Java 开发校招面试考点汇总 三(Java web、JDBC、计算机网络部分)
前言
题目来自牛客网,答案是自己整理的,仅供参考。有些题目没有答案是因为存在类似的题目或者过于基础,所以不再给出答案。共同学习,共同进步,希望大家能拿到心仪的offer!
三、Java web编程
❤1、web编程基础
1、启动项目时如何实现不在链接里输入项目名就能启动?
修改tomcat文件:server.xml
找到自己的项目设置:
修改成:
这样项目启动的时候就用不用输入项目名称了。
如: localhost:8000
2、1分钟之内只能处理1000个请求,你怎么实现,手撕代码?
我知道的有两种方式可以实现:
a). Application 对所有用户访问的次数计数。同时定义一个计时器,单位为一分钟。如果Application 中的用户在单位时间内超出请求次数,就拒绝处理该请求。一分钟再刷新application的值为0.
使用一个Map 维护变量:
// 泛型 String 表示用户标识,List中存放用户不同请求的时间戳。
private Map> map = new ConcurrentHashMap<>();
我们只需要在单位计数中判断 List中数量是否超出限制即可。
b). 使用 aop 实现请求的限制,在需要限制的请求方法上加上 aop 逻辑。即可实现,思路如下:

自定义注解类实现请求限制的拦截逻辑,在需要限制的方法上使用注解,超出限制后拒绝处理请求。
3、什么时候用assert
assertion(断言)在软件开发中是一种常用的调试方式,很多开发语言中都支持这种机制.在实现中,assertion就是在程序中的一条语句,它对一个boolean表达式进行检查,一个正确程序必须保证这个boolean表达式的值为true;如果该值为false,说明程序已经处于不正确的状态下,系统将给出警告或退出.一般来说,assertion用于保证程序最基本、关键的正确性.assertion检查通常在开发和测试时开启.为了提高性能,在软件发布后,assertion检查通常是关闭的.
4、JAVA应用服务器有那些?
Java 的应用服务器很多,从功能上分为两大类,JSP 服务器和 Java EE 服务器,也可分其他小类。相对来说 Java EE 服务器的功能更加强大。我平时就用Tomcat。
JSP 服务器有 Tomcat 、Bejy Tiger 、Geronimo 、 Jetty 、Jonas 、Jrun 、Orion 、Resin。
Java EE 服务器有TongWeb 、BES Application Server 、 Apusic Application Server 、 IBM Websphere 、Sun Application Server 、Oracle 的 Oracle9i/AS 、Sun Java System Application Server 、Bea Weblogic 、JBoss、开源GlassFish。(来源自百度百科)
5、JSP的内置对象及方法。
1.out:
println():向客户端输出各种类型的数据
newLine():输出一个换行符
close():关闭输出流
fiush():输出缓冲区数据
clearBuffer():清除缓冲区数据,并且把数据输出到客户端
clear():清除缓冲区数据,但是不把数据输出到客户端
getBufferSize():返回缓冲区大小
2.request:
getMethod():返回客户端向服务器端传送数据的方法
getParameter(String paramName):返回客户端传向服务器端传递的参数值
getParameterNames():获得客户端传递给服务器端的所有参数的名字
getParameterValues(String name):获得指定参数的所有值
getRequestURL():获得发出请求字符串的客户端地址
getRemoteAddr():获取客户端iPhone地址
getRemoteHost():获取客户端机器名称
getServerName():获取服务器名字
getServletName():客户端所请求的脚本文件路径
getServerPort():获取服务器端端口
对应的类为:javax.servlet.http.HttpServletRequest
3.response:
addCookie(Cookie cookie):添加一个Cookie对象,用于在客户端保存特定的信息
addHeader(String name, String value):添加HTTP头信息,该Header信息将发送到客户端
containsHeader(String name):判断指定名字的HTTP头文件是否存在
sendError(int):向客户端发送错误信息,int指服务器的错误码
sendRedirect(String url):重定向jsp文件,
setContentType(String contentType):设置MIME类型与编码方式
4.session:
void setAttribute(String name, Object value)
Object getAttribute(String name)
boolean isNew()
5.application:
getAttribute(java.lang.String name)
setAttribute(java.lang.String name, java.lang.Object object)
属于javax.servlet.ServletContext类
6.exception:
7.pageContext、config、page这3个用得比较少,了解即可
6、JSP和Servlet有哪些相同点和不同点,他们之间的联系是什么?(JSP)
相同点:JSP和Servlet本质上都是Java类。
不同点:JSP侧重于视图,Servlet主要用于控制逻辑
Servlet中没有内置对象,Jsp中的内置对象都是必须通过HttpServletRequest对象,HttpServletResponse对象以及HttpServlet对象获得。
联 系:JSP是Servlet技术的扩展,本质上就是Servlet的简易方式。
7、说一说四种会话跟踪技术
1.什么是会话
会话是指一个终端用户(服务器)与交互系统(客户端)进行通讯的过程。
2.什么是会话跟踪
对同一个用户对服务器的连续的请求和接受响应的监视。(将用户与同一用户发出的不同请求之间关联,为了数据共享)
3.为什么需要会话跟踪
浏览器与服务器之间的通信是通过HTTP协议进行通信的,而HTTP协议是”无状态”的协议,它不能保存客户的信息,即一次响应完成之后连接就断开了,下一次的请求需要重新连接,这样就需要判断是否是同一个用户,所以才应会话跟踪技术来实现这种要求
4.四种会话跟踪技术
a) URL重写:
URL(统一资源定位符)是Web上特定页面的地址,URL地址重写的原理是将该用户Session的id信息重写 到URL地址中,以便在服务器端进行识别不同的用户。URL重写能够在客户端停用cookies或者不支持cookies的时候仍然能够发挥作用。
b) 隐藏表单域:
将会话ID添加到HTML表单元素中提交到服务器,此表单元素并不在客户端显示,浏览时看不到,源代码中有。
c) Cookie:
Cookie是Web服务器发送给客户端的一小段信息,客户端请求时可以读取该信息发送到服务器端,进而进行用户的识别。对于客户端的每次请求,服务器都会将Cookie发送到客户端,在客户端可以进行保存,以便下次使用。 服务器创建保存于浏览器端,不可跨域名性,大小及数量有限。客户端可以采用两种方式来保存这个Cookie对象,一种方式是 保存在 客户端内存中,称为临时Cookie,浏览器关闭后 这个Cookie对象将消失。另外一种方式是保存在 客户机的磁盘上,称为永久Cookie。以后客户端只要访问该网站,就会将这个Cookie再次发送到服务器上,前提是 这个Cookie在有效期内。 这样就实现了对客户的跟踪。
Cookie是可以被禁止的。
d) session:
每一个用户都有一个不同的session,各个用户之间是不能共享的,是每个用户所独享的,在session中可以存放信息。 保存在服务器端。需要解决多台服务器间共享问题。如果Session内容过于复杂,当大量客户访问服务器时可能会导致内存溢出。因此,Session里的信息应该尽量精简。
在服务器端会创建一个session对象,产生一个sessionID来标识这个session对象,然后将这个sessionID放入到Cookie中发送到客户端,下一次访问时,sessionID会发送到服务器,在服务器端进行识别不同的用户。
Session是依赖Cookie的,如果Cookie被禁用,那么session也将失效。
8、讲讲Request对象的主要方法
Request对象是当客户端向服务器端发送请求时,服务器为本次请求创建request对象,并在调用Servlet的service方法时,将该对象传递给service方法。Request对象中封装了客户端发送过来的所有的请求数据。
Request对象的类型是HttpServletRequest,该类中定义了很多与http协议相关的方法,比如获取请求头信息,请求方式,客户端ip地址等信息。下面是常用的API.
Request获取请求参数方法
String getParameter(String name )
获取指定名称的请求参数值,适用于单值的请求参数
String[] getParameterValues(String name)
获取所有的请求参数名称
Map
获取所有请求参数,其中参数名作为map的key,参数值作为map的value.
9、说说weblogic中一个Domain的缺省目录结构?比如要将一个简单的helloWorld.jsp放入何目录下,然后在浏览器上就可打入主机?
Domain目录服务器目录applications,将应用目录放在此目录下将可以作为应用访问,如果是Web应用,应用目录需要满足Web应用目录要求,jsp文件可以直接放在应用目录中,Javabean需要放在应用目录的WEB-INF目录的classes目录中,设置服务器的缺省应用将可以实现在浏览器上无需输入应用名。
10、jsp有哪些动作?作用分别是什么?
