算法面试通关40讲-总结
文章目录
- 时间复杂度
- 一、数组
- 二、链表
- 特点
- 数组和链表习题
- 三、栈
- 特点
- 四、队列
- 特点
- 栈和队列习题
- 五、优先队列
- 特点
- 优先队列练习题
- 六、Map Vs. Set
- hash练习题
- 七、树、二叉(搜索)树
- 二叉树的练习题
- 八、递归,分治
- 递归分治练习题
- 九、贪心
- 贪心练习题
- 十、广度,深度优先搜索
- 广度,深度优先搜索练习题
- 十一、剪枝
- 十二、剪枝练习题
- 十二、二分查找
- 要求:
- 二分查找练习题
- 十三、Trie 字典树
- 性质
- 字典树练习题
- 十四、位运算
- 异或
- 实战常用的位运算
- 更为复杂的位运算
- 位运算习题
- 十五、动态规划
- 动态规划习题
- 十六、并查集
- 并查集练习题
- 十七、LRU cache
- LFU least frequently used 最近最不常用
- LRU练习题
- 十八、Bloom Filter
- 优点
- 缺点
- 应用
- 十九、代码片段
- 递归
- dfs
- bfs
- 二分
- dp
代码地址:https://github.com/ouyangxizhu/algorithmic_interview_clearance
视频地址:
链接:https://pan.baidu.com/s/1DY44wS3EJXrJYlSuNS0eMA
提取码:4wel
时间复杂度

一、数组
因为内存地址连续,所以访问任意元素时间复杂度O(1),插入和删除元素由于要将后面的元素挪动,其时间复杂度O(n)。(但是插入或者删除最后元素,时间复杂度O(1))。
二、链表
特点
- 为了改善插入和删除元素(经常用)。
- 最开始不知道多少个元素,只需要将新来的元素连接到最后就行了。
数组和链表习题
https://leetcode-cn.com/problems/reverse-linked-list/ ( 206)
https://leetcode-cn.com/problems/swap-nodes-in-pairs/ (24)
https://leetcode-cn.com/problems/linked-list-cycle/ (141)
https://leetcode-cn.com/problems/linked-list-cycle-ii/ (142)
https://leetcode-cn.com/problems/reverse-nodes-in-k-group/ (25)
三、栈
特点
先入后出
四、队列
特点
先进先出
栈和队列习题
https://leetcode-cn.com/problems/valid-parentheses/ (20)
https://leetcode-cn.com/problems/implement-queue-using-stacks/ (232)
五、优先队列
特点
首先是个队列,但是出队列是按照优先级出队的
用堆结构或者二叉搜索树实现的(java是用Fibonacci堆实现的)

优先队列练习题
https://leetcode-cn.com/problems/kth-largest-element-in-a-stream/ (723)
https://leetcode-cn.com/problems/sliding-window-maximum/ (239)
六、Map Vs. Set
Hash 函数用于在O(1)时间内查找
hashmap和hashset是用hash表存的
treemap和treeset是二叉树存的,是有序的
hash练习题
https://leetcode-cn.com/problems/valid-anagram/ (242)
https://leetcode-cn.com/problems/two-sum/submissions/ (1)
https://leetcode-cn.com/problems/3sum/(15)
七、树、二叉(搜索)树
搜索logn,演化过程:单向链表-> 双向链表-> 树->图
二叉搜索树可以是空树或者具有以下性质
- 左子树(不是左节点)上所有节点均小于它的根节点;
- 右子树(不是左节点)上所有节点均大于它的根节点;
- Rucursionly,左右字数分别为二叉查找树
java语言里面实现的树都是红黑树
二叉树的练习题
https://leetcode-cn.com/problems/validate-binary-search-tree/ (98)
https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-search-tree/ (235)
https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/ (236)
八、递归,分治
二叉树其实天然可以用递归解
递归分治练习题
https://leetcode-cn.com/problems/powx-n/ (50)
https://leetcode-cn.com/problems/majority-element/ (169)
九、贪心
适用场景,问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解,这种子问题最优解成为最有子结构
贪心与动态规划的不同在于,动态规划会保存以前的运算结果,并根据以前的结果对当前进行选择,有回退功能(可以存之前的可能成为最优的解),而贪心没有回退功能。
贪心练习题
https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii/ (122)
十、广度,深度优先搜索
可以在树、图中寻找特定节点。
广度优先比较适合人类思维(用的数据结构是队列),深度优先符合计算机的思维(递归的时候是栈,回溯,先一路走到底,不行了再回溯。要是不用递归得用栈维护数据)。
广度,深度优先搜索练习题
https://leetcode-cn.com/problems/binary-tree-level-order-traversal/ (102)
https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/ (104)
https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/ (111)
https://leetcode-cn.com/problems/generate-parentheses/ (22)
十一、剪枝
一般在搜索当中用(一般现实问题当中,有部分不用继续搜索了),有bfs,dfs。
十二、剪枝练习题
https://leetcode-cn.com/problems/n-queens/ (51)
https://leetcode-cn.com/problems/n-queens-ii/ (52)
https://leetcode-cn.com/problems/valid-sudoku/ (36)
https://leetcode-cn.com/problems/sudoku-solver/ (37)
十二、二分查找
要求:
- sorted(单调递增或者递减)
- bounded 存在边界
- accessible by index 可以通过索引访问
二分查找练习题
https://leetcode-cn.com/problems/sqrtx/ (69)
十三、Trie 字典树
又称单词查找或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量字符串(但是不仅限于字符串),经常被用作搜索引擎的文本词频统计。
优点是最大限度减少无谓的字符串比较,查询效率比哈希表高。
空间换时间,利用字符串的公共前缀来减少查询次数。
性质
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。(是路径上的字符,本身没有)
- 每个节点的所有子节点包含的字符都不相同(不重复)
字典树练习题
https://leetcode-cn.com/problems/implement-trie-prefix-tree/ (208)
https://leetcode-cn.com/problems/word-search-ii/ (212)
十四、位运算
因为计算机是二进制,直接进行内存操作,不需要转成十进制,处理速度非常快。

