
本篇涉及知识:
1、request第三方库的基本使用
2、json解析
本篇目标:
爬取指定一个歌单的所有歌曲的热门评论
(注:本篇爬取不直接解析html文本,而是直接分析获取评论的api,从而获得相应的json返回。然后,解析json获取所需信息。)
踩坑记录:
1、换行符号“\”导致一些未知问题,慎用换行符号“\”
分析api
- 我们首先用浏览器打开网易云音乐的网页版,随便进入一个歌单,点击进入一首歌曲的页面,可以看到下面有评论。接着F12进入开发者控制台(审查元素)。

我们在搜索框里输入comments即可找到对应的获取评论的api的url,点击它在右边选择Response就可以看到返回的json了。
那我们的思路就很清晰了,只需要分析这个api并模拟发送请求,获取json进行解析就好了。右键复制这个url下来:
http://music.163.com/weapi/v1/resource/comments/R_SO_4_465920636?csrf_token=4377e7fd9c7eede75d669c60a951fbed
从浏览器的上的地址可以发现以上url里R_SO_4_后的数字就是歌曲的id,如下图:
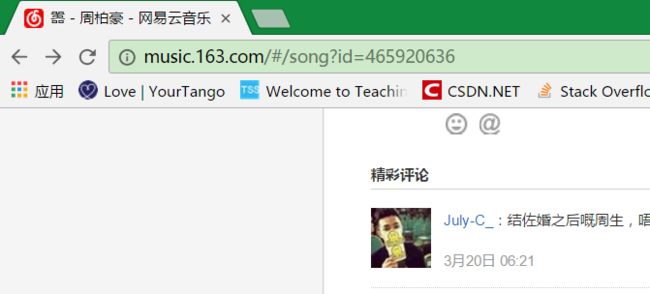
经测试,后面的csrf_tocken也可以用于其他歌曲。在开发者控制台里,点击headers就可以看到请求方式为post,请求头里的表单数据有两个加过密的参数(params和encSecKey)。但是不要紧,同样经测试,这两个参数也可以用于其他歌曲,直接copy就好。但只限于第一页,其他页码就不一样了,不过对于我们爬取热门评论,第一页就够了。