JSP共有以下6种基本动作 作用如下:
jsp:useBean:寻找或者实例化一个JavaBean。
jsp:setProperty:设置JavaBean的属性。
jsp:getProperty:输出某个JavaBean的属性。
jsp:plugin:根据浏览器类型为Java插件生成OBJECT或EMBED标记。
jsp:forward:把请求转到一个新的页面。
jsp:include:在页面被请求的时候引入一个文件。
includ两种方法的实现 :
有两种实现方法,动态,静态。
动态:用于包含动态页面,并且可以随时检查页面的变化,采用jsp:include动作可以实现,例如:
静态,适合于包含静态页面,不检查页面的变化,采用include伪码实现
<%@include file="***.html"%>
11、请谈谈JSP有哪些内置对象?作用分别是什么?
九大内置对象
12、说一下表达式语言(EL)的隐式对象及其作用
EL的隐式对象包括:pageContext、initParam(访问上下文参数)、param(访问请求参数)、paramValues、header(访问请求头)、headerValues、cookie(访问cookie)、applicationScope(访问application作用域)、sessionScope(访问session作用域)、requestScope(访问request作用域)、pageScope(访问page作用域)。
13、JSP中的静态包含和动态包含有什么区别?
在jsp当中经常需要嵌套其他的jsp页面,以提高代码利用率跟工作效率。
常用的jsp嵌套包括静态包含跟动态包含两种方式,那这两种方式有啥区别呢。
下面这张图很好的解释了两者的区别:
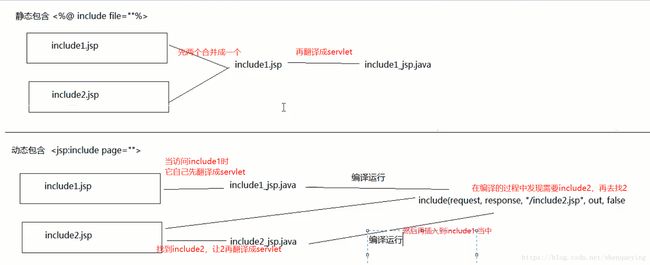
14、过滤器有哪些作用和用法?
过滤器的常见用途:
a).对用户的请求进行统一的认证、对访问的请求进行记录和审核
b).对用户传输的数据过滤和替换,转换图像格式,对响应内容进行压缩,减少网络传输
c).对用户的请求和响应进行加密处理
d).触发资源访问事件
Servlet 过滤器可以动态地拦截请求和响应,以变换或使用包含在请求或响应中的信息。
可以将一个或多个 Servlet 过滤器附加到一个 Servlet 或一组 Servlet。Servlet 过滤器也可以附加到 JavaServer Pages (JSP) 文件和 HTML 页面。调用 Servlet 前调用所有附加的 Servlet 过滤器。
Servlet 过滤器是可用于 Servlet 编程的 Java 类,可以实现以下目的:
在客户端的请求访问后端资源之前,拦截这些请求。
在服务器的响应发送回客户端之前,处理这些响应。
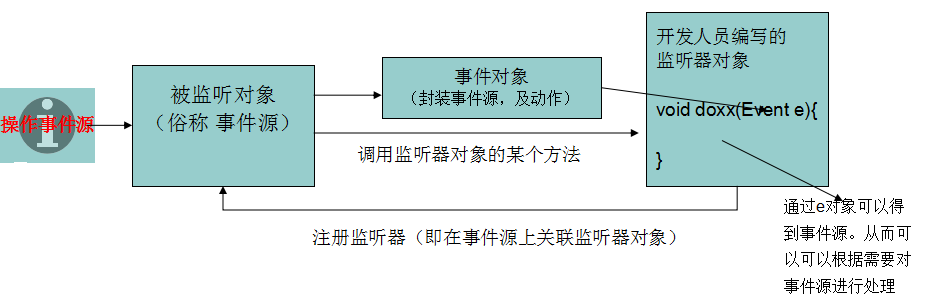
15、请谈谈你对Javaweb开发中的监听器的理解?
监听器是一个专门用于对其他对象身上发生的事件或状态改变进行监听和相应处理的对象,当被监视的对象发生情况时,立即采取相应的行动。
监听器其实就是一个实现特定接口的普通java程序,这个程序专门用于监听另一个java对象的方法调用或属性改变,当被监听对象发生上述事件后,监听器某个方法立即被执行。
java中的事件监听机制可用图来表示:
16、说说web.xml文件中可以配置哪些内容?
name
ytuan996
500
error.jsp
❤2、web编程进阶
1、forward与redirect区别,说一下你知道的状态码,redirect的状态码是多少?
1.forward
request.getRequestDispatcher("new.jsp").forward(request, response); //转发到new.jsp
2.redirect
response.sendRedirect("new.jsp"); //重定向到new.jsp
很明显一个是用request对象调用,一个是用response对象调用,那么,这两者有什么区别呢?
一、数据共享方面
forward:转发页面和转发到的页面可以共享request里面的数据
redirect:不能共享数据
二、地址栏显示方面
forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器.浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址.
redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址.所以地址栏显示的是新的URL.
三、本质区别
转发是服务器行为,重定向是客户端行为。为什么这样说呢,这就要看两个动作的工作流程:
转发过程:客户浏览器发送http请求—>web服务器接受此请求—>调用内部的一个方法在容器内部完成请求处理和转发动作—>将目标资源 发送给客户;在这里,转发的路径必须是同一个web容器下的url,其不能转向到其他的web路径上去,中间传递的是自己的容器内的request。在客 户浏览器路径栏显示的仍然是其第一次访问的路径,也就是说客户是感觉不到服务器做了转发的。转发行为是浏览器只做了一次访问请求。
重定向过程:客户浏览器发送http请求—>web服务器接受后发送302状态码响应及对应新的location给客户浏览器—>客户浏览器发现 是302响应,则自动再发送一个新的http请求,请求url是新的location地址—>服务器根据此请求寻找资源并发送给客户。在这里 location可以重定向到任意URL,既然是浏览器重新发出了请求,则就没有什么request传递的概念了。在客户浏览器路径栏显示的是其重定向的 路径,客户可以观察到地址的变化的。重定向行为是浏览器做了至少两次的访问请求的。
重定向,其实是两次request:第一次,客户端request A,服务器响应,并response回来,告诉浏览器,你应该去B。这个时候IE可以看到地址变了,而且历史的回退按钮也亮了。重定向可以访问自己web应用以外的资源。在重定向的过程中,传输的信息会被丢失。
2、servlet生命周期,是否单例,为什么是单例。
Servlet并不是单例,只是容器让它只实例化一次,变现出来的是单例的效果而已。
(1)加载和实例化
当Servlet容器启动或客户端发送一个请求时,Servlet容器会查找内存中是否存在该Servlet实例,若存在,则直接读取该实例响应请求;如果不存在,就创建一个Servlet实例。
(2) 初始化
实例化后,Servlet容器将调用Servlet的init()方法进行初始化(一些准备工作或资源预加载工作)。
(3)服务
初始化后,Servlet处于能响应请求的就绪状态。当接收到客户端请求时,调用service()的方法处理客户端请求,HttpServlet的service()方法会根据不同的请求 转调不同的doXxx()方法。
(4)销毁
当Servlet容器关闭时,Servlet实例也随时销毁。其间,Servlet容器会调用Servlet 的destroy()方法去判断该Servlet是否应当被释放(或回收资源)。
3、说出Servlet的生命周期,并说出Servlet和CGI的区别。
一、Servlet 生命周期
1、加载 2、实例化 3、初始化 4、处理请求 5、销毁
二、Servlet与cgi的区别:
Servlet处于服务器进程中,它通过多线程方式运行其service方法,一个实例可以服务于多个请求,并且其实例一般不会销毁,
而CGI对每个请求都产生新的进程,服务完成后就销毁,所以效率上低于servlet。
三、Servlet与JSP的比较:
有许多相似之处,都可以生成动态网页。
JSP的优点是擅长于网页制作,生成动态页面比较直观,缺点是不容易跟踪与排错。
Servlet是纯Java语言,擅长于处理流程和业务逻辑,缺点是生成动态网页不直观。
4、Servlet执行时一般实现哪几个方法?
public void init(ServletConfig config) throws ServletException;
public ServletConfig getServletConfig();
public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException;
public String getServletInfo();
public void destroy();
5、阐述一下阐述Servlet和CGI的区别?