异或
相同为0,不相同为1,即不进位加法

实战常用的位运算

更为复杂的位运算

位运算习题
https://leetcode-cn.com/problems/number-of-1-bits/submissions/ (191)
https://leetcode-cn.com/problems/power-of-two/ (231)
https://leetcode-cn.com/problems/counting-bits/ (338)
https://leetcode-cn.com/problems/n-queens-ii/ (52)
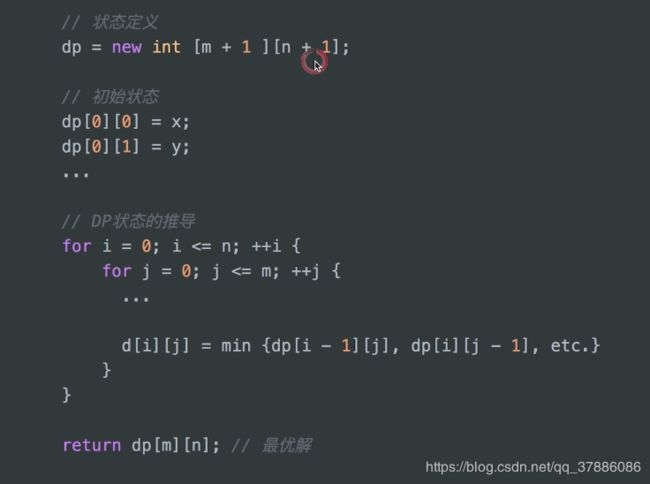
十五、动态规划
- 递推(可以转化为递归 + 记忆化,但是递归会重复计算)
- 定义状态(定义为数组)
- 状态转移方程(通常会有if else)
- 最优子结构(分成前n个最优状态)
/**
* 递归+记忆化--->递推
*/
public class FIb {
/**
* 递归
* 最原始的算法,复杂度2^n
* 因为重复计算了好多数字,可以用一个数字记录,之后直接取出就行了
* @param n
* @return
*/
public int fib(int n){
return n < 1 ? n : fib(n - 1) + fib(n -2);
}
/**
* 递归 + 记忆化
* @param n
* @param memo
* @return
*/
public int fib (int n, int[] memo){
if (n <= 1) return n;
if (memo[n] == 0){
memo[n] = fib(n - 1, memo) + fib(n - 2, memo);
}
return memo[n];
}
/**
* 递归 + 记忆化
* 上面是递归,但是可以从下往上,迭代->递推
* @param n
* @param memo
* @return
*/
public int fib2 (int n, int[] memo){
memo[0] = 0;
memo[1] = 1;
for (int i = 2; i < memo.length; i++){
//状态转移方程
memo[i] = memo[i - 1] + memo[ i - 2];
}
return memo[memo.length - 1];
}
}
回溯(递归)有重复计算,有时候没有最优子结构,只能这么算
贪心–永远局部最优
DP记录局部最优子结构、多种记录值(在过程中计算和选择,在过程中不是只关心当前最优,是回溯和贪心的集大成者)。
动态规划习题
https://leetcode-cn.com/problems/unique-paths-ii/ (63)
https://leetcode-cn.com/problems/climbing-stairs/ (70)
https://leetcode-cn.com/problems/triangle/ (120)
https://leetcode-cn.com/problems/maximum-product-subarray/ (152)
https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock/ (121)
