本文内容:
一、栈
1、什么是栈?
2、栈的操作集.
3、栈的 C 实现.二、队列
1、什么是队列?
2、队列的操作集.
3、队列的 C 实现.
总表:《数据结构?》
工程代码 Github: Data_Structures_C_Implemention -- Stack & Queue
一、栈
1、什么是栈?
栈 (Stack),是限制插入与删除操作只能在末端 (Top) 进行的表,而这个末端也称为栈顶;
它有时候也会被称为,先进后出 (LIFO: Last In First Out) 表;
栈的抽象模型图:
2、栈的操作集.
从上面的模型图中就可以看出,栈的核心操作有: Push、Pop、Top (Peek) 三个操作;
栈操作集图示:
3、栈的 C 实现.
栈的实现方式,有两类,
解析:
1、数组的实现方式,我觉得不需要过多的解释了,链表就是为了解决数组的缺点而被设计出来的;
那么为什么要使用单链表来实现表,而不是其它链表形式呢?
首先,单链表是所有链表里面最简单的链表,空间占用也是最小的,也就是开销最小;只要证明单链表可以实现即可以了。
栈是一个表,而且是只能在一个端口进行插入与删除操作,遍历方向是从栈底到栈顶;
而单链表也是一个表,而且它的操作可以在任意位置进行插入与删除,遍历方向是链头与链尾;
从上面的两个结论来看,栈可以看作是单链表的其中一种情况;
2、在这里 tail 指针的指向改了一下,把它放在链头 [一般习惯性左边是指链头] 而它指向的就是最后一个压入的节点,也就是说左边的第一个节点就是真正的链尾;这样设计的目的就是为了让链表可以从链尾直接进行遍历操作,而且所有的插入与删除操作在链尾就可以实现;【您如果觉得晕,就先保有疑惑,等到查看下面的栈的入栈与出栈操作的具体代码实现的时候,我相信您就懂了!】
- 节点[内存结构]与栈的定义:
节点[内存结构],
struct __StackNode {
ElementTypePrt data;
#if _C_STACK_LINKEDLIST_IMP
StackNode next;
#else
int prevIdx;
#endif
};
解析:
1、_C_STACK_LINKEDLIST_IMP 原型是 #define _C_STACK_LINKEDLIST_IMP 1 就是一个宏开关,1 的时候是使用单链表的方式实现栈,0 就是使用数组的方式实现栈;
2、ElementTypePrt 原型是 typedef void * ElementTypePrt;,使用 typedef 是方便后期进行修改;这里使用指针的目的是为了让链表支持更多的数据类型,使代码的可扩展性更强;【如: data 可以直接指向一个单纯的 int 或者 一个 struct ,又或者是一个 list 等等】
3、在数组实现的方式下,prevIdx 这个参量其实可以不要的,看君爱好吧,反正入栈、出栈与它无关;
栈,
typedef struct __StackNode * _StackNode;
typedef _StackNode StackNode;
typedef struct __Stack * _Stack;
typedef _Stack Stack;
struct __Stack {
unsigned int size;
MatchFunc matchFunc;
DestroyFunc destroyFunc;
#if _C_STACK_LINKEDLIST_IMP
StackNode tail;
#else
unsigned int capacity;
int tailIdx;
StackNode nodes;
#endif
};
解析:
1、链表实现方式下,
#if _C_STACK_LINKEDLIST_IMP
StackNode tail;
#else
是取消了 head 指针,只保留了单链表的 tail 指针;
2、数组实现方式下,
#else
unsigned int capacity;
unsigned int tailIdx;
StackNode nodes;
#endif
引入一个 capacity 参量,我们知道,C 语言中数组初始化是要指定长度的,而这个参量就是表明数组的最大长度,也就是可以存储多少个节点;
tailIdx 就是栈顶节点的下标;
nodes 是一个结构体指针,相当于一个数组的首指针,数组中保存的是 struct __StackNode;
- 栈的核心操作集:
/* Stack Create */
#if _C_STACK_LINKEDLIST_IMP
Stack Stack_Create(DestroyFunc des);
#else
Stack Stack_Create(unsigned int cap, DestroyFunc des);
#endif
void Stack_Init(Stack s, DestroyFunc des);
