1、学什么?怎么学? ——> 思想、原理、体系结构(非常重要): 画图
2、搭建环境:一定仔细
3、写程序:
Hadoop、Storm —> Java程序
Spark —> Scala、Java
目的:1、学习内容 2、名词(很多)
==================================================
一、各章概述(Hadoop部分、Storm部分)
(一)、Hadoop的起源与背景知识
1、什么大数据?核心问题?
举例:
(1)商品推荐 问题1:大量的订单如何存储? 问题2:大量的订单如何计算?
(2)天气预报 问题1:大量的天气数据存储? 问题2:大量的天气数据计算?
核心问题:数据存储:分布式存储(HDFS)
数据计算:分布式计算(MapReduce)
==================================================
2、数据仓库一种实现方式。什么是数据仓库?
(*)传统方式:数据仓库
(*)数据仓库就是一个数据库,比较大,可以是Oracle、MySQL
(*)一般只做select
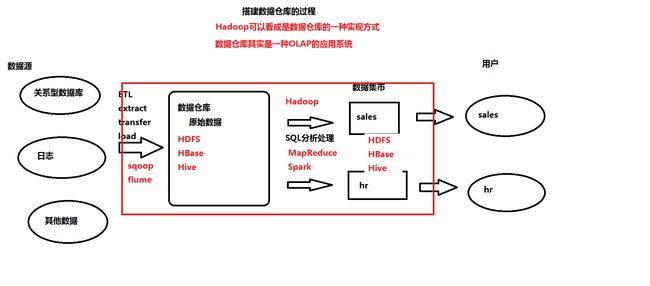
hadoop可以看成是数据仓库的一种实现方式
3、概念:OLTP和OLAP
OLTP: online transaction processing 联机事务处理
OLAP: online analytic processing 联机分析处理
4、(最重要内容)Google的三篇论文
(1) GFS: Google File System —-> HDFS: hadoop distributed file system(hadoop分布式文件系统)

机架感知

(2) MapReduce:来源:PageRank问题(网页排名)
(3) BigTable:大表 —-> HBase
(二)、实验环境
(三)、Apache Hadoop的体系结构(重要) —-> 都是一种主从结构
1、HDFS: 分布式文件系统
(*) 主节点:namenode 名称节点
(*) 从节点:datanode 数据节点
(*) 第二名称节点: SecondaryNameNode
2、Yarn: 容器,用于执行MapReduce
(*) 主节点:ResourceManager 资源管理器
(*) 从节点:NodeManager 节点管理器
3、HBase: 需要单独安装
(*) 主节点:HMaster
(*) 从节点:RegionServer
(*) 需要:ZooKeeper
(四)、Hadoop 2.X的安装与配置
三种模式
1、本地模式 一台
2、伪分布模式 一台
3、全分布模式 三台
4、掌握:免密码登录的原理和配置
(五)、Hadoop应用案例分析(了解)
(六)、HDFS
1、操作HDFS:命令行、Java API、Web Console
2、原理:数据上传和下载的过程(画图)
3、HDFS底层的原理:RPC(Remote Proceduer Call 远程过程调用 协议)
代理对象: Java 动态代理对象
4、高级特性
(*)回收站
(*)快照:Snapshot 备份
(*)配额quota:名称配额、空间配额
(*)安全模式:safe mode
(*)权限的管理
(七)、MapReduce:处理离线数据(历史数据)
1、Demo:经典WordCount
2、重点:分析WordCount执行的过程
3、Yarn调度MapReduce程序过程(原理)
4、高级特性
(*)排序
(*)序列化
(*)分区
(*)合并
5、MapReduce核心:Shuffle(洗牌)
6、编程案例
(*)排序:一个、多个列排序
(*)去重:distinct
(*)多表查询
(*)倒排索引:在HDFS中用于查找数据的一种方式
数据分析引擎
(八)、Hive:支持SQL,把SQL(select) —-> MapReduce
(九)、Pig: 支持PigLatin ,把PigLatin —-> MapReduce
(十)、HBase
1、基于HDFS之上的NoSQL
2、体系结构和安装配置
3、操作:命令行、Java、Web Console
4、过滤器:相当于where
5、开发基于HBase的MapReduce
数据采集引擎
(十一)、Sqoop:采集RDBMS(关系型数据库)
(十二)、Flume:采集日志
(十三)、HUE:管理工具
(十四)、ZooKeeper: 相当于“数据库”,实现HA(high avaibility)
(十五)、Hadoop的集群和HA
1、HDFS的联盟(Federation)
2、Hadoop HA
(十六)、Redis:基于内存的NoSQL数据库
重要:持久化(RDB、AOF)
事务、消息
主从复制
集群
(十七)、Storm:处理实时数据(流式数据)
集成Storm和Redis