spark原理:概念与架构、工作机制
一、Hadoop、Spark、Storm三大框架比较
Hadoop:离线海量数据批处理,基于磁盘的
Spark:基于内存。
Spark特点:运行速度快,使用DAG执行引擎以支持循环数据流与内存计算,
2、容易使用:多种语言编程,通过spark shell进行交互式编程
3、通用性:提供了完整而强大的技术栈,包括sQL查询、流式计算、机器学习和图算法组件
4、运行模式多样:可运行在独立集群模式中,可以运行与hadoop中,也可以运行在AmazonEC2等云环境中,并可以访问HDFS、HBase、Hive等多种数据源
Scala:多范式编程语言
函数式编程(lisp语言,Haskell语言)
运行于java平台(jvm,虚拟机),兼容java程序
scala特性:具备强大的并发性,支持函数式编程,支持分布式系统,
语法简洁,能提供优雅的API
scala兼容java,运行速度快,能融合到hadoop生态圈中。
scala是spark的主要编程语言,提供REPL(交互式解释器),提高程序开发效率
Spark与Hadoop的对比
hadoop的缺点:1、表达能力有限,只能用map和reduce来表示
2、磁盘开销大
3、延迟高,由于要写磁盘,因此延迟高
4、任务之间的衔接涉及IO开销
Spark相对于hadoop MapReduce的优点:
1、不局限于MapReduce,提供多种数据集操作类型,编程模型比Hadoop MapReduce更灵活
2、spark提供内存计算,可将中间结果放到内存中,对于迭代运算效率更高
3、基于DAG的任务调度机制,效率更高
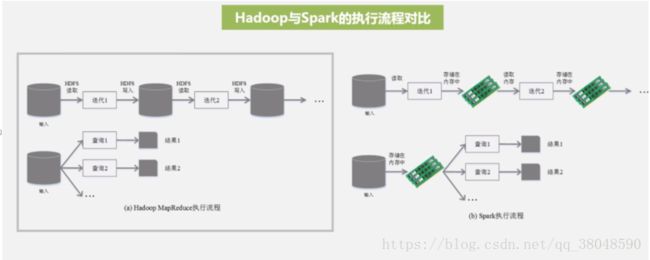
二、Spark生态系统
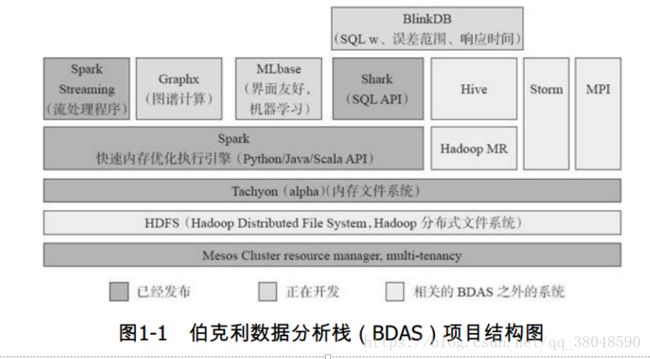
spark生态系统主要包含了Spark Core、SparkSQL、SparkStreaming、MLLib和GraphX等组件。
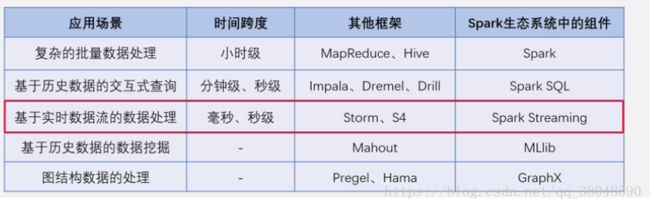
1、海量数据批量处理 MapReduce
2、基于历史数据的交互式查询 Cloudera Impala
3、实时数据流的处理
spark可以部署在资源管理器Yarn之上,提供一站式大数据解决方案
spark可以同时支持海量数据批量处理、历史数据分析、实时数据处理
spark生态系统已经成为伯克利数据分析软件栈(BDAS)

Spark生态系统组件的应用场景
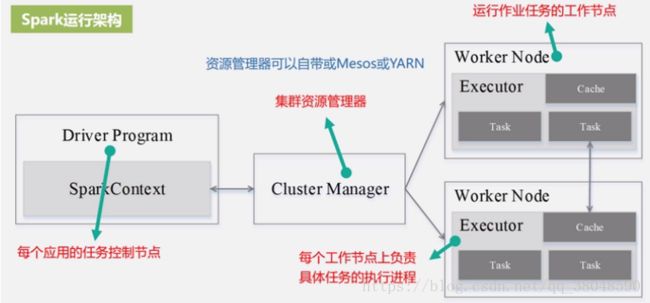
三、Spark运行架构
1、基本概念:RDD、DAG、Executor、Application、Task、Job、Stage
RDD:弹性分布式数据集的简称,是分布式内存的一个抽象概念 ,提供了一个高度共享的内存模型。
和MapReduce相比有两个优点
1、利用多线程来执行具体任务,减少任务的启动开销。
2、同时利用内存和磁盘作为共同的存储设备,有限的减少IO开销。
2、Spark运行基本原理

