PyTorch实战Kaggle之Dogs vs. Cats
PyTorch实战Kaggle之Dogs vs. Cats
- 目录
- 1. 导包
- 2. 数据载入及装载
- 3. 数据预览
- 1)获取一个批次的数据
- 2)验证独热编码的对应关系
- 3)图片预览
- 4. 模型搭建
- 5. 损失函数、优化函数定义
- 6. 模型训练和参数优化
- 出错
- 输出结果
- 存疑
目录
1. 导包
import torch
from torch.autograd import Variable
import torchvision
from torchvision import datasets, transforms
import os
import matplotlib.pyplot as plt
import time
%matplotlib inline
- torch:定义了许多与神经网络相关的类、函数;
- torch.autograd:完成神经网络后向传播中的链式求导;
- Variable:torch.autograd包中的一个类,将Tensor数据类型变量封装成Variable对象,使得程序能够应用自动梯度的功能;
- torchvision:实现数据的处理、导入和预览等;
- datasets:数据导入;
- transforms:数据处理;
- os:集成了一些对文件路径和目录进行操作的类;
- matplotlib:绘图;
- time:主要是一些和时间相关的类。
2. 数据载入及装载
- 数据
这个数据集的训练数据集中一共有25000张猫和狗的图片,其中猫、狗各12500张。在测试数据集中有12500张图片,其中猫、狗图片无序混杂,且无对应的标签。
官方网站:https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/data
百度云网盘
链接:https://pan.baidu.com/s/1ZfjfBCRjTU4Q1j5ST-k8wQ
提取码:913v - 数据分类存放
在获取全部数据集之后,我们需要对这些数据进行一个简单分类,将测试数据集中的数据分出一部分用作验证集,完成文件的分类之后再运行程序。文件层次结构及存放的数据量如下图所示:
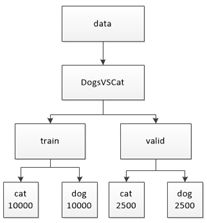
- 载入:可理解为对图片的处理
- 装载:可理解为将图片打包好送给模型进行训练
data_dir = './data/DogsVSCats'
# 定义要对数据进行的处理
data_transform = {x: transforms.Compose([transforms.Resize([64, 64]),
transforms.ToTensor()])
for x in ["train", "valid"]}
# 数据载入
image_datasets = {x: datasets.ImageFolder(root=os.path.join(data_dir, x),
transform=data_transform[x])
for x in ["train", "valid"]}
# 数据装载
dataloader = {x: torch.utils.data.DataLoader(dataset=image_datasets[x],
batch_size=16,
shuffle=True)
for x in ["train", "valid"]}
注:在以上代码中数据的变换和导入都采用了字典的形式,这是因为我们需要分别对训练数据集和验证数据集的数据载入方法进行简单定义,使用字典可以简化代码,也方便之后进行相应的调用和操作。
3. 数据预览
1)获取一个批次的数据
- 代码
X_example, y_example = next(iter(dataloader["train"]))
print(u'X_example个数{}'.format(len(X_example)))
print(u'y_example个数{}'.format(len(y_example)))
print(X_example.shape)
print(y_example.shape)
- 输出结果

- 分析
其中,X_example是Tensor数据类型的变量,因为在上一步图片载入和装载时,对图片大小进行了缩放变换,所以现在图片的大小全部是64×64了。X_example的维度为(16, 3, 64, 64),维度的构成从前往后分别为(batch_size, channel, height, weight)。
y_example也是Tensor数据类型的变量,不过其中的元素值全为0和1,为什么会出现0和1?这是因为在进行数据装载的时已经对dog文件夹和cat文件夹下的内容进行了独热编码(One-Hot Encoding),所以这时的0和1不仅是每张图片的标签,还分别对应猫的图片和狗的图片。
2)验证独热编码的对应关系
- 代码
index_classes = image_datasets["train"].class_to_idx
print(index_classes)
- 输出结果
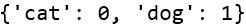
- 分析
由输出结果可见,猫的图片标签和狗的图片标签被独热编码后分别被数字化了,相较于使用文字作为图片的标签而言,使用0和1也可以让之后的计算方便很多。不过,为了增加之后绘制的图片标签的可识别性,我们还需要通过下列代码将原始标签的结果存储在名为example_classes的变量中,代码如下:
example_classes = image_datasets["train"].classes
print(example_classes)
输出结果:
![]()
3)图片预览
- 代码
img = torchvision.utils.make_grid(X_example)
img = img.numpy().transpose([1, 2, 0])
for i in range(len(y_example)):
index = y_example[i]
print(example_classes[index], end=' ')
if (i+1)%8 == 0:
print()
plt.imshow(img)
plt.show()
- 输出结果

4. 模型搭建
基于VGG16架构来搭建一个简化版的VGGNet模型,简化如下:
- 输入图片大小由224×224修改为64×64;
- 删除了连接在一起的两个卷积层和一个池化层;
- 改变了全连接层中的连接参数。
class Models(torch.nn.Module):
def __init__(self):
super(Models, self).__init__()
self.Conv = torch.nn.Sequential(
torch.nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(128, 128, kernel_size=3, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2)
)
self.Classes = torch.nn.Sequential(
torch.nn.Linear(4*4*512, 1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024, 1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024, 2)
)
def forward(self, input):
x = self.Conv(input)
x = x.view(-1, 4*4*512)
x = self.Classes(x)
return x
查看模型细节:
- 代码
model = Models()
print(model)
- 结果