6、说说Servlet接口中有哪些方法?
7、Servlet 3中的异步处理指的是什么?
Servlet 3.0 之前,一个普通 Servlet 的主要工作流程大致如下:首先,Servlet 接收到请求之后,可能需要对请求携带的数据进行一些预处理;接着,调用业务接口的某些方法,以完成业务处理;最后,根据处理的结果提交响应,Servlet 线程结束。其中第二步的业务处理通常是最耗时的,这主要体现在数据库操作,以及其它的跨网络调用等,在此过程中,Servlet 线程一直处于阻塞状态,直到业务方法执行完毕。在处理业务的过程中,Servlet 资源一直被占用而得不到释放,对于并发较大的应用,这有可能造成性能的瓶颈。对此,在以前通常是采用私有解决方案来提前结束 Servlet 线程,并及时释放资源。
Servlet 3.0 针对这个问题做了开创性的工作,现在通过使用 Servlet 3.0 的异步处理支持,之前的 Servlet 处理流程可以调整为如下的过程:首先,Servlet 接收到请求之后,可能首先需要对请求携带的数据进行一些预处理;接着,Servlet 线程将请求转交给一个异步线程来执行业务处理,线程本身返回至容器,此时 Servlet 还没有生成响应数据,异步线程处理完业务以后,可以直接生成响应数据(异步线程拥有 ServletRequest 和 ServletResponse 对象的引用),或者将请求继续转发给其它 Servlet。如此一来, Servlet 线程不再是一直处于阻塞状态以等待业务逻辑的处理,而是启动异步线程之后可以立即返回。
8、如何在基于Java的Web项目中实现文件上传和下载?
在Sevlet 3 以前,Servlet API中没有支持上传功能的API,因此要实现上传功能需要引入第三方工具从POST请求中获得上传的附件或者通过自行处理输入流来获得上传的文件,我们推荐使用Apache的commons-fileupload。
从Servlet 3开始,文件上传变得无比简单,相信看看下面的例子一切都清楚了。
上传页面index.jsp:
<%@ page pageEncoding="utf-8"%>
Photo Upload
Select your photo and upload
${hint}
支持上传的Servlet:
@WebServlet("/UploadServlet")
@MultipartConfig
public class UploadServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doPost(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException {
// 可以用request.getPart()方法获得名为photo的上传附件
// 也可以用request.getParts()获得所有上传附件(多文件上传)
// 然后通过循环分别处理每一个上传的文件
Part part = request.getPart("photo");
if (part != null && part.getSubmittedFileName().length() > 0) {
// 用ServletContext对象的getRealPath()方法获得上传文件夹的绝对路径
String savePath = request.getServletContext().getRealPath("/upload");
// Servlet 3.1规范中可以用Part对象的getSubmittedFileName()方法获得上传的文件名
// 更好的做法是为上传的文件进行重命名(避免同名文件的相互覆盖)
part.write(savePath + "/" + part.getSubmittedFileName());
request.setAttribute("hint", "Upload Successfully!");
} else {
request.setAttribute("hint", "Upload failed!");
}
// 跳转回到上传页面
request.getRequestDispatcher("index.jsp").forward(request, response);
}
}
9、服务器收到用户提交的表单数据,到底是调用Servlet的doGet()还是doPost()方法?
HTML的元素有一个method属性,用来指定提交表单的方式,其值可以是get或post。我们自定义的Servlet一般情况下会重写doGet()或doPost()两个方法之一或全部,如果是GET请求就调用doGet()方法,如果是POST请求就调用doPost()方法,那为什么为什么这样呢?我们自定义的Servlet通常继承自HttpServlet,HttpServlet继承自GenericServlet并重写了其中的service()方法,这个方法是Servlet接口中定义的。HttpServlet重写的service()方法会先获取用户请求的方法,然后根据请求方法调用doGet()、doPost()、doPut()、doDelete()等方法,如果在自定义Servlet中重写了这些方法,那么显然会调用重写过的(自定义的)方法,这显然是对模板方法模式的应用(如果不理解,请参考阎宏博士的《Java与模式》一书的第37章)。当然,自定义Servlet中也可以直接重写service()方法,那么不管是哪种方式的请求,都可以通过自己的代码进行处理,这对于不区分请求方法的场景比较合适。
10、Servlet中如何获取用户提交的查询参数或表单数据?
可以通过请求对象(HttpServletRequest)的getParameter()方法通过参数名获得参数值。如果有包含多个值的参数(例如复选框),可以通过请求对象的getParameterValues()方法获得。当然也可以通过请求对象的getParameterMap()获得一个参数名和参数值的映射(Map)。
11、Servlet中如何获取用户配置的初始化参数以及服务器上下文参数?
可以通过重写Servlet接口的init(ServletConfig)方法并通过ServletConfig对象的getInitParameter()方法来获取Servlet的初始化参数。可以通过ServletConfig对象的getServletContext()方法获取ServletContext对象,并通过该对象的getInitParameter()方法来获取服务器上下文参数。当然,ServletContext对象也在处理用户请求的方法(如doGet()方法)中通过请求对象的getServletContext()方法来获得。
12、讲一下redis的主从复制怎么做的?
通过持久化功能,Redis保证了即使在服务器宕机情况下数据的丢失非常少。但是如果这台服务器出现了硬盘故障、系统崩溃等等,不仅仅是数据丢失,很可能对业务造成灾难性打击。为了避免单点故障通常的做法是将数据复制多个副本保存在不同的服务器上,这样即使有其中一台服务器出现故障,其他服务器依然可以继续提供服务。当然Redis提供了多种高可用方案包括:主从复制、哨兵模式的主从复制、以及集群。
主从复制
在主从复制中,数据库分为两类,一类是主库(master),另一类是同步主库数据的从库(slave)。主库可以进行读写操作,当写操作导致数据变化时会自动同步到从库。而从库一般是只读的(特定情况也可以写,通过参数slave-read-only指定),并接受来自主库的数据,一个主库可拥有多个从库,而一个从库只能有一个主库。这样就使得redis的主从架构有了两种模式:一类是一主多从,二类是“链式主从复制”–主->从->主-从
13、redis为什么读写速率快性能好?
1.Redis将数据存储在内存上,避免了频繁的IO操作
2.Redis其本身采用字典的数据结构,时间复杂度为O(1),且其采用渐进式的扩容手段
3.Redis是单线程的,避免了上下文切换带来的消耗,采用网络IO多路复用技术来保证在多连接的时候, 系统的高吞吐量。
14、redis为什么是单线程?
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!,避免使用锁)。
正是由于在单线程模式的情况下已经很快了,就没有必要在使用多线程了!但是,我们使用单线程的方式是无法发挥多核CPU 性能,不过我们可以通过在单机开多个Redis 实例来完善!
警告:这里我们一直在强调的单线程,只是在处理我们的网络请求的时候只有一个线程来处理,一个正式的Redis Server运行的时候肯定是不止一个线程的,这里需要大家明确的注意一下!
15、缓存的优点?
原理:先查询缓存中有没有要的数据,如果有,就直接返回缓存中的数据。
如果缓存中没有要的数据,才去查询数据库,将得到数据先存放到缓存中,然后再返回给php。
优点:
1、 减少了对数据库的读操作,数据库的压力降低 2、 加快了响应速度
缺点:
1、 因为内存断电就清空数据,存放到内存中的数据可能丢失
2、 缓存中的数据可能与数据库中数据不一致
3、 内存的成本高
4、 内存容量相对硬盘小
16、aof,rdb,优点,区别?
Redis是一种高级key-value数据库。数据可以持久化,而且支持的数据类型很丰富。有字符串,链表,集 合和有序集合。支持在服务器端计算集合的并,交和补集(difference)等,还支持多种排序功能。所以Redis也可以被看成是一个数据结构服务器。Redis为了保证效率,数据缓存在内存中,Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,以保证数据的持久化。
Redis是一个支持持久化的内存数据库,可以将内存中的数据同步到磁盘保证持久化。
Redis的持久化策略:2种
RDB:快照形式是直接把内存中的数据保存到一个 dump 文件中,定时保存,保存策略。
AOF:把所有的对Redis的服务器进行修改的命令都存到一个文件里,命令的集合。
Redis默认是快照RDB的持久化方式当 Redis 重启时,它会优先使用 AOF 文件来还原数据集,因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。你甚至可以关闭持久化功能,让数据只在服务器运行时存。
二者的区别
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
RDB 和 AOF ,我应该用哪一个?