发送请求获取json
根据上个小节的分析,我们可以写出以下代码获取到json:
import requests
import json
url='http://music.163.com/weapi/v1/resource/comments/R_SO_4_465920636?csrf_token=c0f6bfdcd0526ec0ba6c207051a08960'
param={'params':'wxLqdGgw16OHb6UwY/sW16VtLqAhGaDMeI2F4DaESDplHA+CPsscI4mgiKoVCPuWW8lcd9eY0YWR/iai0sJqs0NmtLubVCkGdpN\
TN3mLhevZpdZy/XM1+z7L18InFz5HbbRkq230i0aOco/3jVsMWcD3/tzzOCLkGuu5xdbo99aUjDxHwDSVfu4pz4spV2KonJ47Rt6vJhOorV7LfpIVmP/qe\
ZghfaXXuKO2chlqU54=',\
'encSecKey':'12d3a1e221cd845231abdc0c29040e9c74a47ee32eb332a1850b6e19ff1f30218eb9e2d6d9a72bd797f75\
fa115b769ad580fc51128cc9993e51276043ccbd9ca4e1f589a2ec479ab0323c973e7f7b1fe1a7cd0a02ababe2adecadd4ac93d09744be0deafd1eef\
0cfbc79903216b1b71a82f9698eea0f0dc594f1269b419393c0'}#这里每行末尾的‘\’是代码过长用来换行的,慎用,换行多了易出现bug。
r=requests.post(url, param)
data=r.text#data得到的就是json
print data
运行查看输出就可以知道是否成功获取了json。这里requests的用法,可以参考requests快速上手。
解析json进行输出
我们可以从浏览器的开发者控制台里把json复制到一个 在线json校验格式化工具,这样可以比较清晰地看到json的结构,利于我们解析。如图:
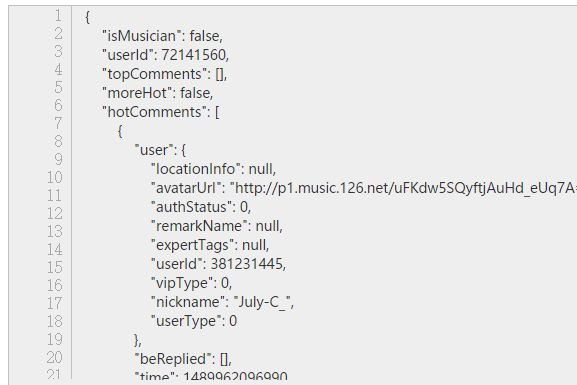
这个json里有丰富的信息,包括评论总数、用户名、热评、点赞数等。清楚了json 的结构,很容易就可以解析得到想要的信息了。json解析需要引入json包,了解json解析可以参考 使用python解析json详解。里面把json类型和python类型之间的对应关系讲得很清楚了,只需要会用dict和list。解析代码如下:
import requests
import json
url='http://music.163.com/weapi/v1/resource/comments/R_SO_4_465920636?csrf_token=c0f6bfdcd0526ec0ba6c207051a08960'
param={'params':'wxLqdGgw16OHb6UwY/sW16VtLqAhGaDMeI2F4DaESDplHA+CPsscI4mgiKoVCPuWW8lcd9eY0YWR/iai0sJqs0NmtLubVCkGdpN\
TN3mLhevZpdZy/XM1+z7L18InFz5HbbRkq230i0aOco/3jVsMWcD3/tzzOCLkGuu5xdbo99aUjDxHwDSVfu4pz4spV2KonJ47Rt6vJhOorV7LfpIVmP/qe\
ZghfaXXuKO2chlqU54=',\
'encSecKey':'12d3a1e221cd845231abdc0c29040e9c74a47ee32eb332a1850b6e19ff1f30218eb9e2d6d9a72bd797f75\
fa115b769ad580fc51128cc9993e51276043ccbd9ca4e1f589a2ec479ab0323c973e7f7b1fe1a7cd0a02ababe2adecadd4ac93d09744be0deafd1eef\
0cfbc79903216b1b71a82f9698eea0f0dc594f1269b419393c0'}#这里每行末尾的‘\’是代码过长用来换行的
r=requests.post(url, param)
data=r.text
jsob=json.loads(data)#加载获取的json数据,获得json对象
hotComments=jsob['hotComments']
for i in range(len(hotComments)):
user_nickname=hotComments[i]['user']['nickname']
likedCount=hotComments[i]['likedCount']
content=hotComments[i]['content']
print u'评论'+str(i+1)+u' 用户名:'+user_nickname+u" 喜欢:"+str(likedCount)
print '------------------------------------------------------------------'
print content
print '------------------------------------------------------------------'
print '\n'
输出结果:
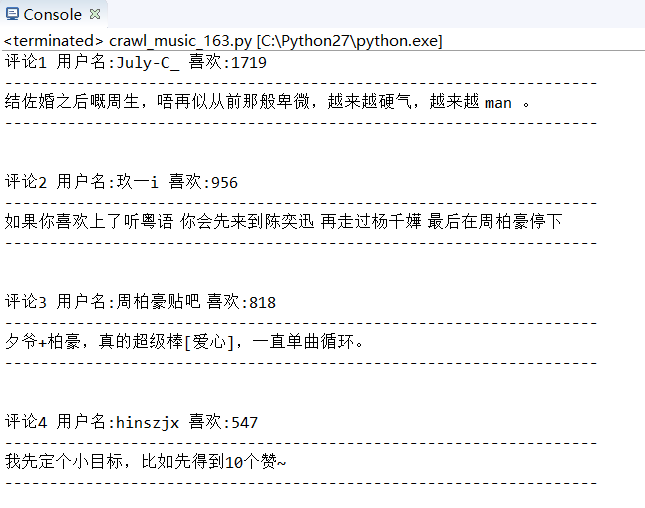
爬取一个歌单所有歌的热门评论
以上已经展示了怎么爬取一首歌的热门评论,接下来我们就可以进一步把一个歌单里所有歌的热门评论都爬取出来。
思路就是,将这个歌单所有歌曲的id爬取出来,替换到之前的url中,然后进行同样的输出。
同样的方法,我们发送歌单的url访问请求,读取response的返回内容看看情况。
url='http://music.163.com/playlist?id=700734626'
r=requests.get(url)
print r.text
输出:

可以看到第一行的标签textarea里有一个json,我们可以用xpath定位到这个标签,获取到这个json并进行解析。在此之前,可以向之前一样先复制到在线校验工具看看结构。

确实有我们需要的数据,接下来就可以进行解析了。
我们这里写成面向对象的风格,完整代码如下:
import requests
import json
from lxml import html
class CrawlMusic163:
#获取json解析出所有歌曲对象,返回歌曲的list
def getSongs(self,id):#这里的id是歌单的id
url='http://music.163.com/playlist?id='+str(id)
r=requests.get(url)
tree=html.fromstring(r.text)
data_json=tree.xpath('//textarea[@style="display:none;"]')[0].text
songs=json.loads(data_json)
return songs
#获取每首歌的热门评论的list
def getHotComments(self,id):#这里的id是歌曲的id
url='http://music.163.com/weapi/v1/resource/comments/R_SO_4_'+str(id)+'?csrf_token=c0f6bfdcd0526ec0ba6c207051a08960'
param={'params':'wxLqdGgw16OHb6UwY/sW16VtLqAhGaDMeI2F4DaESDplHA+CPsscI4mgiKoVCPuWW8lcd9eY0YWR/iai0sJqs0NmtLubVCkG\
dpNTN3mLhevZpdZy/XM1+z7L18InFz5HbbRkq230i0aOco/3jVsMWcD3/tzzOCLkGuu5xdbo99aUjDxHwDSVfu4pz4spV2KonJ47Rt6vJhOorV7LfpIVmP/qeZghfaXXuKO2chlqU54=',\
'encSecKey':'12d3a1e221cd845231abdc0c29040e9c74a47ee32eb332a1850b6e19ff1f30218eb9e2d6d9a72bd797f75fa115b769ad580fc51128cc9993e51276043ccbd9ca4e1f589a2ec479ab0323c973e7f7b1fe1a7cd0a02ababe2adecadd4ac93d09744be0deafd1eef0cfbc79903216b1b71a82f9698eea0f0dc594f1269b419393c0'}
r =requests.post(url,param)
data=r.text
jsob=json.loads(data)#加载获取的json数据,获得json对象
hotComments=jsob['hotComments']
return hotComments
crawl_music_163=CrawlMusic163()
songs=crawl_music_163.getSongs(700734626)#700734626是某个歌单的id,在网页版进入歌单后可以在url末尾获取
for song in songs:
hotComments=crawl_music_163.getHotComments(song['id'])#按id获取该歌曲的热门评论list
#输出每首歌的歌手名字-歌名-热门评论数
print song['artists'][0]['name']+"-"+song['name']+u"-热门评论:"+str(len(hotComments))
print '########################################################################'
#每首歌循环输出所有热门评论
for i in range(len(hotComments)):
user_nickname=hotComments[i]['user']['nickname']
likedCount=hotComments[i]['likedCount']
content=hotComments[i]['content']
print u'评论'+str(i+1)+u' 用户名:'+user_nickname+u" 喜欢:"+str(likedCount)
print '------------------------------------------------------------------'
print content
print '------------------------------------------------------------------'
print '\n'
print '########################################################################'
输出结果展示:

(注:这里遇到一个神坑,由于param太长,我用了几个""符号在末尾进行换行,如上代码那样换了两行没有问题,可是只要我在encSecKey参数这一行进行换行,就会产生bug,死活获取不到json文本。经过多次测试,确实就是""符号导致param没能正确地传入post导致获取不到json文本。目前不清楚什么原因,所以,这个换行还是慎用。)
本文参考:
requests快速上手
使用python解析json详解
Python 爬取百万网易云音乐热门评论