void Stack_Destroy(Stack s);
/* Stack Operations */
_BOOL Stack_Push(Stack s, ElementTypePrt x);
_BOOL Stack_Pop(Stack s, ElementTypePrtPrt data);
ElementTypePrt Stack_Peek(Stack s);
_BOOL Stack_PeekAndPop(Stack s, ElementTypePrtPrt data);
- 栈的创建与销毁:
创建,
【链式实现】Stack Stack_Create(DestroyFunc des);
Stack Stack_Create(DestroyFunc des) {
Stack s = (Stack)(malloc(sizeof(struct __Stack)));
if (s == NULL) { printf("ERROR: Out Of Space !"); return NULL; }
Stack_Init(s, des);
return s;
}
解析:
1、DestroyFunc 原型是 typedef void(*DestroyFunc) (void * data); 指向形如 void(*) (void * data); 的函数指针;data 如何进行释放也由使用者决定;也是为了代码可扩展性;
2、malloc 原型是 void * malloc(size_t size) ;
3、Stack_Init(s, des);,请移步面下面的解释 初始化;
【数组实现】Stack Stack_Create(unsigned int cap, DestroyFunc des);
Stack Stack_Create(unsigned int cap, DestroyFunc des) {
if (cap == 0) { printf("ERROR: Bad Cap Parameter [cap > 0] !"); return NULL; }
if (cap > STACK_MAXELEMENTS) { printf("ERROR: Bad Cap Parameter [cap < STACK_MAXELEMENTS(%d)] !", STACK_MAXELEMENTS); return NULL; }
Stack s = (Stack)(malloc(sizeof(struct __Stack)));
if (s == NULL) { printf("ERROR: Out Of Space !"); return NULL; }
s->nodes = malloc(sizeof(StackNode) * cap);
if (s->nodes == NULL) { printf("ERROR: Out Of Space !"); free(s); return NULL; }
s->capacity = cap;
Stack_Init(s, des);
return s;
}
解析:
1、形参 unsigned int cap 就是数组初始化的最大内存空间;
2、STACK_MAXELEMENTS 原型是 #define STACK_MAXELEMENTS 100;
3、s->nodes = malloc(sizeof(StackNode) * cap); 这里就是与链式实现最大的区别,提前申请要保存节点的内存空间;
4、Stack_Init(s, des);,请移步面下面的解释 初始化;
初始化,
void Stack_Init(Stack s, DestroyFunc des) {
if (s == NULL) { printf("ERROR: Please Using Stack_Create(...) First !"); return; }
s->size = LINKEDLIST_EMPTY;
s->matchFunc = NULL;
s->destroyFunc = des;
#if _C_STACK_LINKEDLIST_IMP
s->tail = NULL;
#else
s->tailIdx = STACK_INVAILDINDEX;
#endif
}
解析,
里面的参量直接进行赋值为空就可以了,其中 LINKEDLIST_EMPTY 原型是 #define LINKEDLIST_EMPTY 0,STACK_INVAILDINDEX 原型是 #define STACK_INVAILDINDEX -1;
销毁,
void Stack_Destroy(Stack s) {
if (s == NULL) { printf("ERROR: Please Using Stack_Create(...) First !"); return; }
ElementTypePrt data;