如果你非常关心你的数据,但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久。AOF 将 Redis 执行的每一条命令追加到磁盘中,处理巨大的写入会降低 Redis 的性能,不知道你是否可以接受。
数据库备份和灾难恢复:定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快。Redis 支持同时开启 RDB 和 AOF,系统重启后,Redis 会优先使用 AOF 来恢复数据,这样丢失的数据会最少。
17、redis的List能用做什么场景?
Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现。
List 就是链表,相信略有数据结构知识的人都应该能理解其结构。使用List结构,我们可以轻松地实现最新消息排行等功能。List的另一个应用就是消息队列,
可以利用List的PUSH操作,将任务存在List中,然后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作List中某一段的api,你可以直接查询,删除List中某一段的元素。
18、说说MVC的各个部分都有那些技术来实现?如何实现?
M(DAO)层,就相当于后台;
V(jsp),相当于前台;
C(control)层,相当于控制页面跳转;
MVC模式的目的就是实现Web系统的职能分工。 Model层实现系统中的业务逻辑,通常可以用JavaBean或EJB来实现。 View层用于与用户的交互,通常用JSP来实现。 Controller层是Model与View之间沟通的桥梁,它可以分派用户的请求并选择恰当的视图以用于显示,同时它也可以解释用户的输入并将它们映射为模型层可执行的操作。
M:hibernate/mybatis/ibatis
C:severlet/struts/spring action
V:jsp/FreeMarker/tails/taglib/EL/Velocity
19、什么是DAO模式?
DAO(Data Access Object)顾名思义是一个为数据库或其他持久化机制提供了抽象接口的对象,在不暴露底层持久化方案实现细节的前提下提供了各种数据访问操作。在实际的开发中,应该将所有对数据源的访问操作进行抽象化后封装在一个公共API中。用程序设计语言来说,就是建立一个接口,接口中定义了此应用程序中将会用到的所有事务方法。在这个应用程序中,当需要和数据源进行交互的时候则使用这个接口,并且编写一个单独的类来实现这个接口,在逻辑上该类对应一个特定的数据存储。DAO模式实际上包含了两个模式,一是Data Accessor(数据访问器),二是Data Object(数据对象),前者要解决如何访问数据的问题,而后者要解决的是如何用对象封装数据。
20、请问Java Web开发的Model 1和Model 2分别指的是什么?
Model 1是以页面为中心的Java Web开发,使用JSP+JavaBean技术将页面显示逻辑和业务逻辑处理分开,JSP实现页面显示,JavaBean对象用来保存数据和实现业务逻辑。
Model 2是基于MVC(模型-视图-控制器,Model-View-Controller)架构模式的开发模型,实现了模型和视图的彻底分离,利于团队开发和代码复用,如下图所示。
21、你的项目中使用过哪些JSTL标签?
项目中主要使用了JSTL的核心标签库,包括
说明:虽然JSTL标签库提供了core、sql、fmt、xml等标签库,但是实际开发中建议只使用核心标签库(core),而且最好只使用分支和循环标签并辅以表达式语言(EL),这样才能真正做到数据显示和业务逻辑的分离,这才是最佳实践。
22、使用标签库有什么好处?如何自定义JSP标签?(JSP标签)
使用标签库的好处包括以下几个方面:
- 分离JSP页面的内容和逻辑,简化了Web开发;
- 开发者可以创建自定义标签来封装业务逻辑和显示逻辑;
- 标签具有很好的可移植性、可维护性和可重用性;
- 避免了对Scriptlet(小脚本)的使用(很多公司的项目开发都不允许在JSP中书写小脚本)
自定义JSP标签包括以下几个步骤:
- 编写一个Java类实现实现Tag/BodyTag/IterationTag接口(开发中通常不直接实现这些接口而是继承TagSupport/BodyTagSupport/SimpleTagSupport类,这是对缺省适配模式的应用),重写doStartTag()、doEndTag()等方法,定义标签要完成的功能
- 编写扩展名为tld的标签描述文件对自定义标签进行部署,tld文件通常放在WEB-INF文件夹下或其子目录中
- 在JSP页面中使用taglib指令引用该标签库
❤3、web编程原理
1、get和post区别?
①get请求用来从服务器上获得资源,而post是用来向服务器提交数据;
②get将表单中数据按照name=value的形式,添加到action 所指向的URL 后面,并且两者使用"?“连接,而各个变量之间使用”&“连接;post是将表单中的数据放在HTTP协议的请求头或消息体中,传递到action所指向URL;
③get传输的数据要受到URL长度限制(1024字节);而post可以传输大量的数据,上传文件通常要使用post方式;
④使用get时参数会显示在地址栏上,如果这些数据不是敏感数据,那么可以使用get;对于敏感数据还是应用使用post;
⑤get使用MIME类型application/x-www-form-urlencoded的URL编码(也叫百分号编码)文本的格式传递参数,保证被传送的参数由遵循规范的文本组成,例如一个空格的编码是”%20"。
2、请谈谈转发和重定向的区别?
3、说说你对get和post请求,并且说说它们之间的区别?
4、cookie 和session 的区别?
session与cookie的区别
(1)Cookie以文本文件格式存储在浏览器中,而session存储在服务端它存储了限制数据量。它只允许4kb它没有在cookie中保存多个变量。
(2)cookie的存储限制了数据量,只允许4KB,而session是无限量的
(3)我们可以轻松访问cookie值但是我们无法轻松访问会话值,因此它更安全
(4)设置cookie时间可以使cookie过期。但是使用session-destory(),我们将会销毁会话。
总结:如果我们需要经常登录一个站点时,最好用cookie来保存信息,要不然每次登陆都特别麻烦,如果对于需要安全性高的站点以及控制数据的能力时需要用会话效果更佳,当然我们也可以结合两者,使网站按照我们的想法进行运行
5、forward 和redirect的区别
6、BS与CS的联系与区别。
C/S是Client/Server的缩写。服务器通常采用高性能的PC、工作站或小型机,并采用大型数据库系统,如Oracle、Sybase、Informix或 SQL Server。客户端需要安装专用的客户端软件。
B/S是Brower/Server的缩写,客户机上只要安装一个浏览器(Browser),如Netscape Navigator或Internet Explorer,服务器安装Oracle、Sybase、Informix或 SQL Server等数据库。在这种结构下,用户界面完全通过WWW浏览器实现,一部分事务逻辑在前端实现,但是主要事务逻辑在服务器端实现。浏览器通过Web Server 同数据库进行数据交互。
7、如何设置请求的编码以及响应内容的类型?
通过请求对象(ServletRequest)的setCharacterEncoding(String)方法可以设置请求的编码,其实要彻底解决乱码问题就应该让页面、服务器、请求和响应、Java程序都使用统一的编码,最好的选择当然是UTF-8;通过响应对象(ServletResponse)的setContentType(String)方法可以设置响应内容的类型,当然也可以通过HttpServletResponse对象的setHeader(String, String)方法来设置。
8、什么是Web Service(Web服务)?
1、什么是Web?
简单来说,Web就是在Http协议基础之上,利用浏览器进行访问的网站。目前来看最常用的意义是指在 Intenet 上和 HTML 相关的部分。换句话说,目前在 Intenet 上通过非浏览器访问的网络资源并不称为 Web。Web page指网站内的网页。我们常说的WWW(World Wide Web 万维网)就是这个概念下的内容。
而Internet(互联网)则是一个更大的概念, Internet上不只有Web, 还有FTP, P2P,Email, 或者App等其他多种不同的互联网应用方式. Web只是其中最广泛的一种. Internet的概念要大于Web。“Web已死 Internet永生”, 意思是传统网站的重要性可能会降低,新生的互联网服务可能会取代其重要性。虽然单纯从流量上看,Web已经不是最大的互联网应用。但由于其主体是文本(或者说是超文本hypertext),流量开销本身就远小于视频等其他应用。Web可能仍是最最重要的互联网载体。
2、什么是Web服务器?Web服务器和应用服务器的区别是什么?