5. 损失函数、优化函数定义
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.00001)
6. 模型训练和参数优化
- 使用CPU计算的代码
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.00001)
epoch_n = 10
time_open = time.time()
for epoch in range(epoch_n):
print("Epoch {}/{}".format(epoch+1, epoch_n))
print("-"*10)
for phase in ["train", "valid"]:
if phase == "train":
print("Training...")
# 设置为True,会进行Dropout并使用batch mean和batch var
model.train(True)
else:
print("Validing...")
# 设置为False,不会进行Dropout并使用running mean和running var
model.train(False)
running_loss = 0.0
running_corrects = 0
# enuerate(),返回的是索引和元素值,数字1表明设置start=1,即索引值从1开始
for batch, data in enumerate(dataloader[phase], 1):
# X: 图片,16*3*64*64; y: 标签,16
X, y = data
# 封装成Variable类
X, y = Variable(X), Variable(y)
# y_pred: 预测概率矩阵,16*2
y_pred = model(X)
# pred,概率较大值对应的索引值,可看做预测结果
_, pred = torch.max(y_pred.data, 1)
# 梯度归零
optimizer.zero_grad()
# 计算损失
loss = loss_f(y_pred, y)
# 若是在进行模型训练,则需要进行后向传播及梯度更新
if phase == "train":
loss.backward()
optimizer.step()
# 计算损失和
running_loss += loss
# 统计预测正确的图片数
running_corrects += torch.sum(pred==y.data)
# 共20000张测试图片,1250个batch,在使用500个及1000个batch对模型进行训练之后,输出训练结果
if batch%500==0 and phase=="train":
print("Batch {}, Train Loss:{:.4f}, Train ACC:{:.4F}%".format(batch, running_loss/batch,
100*running_corrects/(16*batch)))
epoch_loss = running_loss * 16 / len(image_datasets[phase])
epoch_acc = 100 * running_corrects / len(image_datasets[phase])
# 输出最终的结果
print("{} Loss:{:.4f} Acc:{:.4f}%".format(phase, epoch_loss, epoch_acc))
# 输出模型训练、参数优化用时
time_end = time.time() - time_open
print(time_end)
由于使用计算机CPU进行计算耗时过长,所以对代码进行适当调整,将在模型训练过程中需要计算的参数全部迁移至GPUs上。
这个过程非常简单和方便,只需要对这部分参数进行类型转换即可,但在此之前,需要先确认GPUs硬件是否可用,代码如下:
print(torch.cuda.is_available())
若输出结果为True,则说明GPUs具备了被使用的全部条件,若遇到False,则说明显卡暂不支持,需要查看具体问题的所在并进行调整。(此处略过)
- 使用GPUs计算的代码
Use_gpu = torch.cuda.is_available()
# 修改处
if Use_gpu:
model = model.cuda()
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.00001)
epoch_n = 10
time_open = time.time()
for epoch in range(epoch_n):
print("Epoch {}/{}".format(epoch+1, epoch_n))
print("-"*10)
for phase in ["train", "valid"]:
if phase == "train":
print("Training...")
# 设置为True,会进行Dropout并使用batch mean和batch var
model.train(True)
else:
print("Validing...")
# 设置为False,不会进行Dropout并使用running mean和running var
model.train(False)
running_loss = 0.0
running_corrects = 0
# enuerate(),返回的是索引和元素值,数字1表明设置start=1,即索引值从1开始
for batch, data in enumerate(dataloader[phase], 1):
# X: 图片,16*3*64*64; y: 标签,16
X, y = data
# 修改处
if Use_gpu:
X, y = Variable(X.cuda()), Variable(y.cuda())
else:
X, y = Variable(X), Variable(y)
# y_pred: 预测概率矩阵,16*2
y_pred = model(X)
# pred,概率较大值对应的索引值,可看做预测结果
_, pred = torch.max(y_pred.data, 1)
# 梯度归零
optimizer.zero_grad()
# 计算损失
loss = loss_f(y_pred, y)
# 若是在进行模型训练,则需要进行后向传播及梯度更新
if phase == "train":
loss.backward()
optimizer.step()
# 计算损失和
running_loss += loss
# 统计预测正确的图片数
running_corrects += torch.sum(pred==y.data)
# 共20000张测试图片,1250个batch,在使用500个及1000个batch对模型进行训练之后,输出训练结果
if batch%500==0 and phase=="train":
print("Batch {}, Train Loss:{:.4f}, Train ACC:{:.4F}%".format(batch, running_loss/batch,
100*running_corrects/(16*batch)))
epoch_loss = running_loss * 16 / len(image_datasets[phase])
epoch_acc = 100 * running_corrects / len(image_datasets[phase])
# 输出最终的结果
print("{} Loss:{:.4f} Acc:{:.4f}%".format(phase, epoch_loss, epoch_acc))
# 输出模型训练、参数优化用时
time_end = time.time() - time_open
print(time_end)
出错
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 2.00 GiB total capacity; 1.32 GiB already allocated; 16.00 KiB free; 8.34 MiB cached)

- 解决方案:
参考博客:https://blog.csdn.net/qq_42393859/article/details/84372009
(该博客内还有其他解决方法)
将
# 计算损失和
running_loss += loss
修改为:
# 计算损失和
running_loss += float(loss)
输出结果

存疑
- model.train(True)
- model.train(False)
- model.eval()
三者的区别和相应的作用