while (!Stack_IsEmpty(s)) {
if ((Stack_Pop(s, (ElementTypePrtPrt)&data) == LINKEDLIST_TRUE) &&
(s->destroyFunc != NULL)) {
s->destroyFunc(data);
}
}
memset(s, 0, sizeof(struct __Stack));
}
解析,运作原理是不停地做出栈处理,直到栈空为止,就是清空栈的作用;
1、Stack_IsEmpty(s) 原型是 _BOOL Stack_IsEmpty(Stack s) { return (s->size == LINKEDLIST_EMPTY); }
2、Stack_Pop(s, (ElementTypePrtPrt)&data) == LINKEDLIST_TRUE) 请移步下面的 出栈操作
- 入栈操作:
_BOOL Stack_Push(Stack s, ElementTypePrt x) {
if (s == NULL) { printf("ERROR: Please Using Stack_Create(...) First !"); return LINKEDLIST_FALSE; }
StackNode nNode;
nNode = malloc(sizeof(struct __StackNode));
if (nNode == NULL) { printf("ERROR: Out Of Space ! "); return LINKEDLIST_FALSE; }
nNode->data = x;
#if _C_STACK_LINKEDLIST_IMP
nNode->next = NULL;
if (Stack_IsEmpty(s)) {
s->tail = nNode;
} else {
/* Get Tail */
StackNode tail = s->tail;
/* Push Operations */
nNode->next = tail;
/* Set Tail */
s->tail = nNode;
}
/* Size ++ */
s->size++;
#else
/* Size ++ */
s->size++;
if (s->size > s->capacity) {
printf("ERROR: Out Of Space ! ");
s->size--;
return LINKEDLIST_FALSE;
}
nNode->prevIdx = s->tailIdx;
s->tailIdx++;
s->nodes[s->tailIdx] = *nNode;
#endif
return LINKEDLIST_TRUE;
}
解析,
入栈操作图示,
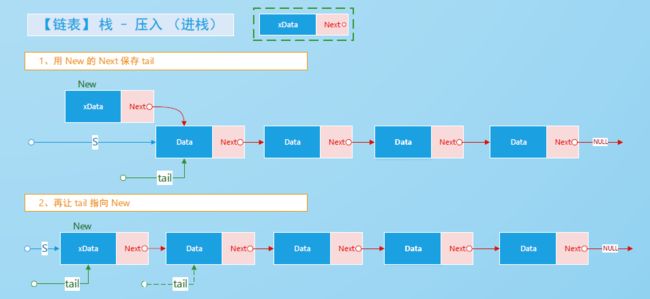
// 对应的核心代码
【链式实现】
nNode->next = tail;
s->tail = nNode;

// 对应的核心代码
【数组实现】
s->tailIdx++;
s->nodes[s->tailIdx] = *nNode;
- 出栈操作:
_BOOL Stack_Pop(Stack s, ElementTypePrtPrt data) {
if (s == NULL) { printf("ERROR: Bad Stack !"); return LINKEDLIST_FALSE; }
if (Stack_IsEmpty(s)) { printf("ERROR: Empty Stack !"); return LINKEDLIST_FALSE; }
#if _C_STACK_LINKEDLIST_IMP
StackNode lDelete = s->tail;
/* Get Data */
*data = lDelete->data;
/* Pop Operations */
s->tail = s->tail->next;
/* Free The Deleted Node */
free(lDelete);
#else
*data = s->nodes[s->tailIdx].data;
s->tailIdx--;
#endif
/* Size -- */
s->size--;
return LINKEDLIST_TRUE;
}
解析,
出栈操作图示,
【链式实现】
// 对应的核心代码
StackNode tail = s->tail;
s->tail = s->tail->next;
free(lDelete);

// 对应的核心代码
s->tailIdx--;
二、队列
1、什么是队列?
队列 (Queue),是限制插入操作在一端,而删除操作要在另一端进行的表;
它有时候也会被称为,先进先出 (FIFO: First In First Out) 表;
队列的抽象模型图:
2、队列的操作集.