严格意义上Web服务器只负责处理HTTP协议,只能发送静态页面的内容。而JSP,ASP,PHP等动态内容需要通过CGI、FastCGI、ISAPI等接口交给其他程序去处理。这个其他程序就是应用服务器。
(1)Web服务器的设计目的是提供HTTP内容,应用服务器也可以提供HTTP内容,但不限于HTTP,它还可以提供其他协议支持,如RMI / RPC。
(2)Web服务器主要是为提供静态内容而设计的,不过大多数Web服务器都有插件来支持脚本语言,比如Perl、PHP、ASP、JSP等,通过这些插件,这些服务器就可以生成动态的HTTP内容。
(3)大多数应用服务器都将Web服务器作为其不可分割的一部分,这意味着应用服务器可以做任何Web服务器所能做的事情。此外,应用服务器有组件和特性来支持应用级服务,如连接池、对象池、事务支持、消息传递服务等。
(4)由于web服务器非常适合用于提供静态内容,而应用服务器适合提供动态内容,因此大多数生产环境都有web服务器充当应用服务器的反向代理。这意味着在页面请求时,web服务器会通过提供静态内容(例如图像/静态HTML)来解释请求,并且它还会使用某种过滤技术(主要是请求资源的扩展)识别动态内容请求,并透明地转发到应用服务器。
非严谨的总结:前台接待(web服务器) 与 真正的价值服务者(应用服务器)。
9、谈谈Session的save()、update()、merge()、lock()、saveOrUpdate()和persist()方法分别是做什么的?有什么区别?
Hibernate的对象有三种状态,分别是:瞬时态(transient)、持久态(persistent)、游离态(detached)
1.瞬时态的实例可以通过调用save()、persist()或者saveOrUpdate()方法变成持久态
2.游离态的实例可以通过调用 update()、saveOrUpdate()、lock()或者replicate()方法变成持久态
3.save()和update()方法的区别在于前者是将瞬时态对象变成持久态,后者是将游离态对象变成持久态
4.merge()方法可以完成save()和update()方法的功能,它的意图是将新的状态合并到已有的持久化对象上或创建新的持久化对象。
5.lock()方法和update()方法的区别,update()方法是把一个已经更改过的脱管状态的对象变成持久态,lock()方法是把一个没有更改过的脱管状态的对象变成持久态
6. persist()方法把一个瞬时态的实例持久化,但是并不保证标识符被立刻填入到持久化实例中,标识符的填入可能被推迟到flush的时间persist()方法保证当它在一个事务外部被调用的时候并不触发一个INSERT语句
7.saveOrUpdate()方法则是判断对象是否已经存在,如若不存在,则将这个瞬时态对象变成持久态,如若存在,则将这个游离态对象持久化
8.replicate()方法同样是将游离态对象持久化,不同的是,假设你的对象的ID是用hibernate 负责生成的,但现在你想在数据库中插入一条已经指定ID的记录,这是就需要replicate()方法了
10、大型网站在架构上应当考虑哪些问题?
1、分层:
分层是处理任何复杂系统最常见的手段之一,将系统横向切分成若干个层面,每个层面只承担单一的职责,通过下层为上层提供的支撑和服务以及上层对下层的调用来形成一个完整的复杂的系统。
比较常见的分层模式是MVC,将软件系统分为持久层(提供数据存储和访问服务)、业务层(处理业务逻辑,系统中最核心的部分)和表示层(系统交互、视图展示)。
需要指出的是:
分层是逻辑上的划分,在物理上可以位于同一设备上也可以在不同的设备上部署不同的功能模块,这样可以使用更多的计算资源来应对用户的并发访问;
层与层之间应当有清晰的边界,这样分层才有意义,才更利于软件的开发和维护。
2、分割
分割是对软件的纵向切分。我们可以将系统的不同功能和服务分割开,形成高内聚低耦合的功能模块(单元)。在设计初期可以做一个粗粒度的分割,将系统分割为若干个功能模块,后期还可以进一步对每个模块进行细粒度的分割,这样一方面有助于软件的开发和维护,另一方面有助于分布式的部署,提供网站的并发处理能力和功能的扩展。
3、分布式
除了上面提到的内容,网站的静态资源(JavaScript、CSS、图片等)也可以采用独立分布式部署并采用独立的域名,这样可以减轻应用服务器的负载压力,也使得浏览器对资源的加载更快。数据的存取也应该是分布式的,传统的商业级关系型数据库产品基本上都支持分布式部署,而新生的NoSQL产品几乎都是分布式的。当然,网站后台的业务处理也要使用分布式技术,例如查询索引的构建、数据分析等,这些业务计算规模庞大,可以使用Hadoop以及MapReduce分布式计算框架来处理。
4、集群
集群使得有更多的服务器提供相同的服务,可以更好的提供对并发的支持
5、缓存
所谓缓存就是用空间换取时间的技术,将数据尽可能放在距离计算最近的位置。使用缓存是服务器优化的第一定律。我们通常说的CDN、反向代理、热点数据都是对缓存技术的使用。
6、异步
异步是实现软件实体之间解耦合的又一重要手段。异步架构是典型的生产者消费者模式,二者之间没有直接的调用关系,只要保持数据结构不变,彼此功能实现可以随意变化而不互相影响,这对系统的扩展非常有利。使用异步处理还可以提高系统可用性,加快服务器的响应速度,同时还可以起到削峰作用,应对瞬时高并)。
能推迟处理的都要推迟处理是服务器优化的第二定律,而异步是践行服务器优化第二定律的重要手段。
7、容灾
各种服务器都要提供相应的容灾服务器以便在某台或某些服务器宕机时还能保证网站可以正常工作,同时也提供了灾难恢复的可能性。冗余是系统高可用性的重要保证。
11、请对J2EE中常用的名词进行解释(或简单描述)
web容器:给处于其中的应用程序组件(JSP,SERVLET)提供一个环境,使JSP,SERVLET直接更容器中的环境变量接**互,不必关注其它系统问题。主要有WEB服务器来实现。例如:TOMCAT,WEBLOGIC,WEBSPHERE等。该容器提供的接口严格遵守J2EE规范中的WEB APPLICATION 标准。我们把遵守以上标准的WEB服务器就叫做J2EE中的WEB容器。
EJB容器:Enterprise java bean 容器。更具有行业领域特色。他提供给运行在其中的组件EJB各种管理功能。只要满足J2EE规范的EJB放入该容器,马上就会被容器进行高效率的管理。并且可以通过现成的接口来获得系统级别的服务。例如邮件服务、事务管理。
JNDI:(Java Naming & Directory Interface)JAVA命名目录服务。主要提供的功能是:提供一个目录系统,让其它各地的应用程序在其上面留下自己的索引,从而满足快速查找和定位分布式应用程序的功能。
JMS:(Java Message Service)JAVA消息服务。主要实现各个应用程序之间的通讯。包括点对点和广播。
JTA:(Java Transaction API)JAVA事务服务。提供各种分布式事务服务。应用程序只需调用其提供的接口即可。
JAF:(Java Action FrameWork)JAVA安全认证框架。提供一些安全控制方面的框架。让开发者通过各种部署和自定义实现自己的个性安全控制策略。
RMI/IIOP:(Remote Method Invocation /internet对象请求中介协议)他们主要用于通过远程调用服务。例如,远程有一台计算机上运行一个程序,它提供股票分析服务,我们可以在本地计算机上实现对其直接调用。当然这是要通过一定的规范才能在异构的系统之间进行通信。RMI是JAVA特有的。
四、JDBC编程
❤1、SQL基础
1、写SQL:找出每个城市的最新一条记录。
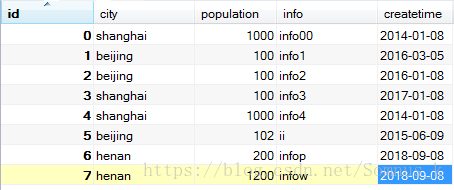
select * from info as info1
join (select city ,max(createtime) as createtime from info group by city) as info2
on info1.createtime=info2.createtime and info1.city=info2.city

2、一个学生表,一个课程成绩表,怎么找出学生课程的最高分数
学生表(child):id ,student(姓名)
成绩表(grade):id,grade,childid;
语句:select c.student,MAX(g.grade) from grade g,child c where c.id=g.childid group by c.id;
返回每个学生的最高成绩
3、有一组合索引(A,B,C),会出现哪几种查询方式?tag:sql语句
组合索引最左原则,有A,AB,ABC三种组合
❤2、JDBC基础
1、数据库水平切分,垂直切分
当我们使用读写分离、缓存后,数据库的压力还是很大的时候,这就需要使用到数据库拆分了。
数据库拆分简单来说,就是指通过某种特定的条件,按照某个维度,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面以达到分散单库(主机)负载的效果。
