过于独特),去除掉。
vect=CountVectorizer(max_df=max_df,min_df=min_df,stop_words=frozenset(stopwords))
term_matrix = pd.DataFrame(vect.fit_transform(x_train.cutted_comment).toarray(), columns=vect.get_feature_names())
print('进一步处理后的特征数量:'+str(term_matrix.shape))输出:![]()
特征数量降低到了1286个,效果较为显著。
然后用贝叶斯预测分类:
# 使用贝叶斯预测分类
from sklearn.naive_bayes import MultinomialNB
nb = MultinomialNB()
# 利用管道顺序连接工作
from sklearn.pipeline import make_pipeline
pipe=make_pipeline(vect,nb)
#交叉验证的准确率
from sklearn.cross_validation import cross_val_score
cross_result=cross_val_score(pipe,x_train.cutted_comment,y_train,cv=5,scoring='accuracy').mean()
print('交叉验证的准确率:'+str(cross_result))
#进行预测
pipe.fit(x_train.cutted_comment,y_train)
y_pred = pipe.predict(x_test.cutted_comment)
#python测量工具集
from sklearn import metrics
#准确率测试
accuracy=metrics.accuracy_score(y_test,y_pred)
print('准确率:'+str(accuracy))
#混淆矩阵
print('混淆矩阵:'+str(metrics.confusion_matrix(y_test,y_pred)))
输出:
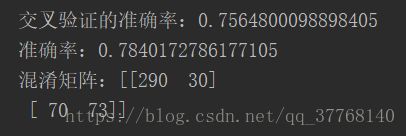
预测准确率达到78.4%。
可能的改进:
1、有的评论是繁体字,需要转化为简体字。
2、否定词的影响。比如“不是很好”分词成了“不是”,“很好”,出现了正向的词。
3、朴素贝叶斯的假设是特征词独立,而这在情感分析中一般不成立。