自然语言处理的难题
自然语言处理(Natural Language Processing NLP)是一门涉及到对学习,理解以及生成人类语言相关计算机技术进行探索的技术。 NLP技术可以协助人与人之间的沟通(如机器翻译)和人机之间的沟通(如智能助手),并可以对网上大量的文本资料进行分析并学习。
然而,这个等待人们进行深度开发的领域却存在着几个难题。
第一个难题是,我们作为人类并不能够有意识地去理解语言。
第二个难题是,人类语言的歧义性。
语法与概念
计算机在处理语法(syntax)方面任务的能力非常强,比如说,计算一个单词在一份120页文档中出现的次数。但它在处理概念方面的能力就非常弱了,事实上,计算机进程几乎意识不到概念。而另一方面,人类的自然语言却主要是关于概念的传递,我们只是用语法作为概念的暂时载体。这就使得计算机难以处理自然语言。

所以如果能使计算机更了解概念维度的东西,那么就可以减小这方面的制约了。
到这基本上就已经是个哲学问题了。在自然语言中,语法是一种方法或途径,而传递的概念是目的。
如果以运输为例的话,从A点运到B点是目的,而之间的路则是途径。如果人类灭亡很多年后,外星文明来到地球,当他们看到遍地的道路时,是否能只通过分析这些道路,而对当时的运输有所了解呢?答案应该是否定的!你不能够只通过分析途径还有方法,而完全理解传输的到底是什么。
语言的模糊性

当你想到一个语言概念,如单词或句子,那些看起来像是简单且很有道理的想法,实际上却有很多边界情况是难以搞清楚的 。
例如,英文里“won't”是一个词,还是两个词(大多系统视其为两个词)?还有在中文或(特别是)泰语中,母语使用者会对词语的边界有各种不同的看法。而与文本的意义相比,词和句子都还算非常简单的了。
事实上,英文中很多词语如此。如“ground”就有很多意思,可以作动词,更多时候可能又是名词。要理解一句话,你得先明白各个词的含义,这又不是件简单的任务。

但让人抓狂的是,对人类来说,这些东西却极其轻松。当你浏览网页时,无论是新创词语,还是动词化的名词或是各种讽刺手法,你都能立刻理解它们,甚至想都不用想。
还有比如说双关语这中人们用来娱乐的方式,它又刚好是阻碍NLP系统性能的因素之一。原因是计算机的处理方式与人类完全不同,所以一旦处理的文本和用于训练的文本相差很大时,NLP系统很有可能会完全混淆掉,而不是像人类理解出弦外之音。人们在微博或者Twitter上学习各种新的交流规则时,就根本不用考虑这一点。
自然语言处理
如果我们真的能够搞清楚人是怎么理解语言的话,那么也就可能让计算机做相同的事情。但是,因为这些知识都被隐藏很深,再加上人类的无意识。我们往往只能采用逼近和统计技术,而这些技术完全得依赖训练数据,所以这类系统可能永远也不会像人类这样灵活使用语言。

事实上,自然语言处理更多是解决自然语言文本分析与生成等工程问题的学科。成功标准不在于是否设计了更好的科学理论,或是证明了X和Y语言在历史上是相关的。相反,衡量标准是你是否在工程问题上获得了良好的解决方案。
例如,你不会根据谷歌翻译有没有用“真正正确的翻译”,或者能够说明译者们是如何完成他们的工作这样的标准来判断谷歌翻译的好坏。
而是根据在实践应用中是否产生了足够准确以及流畅的翻译来进行判断。机器翻译领域里就有办法来衡量这一点(如BLEU),他们主要专注于如何提高这些分数就行了。
什么时候使用NLP
NLP除了主要用于帮助人们查找和理解以文本形式存在着的大量信息。它还可以用于制作更好的用户界面,以便人类更好地与计算机以及其他人进行交流。
说NLP是工程学,并不意味着它就始终专注于开发商业应用。 NLP也可用于政治学(博客),经济学(金融新闻报道),医学(医学笔记),数字人文学科(文学作品,历史资料)等其他学科的科学研究。
NLP专业人士经常会摆脱相对表层的语言学,而研究当前系统所犯的错误,并只学习他们需要了解和修复最突出的错误类型的语言学。毕竟,他们的目标不是一个完整的理论,而是完成工作的最简单,最有效的方法。
语言学知识对于NLP (最近趋势)
那么语言学的知识是不是就真的对自然语言处理,毫无帮助呢。就像多年以前贾里尼克说的:“每当我开除一个语言学家,语音识别系统的性能就会改善一些。”
答案当然又是否定的,因为对于目前的NLP系统来说,还并没有强大到能够自己学习出足够有用的特征,所以语言学的知识在很大程度上还是能够对系统的性能提升有很大的帮组的。