切分模式: 垂直(纵向)拆分、水平拆分。
垂直拆分
专库专用,一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面
水平拆分
垂直拆分后遇到单机瓶颈,可以使用水平拆分。相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。
相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中 的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,主要有分表,分库两种模式
https://www.cnblogs.com/firstdream/p/6728106.html
2、数据库索引介绍一下。介绍一下什么时候用Innodb什么时候用MyISAM。
MyISAM和InnoDB是MySQL提供的两种搜索引擎
MyISAM和InnoDB的区别
①InnoDB支持事务与外键和行级锁,MyISAM不支持(最主要的差别)
②MyISAM读性能要优于InnoDB,除了针对索引的update操作,MyISAM的写性能可能低于InnoDB,其他操作MyISAM的写性能也是优于InnoDB的,而且可以通过分库分表来提高MyISAM写操作的速度
③MyISAM的索引和数据是分开的,而且索引是压缩的,而InnoDB的索引和数据是紧密捆绑的,没有使用压缩,所以InnoDB的体积比MyISAM庞大
MyISAM引擎索引结构的叶子节点的数据域,存放的并不是实际的数据记录,而是数据记录的地址。索引文件与数据文件分离,这样的索引称为“非聚簇索引”。其检索算法:先按照B+Tree的检索算法检索,找到指定关键字,则取出对应数据域的值,作为地址取出数据记录。
InnoDB引擎索引结构的叶子节点的数据域,存放的就是实际的数据记录。这样的索引被称为“聚簇索引”,一个表只能有一个聚簇索引。
④InnoDB 中不保存表的具体行数,也就是说,执行select count() from table时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count()语句包含 where条件时,两种表的操作是一样的。
⑤DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。
⑥InnoDB表的行锁也不是绝对的,假如在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表,例如update table set num=1 where name like “%aaa%”
在where条件没有主键时,InnoDB照样会锁全表
选择哪种搜索引擎,应视具体应用而定
①如果是读多写少的项目,可以考虑使用MyISAM,MYISAM索引和数据是分开的,而且其索引是压缩的,可以更好地利用内存。所以它的查询性能明显优于INNODB。压缩后的索引也能节约一些磁盘空间。MYISAM拥有全文索引的功能,这可以极大地优化LIKE查询的效率。
②如果你的应用程序一定要使用事务,毫无疑问你要选择INNODB引擎
③如果是用MyISAM的话,merge引擎可以大大加快应用部门的开发速度,他们只要对这个merge表做一些select count(*)操作,非常适合大项目总量约几亿的rows某一类型(如日志,调查统计)的业务表。
3、数据库两种引擎
4、索引了解嘛,底层怎么实现的,什么时候会失效
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
索引并不是时时都会生效的,比如以下几种情况,将导致索引失效:
1.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
2.对于多列索引,不是使用的第一部分,则不会使用索引
3.like查询是以%开头
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
5.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
索引原理详解:https://www.cnblogs.com/boothsun/p/8970952.html
5、问了数据库的隔离级别
由低到高依次为Read uncommitted(未授权读取、读未提交)、Read committed(授权读取、读提交)、Repeatable read(可重复读取)、Serializable(序列化),这四个级别可以逐个解决脏读、不可重复读、幻读这几类问题。
(1)Read uncommitted(未授权读取、读未提交):
1)其他事务读未提交数据,出现脏读;
2)如果一个事务已经开始写数据,则另外一个事务则不允许同时进行写操作,但允许其他事务读此行数据。该隔离级别可以通过“排他写锁”实现。
3)避免了更新丢失,却可能出现脏读。也就是说事务B读取到了事务A未提交的数据。
(读未提交:一个事务写数据时,只允许其他事务对这行数据进行读,所以会出现脏读,事务T1读取T2未提交的数据)
(2)Read committed(授权读取、读提交):
1)允许写事务,所以会出现不可重复读
2)读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。
3)该隔离级别避免了脏读,但是却可能出现不可重复读。事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
(读已提交:读取数据的事务允许其他事务进行操作,避免了脏读,但是会出现不可重复读,事务T1读取数据,T2紧接着更新数据并提交数据,事务T1再次读取数据的时候,和第一次读的不一样。即虚读)
(3)Repeatable read(可重复读取):
1)禁止写事务;
2)读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。
3)避免了不可重复读取和脏读,但是有时可能出现幻读。这可以通过“共享读锁”和“排他写锁”实现。
(可重复读:读事务会禁止所有的写事务,但是允许读事务,避免了不可重复读和脏读,但是会出现幻读,即第二次查询数据时会包含第一次查询中未出现的数据)
(4)Serializable(序列化):
1)禁止任何事务,一个一个进行;
2)提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行。如果仅仅通过“行级锁”是无法实现事务序列化的,必须通过其他机制保证新插入的数据不会被刚执行查询操作的事务访问到。
3)序列化是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻读。
6、数据库乐观锁和悲观锁
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
两种锁的使用场景
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
7、数据库的三范式?
第一范式(1NF):原子性 字段不可再分,否则就不是关系数据库;
第二范式(2NF):唯一性 一个表只说明一个事物;
第三范式(3NF):每列都与主键有直接关系,不存在传递依赖;
8、讲一下数据库ACID的特性?
原子性(atomicity): 一个事物必须被视为一个不可分割的最小工作单元,整个事物中的操作要么全部提交成功,要么全部失败回滚,对于一个事物来说,不可能只执行其中的一部分操作,这就是的原子性。
一致性(consistency): 数据库总是从一个一致性的状态转到另一个事务的一致性状态。 由于事物的一致性,所以如果这时候执行完第三系统突然奔溃,支票账户也不会损失100,因为事物还没提交eg: 1 start transaction ; 2 select * from checking where id=1; 3 update checking set balance=balance-100 where id=1; 4 update savings set balance=balance+100 where id=1; 5 commit;
隔离性(isolation):一个事物所做的修改在最终提交前,对其他事物是不可见的。在前面的例子中,如果执行到第3,此时有另一个账户汇款,则其看见的支票账户得余额并没有被减去100。
持久性(durability): 一旦事物提交,则其所做的修改就会永远保存在数据库中。
9、mysql主从复制?
前提条件:开启二进制日志 已配置主从
1、mysql的主从同步是基于二进制日志。首先,主库会把其的数据更改(DDL DML DCL)记录到二进制日志Binary Log中。
2、接着,从库I/O线程将主库上的二进制日志复制到自己的中继日志Relay Log中。
3、最后,从库的sql线程会读取中继日志中的事件,将其重放(重新执行)在备库数据库之上,使其数据与主库一致。
10、leftjoin和rightjoin的区别?