从上面的模型图中就可以看出,队列的核心操作集有: Enqueue、Dequeue 两个操作;
队列操作集图示: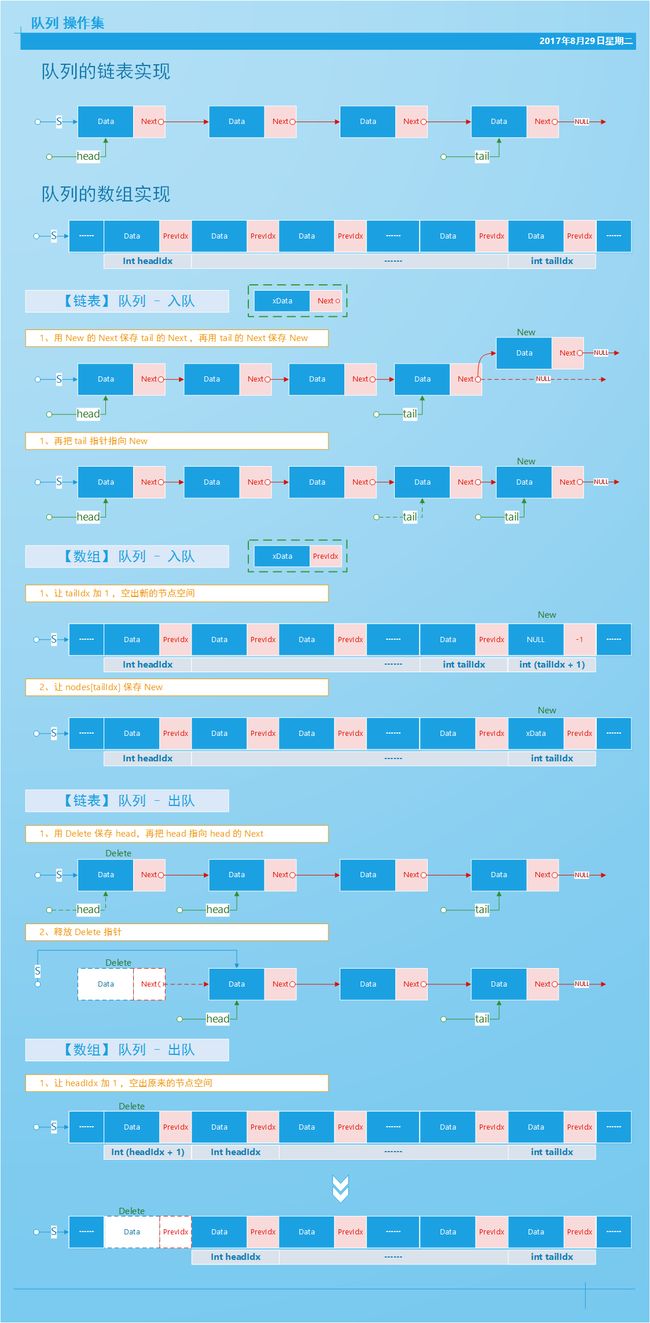
3、队列的 C 实现.
队列其实更接近单链表了,具备头和尾,当然遍历方向也是从头到尾,所以直接使用单链表来实现就可以了,不需要做太多的修改;
不过这里的,数组实现就要有点技巧了;
因为队列是一个端口进,另一个端口出,也就是要有一个指向进入方向的下标 headIdx ,以及出方向的下标 tailIdx ;
这里要注意的是, headIdx 与 tailIdx 的大小关系是不定的,这是由于数组自初始化后,空间是固定的,而在频繁的入队与出队操作后,会出现 headIdx > tailIdx 、headIdx < tailIdx、headIdx = tailIdx '这三种情况,而且它们会不停地进行切换;【当然这里也是要在代码实现的时候要特别细心处理的地方】
- 节点[内存结构]与队列的定义:
节点,【与栈节点定义一致】
typedef struct __QueueNode * _QueueNode;
typedef _QueueNode QueueNode;
struct __QueueNode {
ElementTypePrt data;
#if _C_QUEUE_LINKEDLIST_IMP
QueueNode next;
#else
int prevIdx;
#endif
};
队列,
typedef struct __Queue * _Queue;
typedef _Queue Queue;
struct __Queue {
unsigned int size;
MatchFunc matchFunc;
DestroyFunc destroyFunc;
#if _C_QUEUE_LINKEDLIST_IMP
QueueNode head;
QueueNode tail;
#else
unsigned int capacity;
int headIdx;
int tailIdx;
QueueNode nodes;
#endif
};
解析,
与栈对比,链式实现下,重新引入 QueueNode head; 指针,用于进行出队的操作;数组实现下,引入 int headIdx; 方便进行出队操作;
- 队列核心操作集:
/* Queue Create */
#if _C_QUEUE_LINKEDLIST_IMP
Queue Queue_Create(DestroyFunc des);
#else
Queue Queue_Create(unsigned int cap, DestroyFunc des);
#endif
void Queue_Init(Queue q, DestroyFunc des);
void Queue_Destroy(Queue q);
/* Queue Operations */
_BOOL Queue_Enqueue(Queue q, ElementTypePrt x);
_BOOL Queue_Dequeue(Queue q, ElementTypePrtPrt data);
ElementTypePrt Queue_Peek(Queue q);
_BOOL Queue_PeekAndDequeue(Queue q, ElementTypePrtPrt data);
解析,_C_QUEUE_LINKEDLIST_IMP 原型是 #define _C_QUEUE_LINKEDLIST_IMP 1 链式实现或数组实现的开关;
- 队列的创建与销毁:
创建,这里的代码实现与栈的实现一致;
初始化,
void Queue_Init(Queue q, DestroyFunc des) {
if (q == NULL) { printf("ERROR: Please Using Queue_Create(...) First !"); return; }
q->size = LINKEDLIST_EMPTY;
q->matchFunc = NULL;
q->destroyFunc = des;
#if _C_QUEUE_LINKEDLIST_IMP
q->tail = NULL;
#else
q->headIdx = 0;
q->tailIdx = QUEUE_INVAILDINDEX;
#endif
}
解析,这里要注意的是,在 数组实现方式下,
#else
q->headIdx = 0;
q->tailIdx = QUEUE_INVAILDINDEX; // -1
#endif