https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii/ (122)
https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-iii/ (123)
https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-iv/ (188)
https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-with-transaction-fee/ (714)
https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-with-cooldown/ (309)
https://leetcode-cn.com/problems/longest-increasing-subsequence/ (300)
https://leetcode-cn.com/problems/coin-change/ (522)
https://leetcode-cn.com/problems/edit-distance/ (72)
十六、并查集
并查集(union & find)是一种树形的数据结构,用于处理一些不交集(Disjoint Sets)的合并和查询问题。
Find:确定元素属于哪个子集,他可以被用来确定两个元素是否属于同一子集
Union:将两个子集合并成同一个集合;
一般用数组实现。
在这里把深度叫做rank
优化1:把深度较低的集合合并到深度较高的集合。.
优化2 : 调用find时进行路径压缩。
并查集练习题
https://leetcode-cn.com/problems/number-of-islands/ (200)
https://leetcode-cn.com/problems/friend-circles/ (547)
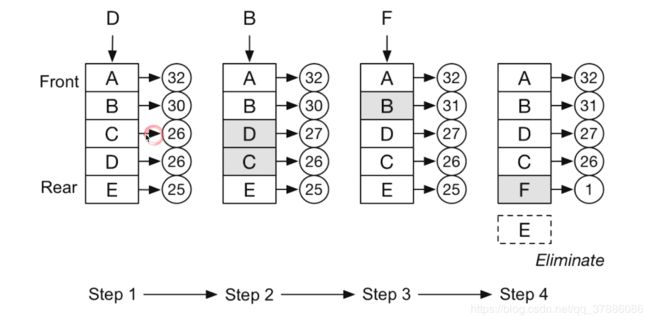
十七、LRU cache
least recently used(最近最少使用)
一般用double linkedlist数据结构
O(1)时间复杂度 查询
O(1)时间复杂度 修改 更新
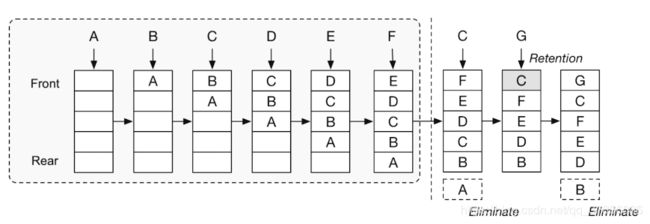
LFU least frequently used 最近最不常用
(里面有属性记录频次,需要使用只是保证在缓存里,但是顺序按照频次排序)
LRU练习题
https://leetcode-cn.com/problems/lru-cache/ (146)
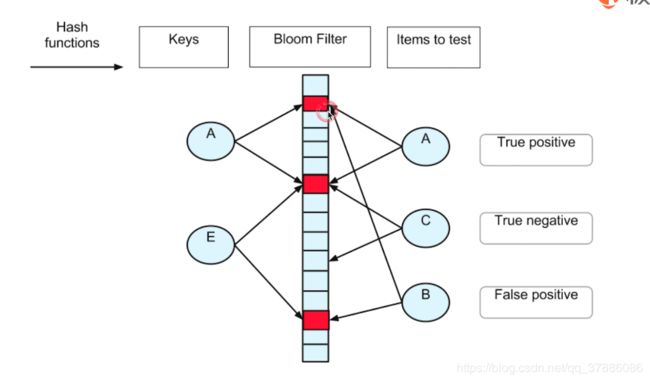
十八、Bloom Filter
相当于缓存,互补(判断是否可能在,还需要一个结构存储判断是否在(准确的))
使用一个很长的二进制向量和一个映射函数(hash)。
用于检索一个元素是否在一个集合中。
优点
空间效率和查询时间都远远超过一般算法。(因为使用二进制,可以先过滤一次)
缺点
有一定的误识别率和删除困难。(判断不在时一定不在,判断在时可能不在)
注:将一个符号散射为多个位置
应用
比特币
分布式系统(map - reduce判断是否在某一个系统中)
十九、代码片段
递归
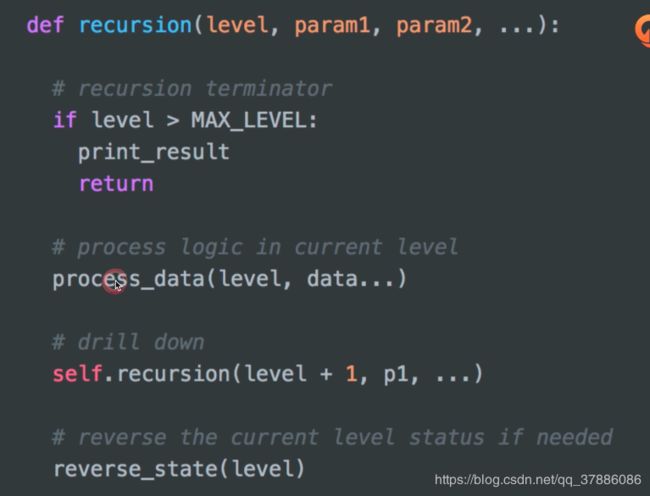
dfs

bfs

二分

dp