1.inner join(内连接),在两张表进行连接查询时,只保留两张表中完全匹配的结果集。
2.left join,在两张表进行连接查询时,会返回左表所有的行,即使在右表中没有匹配的记录。
3.right join,在两张表进行连接查询时,会返回右表所有的行,即使在左表中没有匹配的记录。
4.full join,在两张表进行连接查询时,返回左表和右表中所有没有匹配的行。
11、数据库优化方法
1、创建索引
对于查询占主要的应用来说,索引显得尤为重要。很多时候性能问题很简单的就是因为我们忘了添加索引而造成的,或者说没有添加更为有效的索引导致。如果不加索引的话,那么查找任何哪怕只是一条特定的数据都会进行一次全表扫描,如果一张表的数据量很大而符合条件的结果又很少,那么不加索引会引起致命的性能下降。但是也不是什么情况都非得建索引不可,比如性别可能就只有两个值,建索引不仅没什么优势,还会影响到更新速度,这被称为过度索引。
2、复合索引
比如有一条语句是这样的:select * from users where area=‘beijing’ and age=22;
如果我们是在area和age上分别创建单个索引的话,由于mysql查询每次只能使用一个索引,所以虽然这样已经相对不做索引时全表扫描提高了很多效率,但是如果在area、age两列上创建复合索引的话将带来更高的效率。如果我们创建了(area, age, salary)的复合索引,那么其实相当于创建了(area,age,salary)、(area,age)、(area)三个索引,这被称为最佳左前缀特性。因此我们在创建复合索引时应该将最常用作限制条件的列放在最左边,依次递减。
3、索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
4、使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的 列,如果在前10 个或20 个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
5、排序的索引问题
mysql查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
6、like语句操作
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
7、不要在列上进行运算
select * from users where YEAR(adddate)<2007;
将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成
select * from users where adddate<‘2007-01-01’;
8、不使用NOT IN和<>操作
NOT IN和<>操作都不会使用索引将进行全表扫描。NOT IN可以NOT EXISTS代替,id<>3则可使用id>3 or id<3来代替。
12、谈一下你对继承映射的理解。
继承关系的映射策略有三种:
① 每个继承结构一张表(table per class hierarchy),不管多少个子类都用一张表。
② 每个子类一张表(table per subclass),公共信息放一张表,特有信息放单独的表。
③ 每个具体类一张表(table per concrete class),有多少个子类就有多少张表。
第一种方式属于单表策略,其优点在于查询子类对象的时候无需表连接,查询速度快,适合多态查询;缺点是可能导致表很大。后两种方式属于多表策略,其优点在于数据存储紧凑,其缺点是需要进行连接查询,不适合多态查询。
13、说出数据连接池的工作机制是什么?
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
数据库连接池的最小连接数和最大连接数的设置要考虑到下列几个因素:
- 最小连接数是连接池一直保持的数据库连接,所以如果应用程序对数据库连接的使用量不大,将会有大量的数据库连接资源被浪费;
- 最大连接数是连接池能申请的最大连接数,如果数据库连接请求超过此数,后面的数据库连接请求将被加入到等待队列中,这会影响之后的数据库操作。
- 如果最小连接数与最大连接数相差太大,那么最先的连接请求将会获利,之后超过最小连接数量的连接请求等价于建立一个新的数据库连接。不过,这些大于最小连接数的数据库连接在使用完不会马上被释放,它将被放到连接池中等待重复使用或是空闲超时后被释放。
14、事务的ACID是指什么?
15、JDBC中如何进行事务处理?
connect. setAutocommit commit rollback
❤3、JDBC进阶
1、JDBC的反射,反射都是什么?
什么是JDBC
Java定义了一套关于连接使用数据库的规范(接口)叫做JDBC,许多数据库厂商实现了这个规范,所以我们可以通过Java提供的接口编程,使得我们更换数据库的时候不用修改原来的代码,只需要通过修改配置文件即可,修改什么配置文件呢?下面会说。
什么是反射
如果我们在程序运行的时候得到一个字符串,而这个字符串是某个类的类名,如果要实例化这个类,那么就需要用到反射。
String className = "com.mysql.jdbc.Driver";//完整的包名+类名
Driver driver = (Driver)Class.forName(driverClass).newInstance();//通过反射实例化这个类
JDBC的使用过程
使用JDBC的时候要去下载对应的驱动程序,使用mysql,就要去mysql的官网下载,使用oracle,就去oracle的官网下载,然后把类库导入到工程中。这些驱动程序,其实就是实现了JDBC规范的类库。我使用的是mysql。
1.首先通过反射com.mysql.jdbc.Driver类,实例化该类的时候会执行该类内部的静态代码块,该代码块会在Java实现的DriverManager类中注册自己,DriverManager管理所有已经注册的驱动类,当调用DriverManager.geConnection方法时会遍历这些驱动类,并尝试去连接数据库,只要有一个能连接成功,就返回Connection对象,否则则报异常。
2.通过使用DriverManager.geConnection(url,user,password)函数,传入url,数据库用户名,数据库密码,得到数据库的Connection对象。
com.mysql.jdbc.Driver是mysql驱动类的全名,oracle驱动类的全名是oracle.jdbc.driver.OracleDriver。
连接数据库时要传入相应的url,
mysql url的格式是:jdbc:mysql://:3306/
oracle url的格式是:jdbc:oracle:thin::1521:
2、Jdo是什么?
JDO是Java对象持久化的新的规范,为java data object的简称,也是一个用于存取某种数据仓库中的对象的标准化API。JDO提供了透明的对象存储,因此对开发人员来说,存储数据对象完全不需要额外的代码(如JDBC API的使用)。这些繁琐的例行工作已经转移到JDO产品提供商身上,使开发人员解脱出来,从而集中时间和精力在业务逻辑上。另外,JDO很灵活,因为它可以在任何数据底层上运行。JDBC只是面向关系数据库(RDBMS)JDO更通用,提供到任何数据底层的存储功能,比如关系数据库、文件、XML以及对象数据库(ODBMS)等等,使得应用可移植性更强。
3、Statement和PreparedStatement有什么区别?哪个性能更好?
与Statement相比:
①PreparedStatement接口代表预编译的语句,它主要的优势在于可以减少SQL的编译错误并增加SQL的安全性(减少SQL注射攻击的可能性);
②PreparedStatement中的SQL语句是可以带参数的,避免了用字符串连接拼接SQL语句的麻烦和不安全;
③当批量处理SQL或频繁执行相同的查询时,PreparedStatement有明显的性能上的优势,由于数据库可以将编译优化后的SQL语句缓存起来,下次执行相同结构的语句时就会很快(不用再次编译和生成执行计划)
4、使用JDBC操作数据库时,如何提升读取数据的性能?如何提升更新数据的性能?
要提升读取数据的性能,可以指定通过结果集(ResultSet)对象的setFetchSize()方法指定每次抓取的记录数(典型的空间换时间策略);
要提升更新数据的性能可以使用PreparedStatement语句构建批处理,将若干SQL语句置于一个批处理中执行。
五、计算机网络
❤1、网络概述
1、TCP协议在哪一层?IP协议在那一层?HTTP在哪一层?
从上到下依次是HTTP(应用层)、TCP(传输层)、IP(网络层)。
❤2、运输层
1、讲一下TCP的连接和释放连接。
三次握手建立链接,四次挥手释放链接
2、TCP有哪些应用场景
tcp协议是面向连接的,可靠的数据传输协议,但是它的传输数据速率相比于udp协议比较慢。它适用于对数据传输可靠性要求比较高的场景,例如文本传输之类的。
3、tcp为什么可靠
确认机制和重传机制
4、tcp为什么要建立连接
5、阐述TCP的4次挥手
6、讲一下浏览器从接收到一个URL到最后展示出页面,经历了哪些过程。tag
当我们要访问某个网站的时候,我们在浏览器中输入网址的地址,这个时候浏览器会找到对应的DNS服务器,解析出IP地址,拿到IP地址后浏览器开始发送报文,对应的IP地址的服务器开始响应报文,以及把请求的资源发送给浏览器,浏览器在接受相应的资源后便会开始解析,常见的便是HTML,CSS,JavaScript
7、http和https的区别
HTTP是超文本传输协议,信息是明文传输,HTTPS则是具有安全性的SSL加密传输协议;HTTP和HTTPS使用的是完全不同的连接方式,使用的端口也不一样,http是80,https时443,http是无状态的连接,https是SSL+HTTP协议构建的可进行加密传输,比HTTP协议安全。
8、http的请求有哪些,应答码502和504有什么区别
502表示错误网关,无效网关 。 504表示网关超时,说明服务器作为网关或代理,但是没有及时从上游服务器收到请求。
9、http1.1和1.0的区别
http1.1相比1.0有如下几点不同:
1.默认支持长连接;
2.带宽优化,并支持断点续传;
3.新增例如ETag,If-None-Match等更多的缓存控制策略;
4.Host头域;
5.新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除;
http2.0与1.1相比有如下几点不同:
1.多路复用,可以做到在一个连接并行的处理多个请求;
2.header压缩;
3.服务端推送;
4.解析格式不同。HTTP1.0和1.1的解析是基于文本,2.0的协议解析采用二进制格式,实现方便且健壮;
10、说说ssl四次握手的过程
1.客户端向服务器发送加密通信的请求,请求包括:协议版本,客户端随机数,加密方法,压缩方式;
2.服务器确认支持协议版本,如果不支持则关闭加密通道;确认加密方式(从算法列表中选取响应的算法),生成随机数;返回服务器证书
3.客户端做出响应:客户端确认证书是否合法,如果合法,生成随机数并是使用公钥进行加密;使用约定的加密方式对握手信息进行加密,并使用随机数对消息进行加密,最后将所有的信息发送给服务器。
4.服务器使用自己的私钥对信息解密取出密码,使用密码对握手信息进行解密,同时利用client random、server random和premater secret通过一定算法生成对称加密key - session key。
11、304状态码有什么含义?