一个典型的例子就是, 前两年当序列到序列模型(seq2seq)被提出来,并且广泛得到应用后,大家不由在某种程度上达成一些共识,语言不过就是一段字符串序列,即使没有语言学知识,也能够让系统通过数据自己学习出很好的结果。
然后最近就有很多学者对这个提出了质疑,包括个人比较喜欢的Yoav Goldberg。
其实看最近今年自然语言处理的顶级会议ACL上的论文也可以发现,人们也都普遍接受了要使用语言学结构的观点,并且对这方面进行了研究,想法设法如何将其利用进NLP系统中去,以提高系统的性能。
姑且可以称这个潮流为“语言学架构的回归”。
语言学架构的回归的原因
第一,降低了搜寻空间。
首先对于如神经网络这样的机器学习算法来说,就是根据训练数据来对函数空间进行搜索,最后获得较好的函数。而对于一些比较复杂的任务来说,搜索空间是无比巨大的,有时候很难获得一个好的解。通过结合语言学知识,可以一定程度上缩小搜索空间,从而使得更加快速地获得好的结果。
拿计算机视觉里面一个例子打个比方的话,如果我们要对某物体,如吴教授最喜欢的猫,进行分类。但是我们只有很少的图片,一两百来张。如果从零开始让网络来自己搜寻函数空间的话,是很难用这么点数据获得好的结果的。
但如果我们用预训练好的网络,如VGG-19,直接迁移学习微调的话,那么即使只有少量图片,也能获得比较好的结果。而这里预训练网络的作用,就是已经在底层构架出了一套视觉语法(点,线,基本图形...),而之后的分类器直接利用这套语法,就可以很快速地得出好的结果。
第二,语言学的层级架构
首先用ACL会议上Noah Smith教授的话来说,如果只是简单对语言进行线性转换,然后再直接挤压函数(激活函数)压一下的话,只会让模型变得笨重,而且过于简单粗暴。他更赞同于,大家在考虑归纳性偏向 inductive biases (关于模型对数据的假设) 的情况下,利用语言结构来设计更有效的模型。

Smith教授尤其提到了,最近很火的话题多任务学习 (Multi-task Learning)对语言层级结构的利用,通过联合多个NLP任务一起训练,从低级的词性标注到高级一点的依存句法分析,再到更高级的如情感分析这样的主任务。不光能够对主任务的性能起到一定的提升,有时也能对低级任务的性能进行提高。
第三,句法新近性>序列新近性
目前深度学习在自然语言处理方面的应用,主要是RNN (递归神经网络)的应用,然而RNN的最大的问题就是它的归纳性偏好是序列新近性,也就是说序列中离得越近越记得住,而语言并不光是序列新近性的,有时候开头第一个词和结尾最后一个词就可能会有很强的关联。但是RNN对于这样遥远的关系就很难捕捉到,即使使用LSTM这样的长短时序记忆RNN,也并不能解决这个问题。
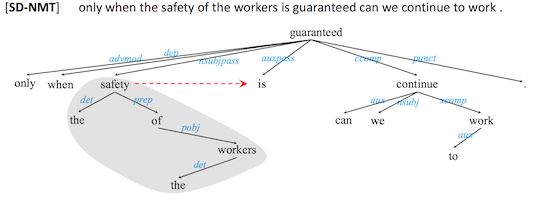
但是通过将语言学句法结构的知识融入到系统中,使用Recursive Neural Network (迭代神经网络)来处理的话,可以一定程度上对长距离关系进行比较好的捕捉。
结语
我的观点是,在目前这样我们尚不能仅仅通过机器学习算法获得好的解的情况下,尽量利用长时间积累出来的语言学知识,来帮助当前的系统取得更好的效果。
之后,自然语言处理系统能力发展起来,研究得以进展,能够在不依靠或少依靠语言学知识的情况下就取得更好的成果时,那么可以反过来利用在具体任务有良好表现的系统来指导语言学的发展。
就像最近的AlphaGo Zero,比起之前的版本利用人类的棋谱经验,Zero没有利用任何之前的棋谱经验还有人类特征。

反而通过自己探索,在无尽的可能中找到了自己的路,探索出了自己的下法。而用这些来反过来映观人类围棋的演化过程,就变得很有意思了。
同样,如果将来有能力打开深度学习网路黑盒的话,观察网络捕捉到的到底是什么样的层级特征,之后反过来利用这些特征来改进语言学知识。
到那时候,说不定我们离探明人类语言本能隐藏的真相那一天,也就已经不远了。
推荐读书 《Linguistic Fundamentals for Natural Language Processing》
了解用于自然语言处理方面语言学的一些知识。