1、构建基本的运行环境,由dirver创建一个SparkContext,分配并监控资源使用情况
2、资源管理器为其分配资源,启动Excutor进程
3、SparkContext根据RDD 的依赖关系构建DAG图,GAG图提交给DAGScheduler解析成stage,然后提交给底层的taskscheduler处理。
executor向SparkContext申请task,taskscheduler 将task发放给Executor运行并提供应用程序代码
4、Task在Executor运行把结果反馈给TaskScheduler,一层层反馈上去。最后释放资源
运行架构特点:多线程运行、运行过程与资源管理器无关、Task采用了数据本地性和推测执行来优化。
3、RDD概念
设计背景,迭代式算法,若采用MapReduce则会重用中间结果;MapReduce不断在磁盘中读写数据,会带来很大开销。

RDD的典型执行过程
1)读入外部数据源进行创建,分区
2)RDD经过一系列的转化操作,每一次都会产生不同的RDD供给下一个转化擦操作使用
3)最后一个RDD经过一个动作操作进行计算并输出到外部数据源
优点:惰性调用、调用、管道化、避免同步等待,不需要保存中间结果
高效的原因:
1)容错性:现有方式是用日志记录的方式。而RDD具有天生的容错,任何一个RDD出错,都可以去找父亲节点,代价低。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
2)中间结果保存到内存,避免了不必要的内存开销
3)存放的数据可以是java对象,避免了对象的序列化和反序列化。
RDD的依赖关系:窄依赖和宽依赖
窄依赖:(narrow dependency)是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等操作都会产生窄依赖;(独生子女)即rdd中的每个partition仅仅对应父rdd中的一个partition。父rdd里面的partition只去向子rdd里的某一个partition!这叫窄依赖,如果父rdd里面的某个partition会去子rdd里面的多个partition,那它就一定是宽依赖!
宽依赖(shuffle dependency):是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;(超生)每一个父rdd的partition数据都有可能传输一部分数据到子rdd的每一个partition中,即子rdd的多个partition依赖于父rdd。宽依赖划分成一个stage!!!
作用:完成Stage的划分

spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。因此在上图中RDD C,RDD D,RDD E,RDDF被构建在一个stage中,RDD A被构建在一个单独的Stage中,而RDD B和RDD G又被构建在同一个stage中。
Stage的划分:
ShuffleMapStage和ResultStage:
简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中;也就是说上图中的stage1和stage2相当于mapreduce中的Mapper,而ResultTask所代表的stage3就相当于mapreduce中的reducer。
四、Spark SQL
Spark的另外一个组件。先说一下shark(Hive on Spark),为了实现与Hive兼容,在HiveQL方面重用了HIveQL的解析、逻辑执行计划翻译等逻辑,把HiveQL操作翻译成Spark上的RDD操作。相当于在最后将逻辑计划转换为物理计划时将原来转换成MapReduce替换成了转换成Spark。
与spark相比,sparkSQL不再是依赖于Hive,而是形成了一套自己的SQL,只依赖了Hive解析、Hive元数据。从hql被解析成语法抽象树之后,剩下的东西全部是自己的东西,不再依赖Hive原来的组件,增加了SchemaRDD,运行在SchemaRDD中封装更多的数据,数据分析功能更强大。同时支持更多语言,除R语言外,还支持Scala、Java、python语言。
五、Spark安装和部署
1Standalone 2、Spark on mesos 3、spark on yarn
企业中的应用部署

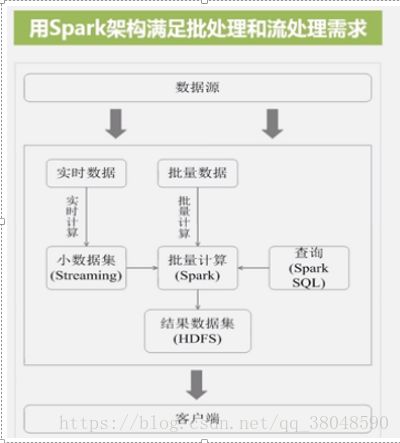
六、spark编程
编写应用程序
1、加载文件到RDD中
2、设置环境变量
3、创建SparkContext
4、转换操作
5、Action计算操作1
6、创建sbt文件
7、使用sbt对其进行打包
8、把jar包提交到spark中运行。