304状态码是告诉浏览器可以从缓存中获取所请求的资源。
当浏览器请求某一文件时,发现自己缓存的文件有Last-Modified,就会在httpRequest里面添加消息头If-Modified-Since 和If-Non-Match,服务器在收到reqeust时,和服务器本地文件对比,如果没有更新,则仅仅返回一个响应头Head(状态码304,而没有响应体),客户端在收到这个响应时,就会从本地缓存加载请求的资源。
❤3、网络层
1、arp协议,arp攻击
arp攻击就是arp欺骗。
使用别人的IP地址和自己的MAC地址向目标主机发送ARP包
欺骗成功后,目标发给别人IP地址的数据,都会发到你对应的MAC地址的设备上。
2、icmp协议
ICMP协议(Internet Control Message Protocol 网际控制报文协议)是ip层协议
作用是 提供主机或者路由器差错报告和异常情况报告,
我们经常使用的ping命令就是一种icmp报文,它用来探测两台主机之间的连通性
3、讲一下路由器和交换机的区别?
交换机属于数据链路层,路由器属于网络层;交换机是转发数据包,即MAC地址改变了,路由器是转发IP数据,当两台主机通信距离果园时,就会用到路由器,路由器根据接收的IP数据报的目的主机IP地址,查找路由表,找到下一跳路由器进行IP数据报转发
❤4、应用层
1、DNS寻址过程
1、客户机发出查询请求,在本地计算机缓存查找,若没有找到,就会将请求发送给dns服务器
2、先发送给本地dns服务器,本地的就会在自己的区域里面查找,若找到,根据此记录进行解析,若没有找到,就会在本地的缓存里面查找
3、本地服务器没有找到客户机查询的信息,就会将此请求发送到根域名dns服务器
4、根域名服务器解析客户机请求的根域部分,它把包含的下一级的dns服务器的地址返回到客户机的dns服务器地址
5、客户机的dns服务器根据返回的信息接着访问下一级的dns服务器
6、这样递归的方法一级一级接近查询的目标,最后在有目标域名的服务器上面得到相应的IP信息
7、客户机的本地的dns服务器会将查询结果返回给我们的客户机
8、客户机根据得到的ip信息访问目标主机,完成解析过程
2、负载均衡反向代理模式优点及缺点
通代理方式是代理内部网络用户访问internet上服务器的连接请求,客户端必须指定代理服务器,并将本来要直接发送到internet上服务器的连接请求发送给代理服务器处理。
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
反向代理负载均衡技术是把将来自internet上的连接请求以反向代理的方式动态地转发给内部网络上的多台服务器进行处理,从而达到负载均衡的目的。
反向代理负载均衡能以软件方式来实现,如apache mod_proxy、netscape proxy等,也可以在高速缓存器、负载均衡器等硬件设备上实现。反向代理负载均衡可以将优化的负载均衡策略和代理服务器的高速缓存技术结合在一起,提升静态网页的访问速度,提供有益的性能;由于网络外部用户不能直接访问真实的服务器,具备额外的安全性(同理,NAT负载均衡技术也有此优点)。
其缺点主要表现在以下两个方面:
反向代理是处于OSI参考模型第七层应用的,所以就必须为每一种应用服务专门开发一个反向代理服务器,这样就限制了反向代理负载均衡技术的应用范围,现在一般都用于对web服务器的负载均衡。
针对每一次代理,代理服务器就必须打开两个连接,一个对外,一个对内,因此在并发连接请求数量非常大的时候,代理服务器的负载也就非常大了,在最后代理服务器本身会成为服务的瓶颈。
一般来讲,可以用它来对连接数量不是特别大,但每次连接都需要消耗大量处理资源的站点进行负载均衡,如search等。
六、操作系统
❤1、操作系统概论
1、CentOS 和 Linux的关系?
linux内核,原始车,centos是车的一种,还有ubantu,debian,kali等车型,但都有原始车功能,其他附属服务有不同,可能开起来感觉不一样
2、64位和32位的区别?
1、运行能力不同。64位可以一次性处理8个字节的数据量,而32位一次性只可以处理4个字节的数据量,因此64位比32位的运行能力提高了一倍。
2、内存寻址不同。64位最大寻址空间为2的64次方,理论值直接达到了16TB,而32位的最大寻址空间为2的32次方,为4GB,换而言之,就是说32位系统的处理器最大只支持到4G内存,而64位系统最大支持的内存高达亿位数。
3、运行软件不同。由于32位和64位CPU的指令集是不同的。所以需要区分32位和64位版本的软件。
❤2、进程的描述与控制
1、怎么杀死进程?
1:kiss process 查找某个进程的具体ID ps -ef | grep “xxxprocess” ,kill pid;
2:killall “processname”
2、线程,进程区别
3、系统线程数量上限是多少?
4、进程和线程的区别是什么?
5、解释一下LINUX下线程,GDI类。
LINUX实现的就是基于核心轻量级进程的"一对一"线程模型,一个线程实体对应一个核心轻量级进程,而线程之间的管理在核外函数库中实现。
GDI类为图像设备编程接口类库。
❤3、输入输出系统
1、socket编程,BIO,NIO,epoll?
BIO是同步阻塞IO,NIO是同步非阻塞IO,AIO是异步非阻塞IO;三种IO方式相比较而言,BIO是一个客户端对应一个线程,优化的话可以用线程池进行线程复用,但本质还是一个客户端-服务端通信对应一个线程;NIO只需要一个线程负责多路复用器selector的轮询,就可以处理不同客户端channel中的读/写事件,所以多个客户端实际只对应一个线程,另外服务器端和客户端均使用缓冲区的方式进行读写;AIO不需要过多的多路服务器selector即可实现异步读写,可以理解为简化版的NIO;
❤4、存储器管理
1、什么是页式存储?
式存储是指存储的时候以页面作为基本的存储单位,一个大的作业分存在N个页里,当执行作业的时候不需要同事加载所有的页,而是用到哪些加载哪些,页式存储让资源的效率更高
2、操作系统里的内存碎片你怎么理解,有什么解决办法?
内存碎片通常分为内部碎片和外部碎片:
1.内部碎片是由于采用固定大小的内存分区,当一个进程不能完全使用分给它的固定内存区域时就会产生内部碎片,通常内部碎片难以完全避免;
2.外部碎片是由于某些未分配的连续内存区域太小,以至于不能满足任意进程的内存分配请求,从而不能被进程利用的内存区域。
现在普遍采取的内存分配方式是段页式内存分配。将内存分为不同的段,再将每一段分成固定大小的页。通过页表机制,使段内的页可以不必连续处于同一内存区域。
❤5、处理机调度与死锁
1、什么情况下会发生死锁,解决策略有哪些?
2、系统CPU比较高是什么原因?
CPU占用使用率其实就是你运行的程序占用的CPU资源,表示你的机器在某个时间点的运行程序的情况。使用率越高,说明你的机器在这个时间上运行了很多程序,反之较少。使用率的高低与你的CPU强弱有直接关系。现代分时多任务操作系统对 CPU 都是分时间片使用的:比如A进程占用10ms,然后B进程占用30ms,然后空闲60ms,再又是A进程占10ms,B进程占30ms,空闲60ms;如果在一段时间内都是如此,那么这段时间内的占用率为40%。CPU对线程的响应并不是连续的,通常会在一段时间后自动中断线程。未响应的线程增加,就会不断加大CPU的占用。cpu使用率高的原因有很多,但是一般都是由于病毒木马或开机启动项过多所致。高CPU使用率也可能表明应用程序的调整或设计不良。优化应用程序可以降低CPU的使用率。
3、系统如何提高并发性?
1.物理层增加网络宽带,域名解析分发多台服务器
2.操作系统层,多线程多核编程,epoll,事件驱动框架,异步消息机制
3.业务层,优化数据库查询redis缓存