headIdx = 0 这里选择 0 而不是 QUEUE_INVAILDINDEX,因为这样做在入队操作的时候就可以使用headIdx 而不用增加一个判断【您可以先留有疑惑,结合下面的入队操作,我相信您就懂了】;
销毁,
与栈的出栈操作原理上是一样,只不过这里使用的是队列的出队操作罢了;
void Queue_Destroy(Queue q) {
if (q == NULL) { printf("ERROR: Please Using Queue_Create(...) First !"); return; }
ElementTypePrt data;
while (!Queue_IsEmpty(q)) {
if ((Queue_Dequeue(q, (ElementTypePrtPrt)&data) == LINKEDLIST_TRUE) &&
(q->destroyFunc != NULL)) {
q->destroyFunc(data);
}
}
memset(q, 0, sizeof(struct __Queue));
}
- 入队操作:
_BOOL Queue_Enqueue(Queue q, ElementTypePrt x) {
if (q == NULL) { printf("ERROR: Please Using Queue_Create(...) First !"); return LINKEDLIST_FALSE; }
QueueNode nNode;
nNode = malloc(sizeof(struct __QueueNode));
if (nNode == NULL) { printf("ERROR: Out Of Space ! "); return LINKEDLIST_FALSE; }
nNode->data = x;
#if _C_QUEUE_LINKEDLIST_IMP
nNode->next = NULL;
if (Queue_IsEmpty(q)) {
q->head = q->tail = nNode;
} else {
/* Get Tail */
QueueNode tail = q->tail;
/* Push Operations */
nNode->next = tail->next;
tail->next = nNode;
/* Set Tail */
q->tail = nNode;
}
/* Size ++ */
q->size++;
#else
/* Size ++ */
q->size++;
if (q->size > q->capacity) {
printf("ERROR: Out Of Space ! ");
q->size--;
return LINKEDLIST_FALSE;
}
q->tailIdx = Queue_VaildIdx(q->tailIdx, q);
nNode->prevIdx = q->tailIdx;
q->nodes[q->tailIdx] = *nNode;
#endif
return LINKEDLIST_TRUE;
}
解析,入队操作,在链式实现下就直接在链尾进行,而数组实现下直接在数组的最后一个下标节点进行;
入队操作图示,
【链式实现】
// 对应的核心代码
nNode->next = tail->next;
tail->next = nNode;
q->tail = nNode;

// 对应的核心代码
q->tailIdx = Queue_VaildIdx(q->tailIdx, q);
nNode->prevIdx = q->tailIdx;
q->nodes[q->tailIdx] = *nNode;
解析,这里要注意的是,tailIdx 的取值范围是 [0 ~ (size - 1) ~ 0] 它是一个循环,而不是简单地 taildIdx + 1;
Queue_VaildIdx 原型是
int Queue_VaildIdx(int idx, Queue q) {
if (++idx == q->capacity) { return 0; }
return idx;
}
提示,++idx == q->capacity 它的运算过程是 idx = idx + 1, idx == q->capacity ;
- 出队操作:
_BOOL Queue_Dequeue(Queue q, ElementTypePrtPrt data) {
if (q == NULL) { printf("ERROR: Bad Queue !"); return LINKEDLIST_FALSE; }
if (Queue_IsEmpty(q)) { printf("ERROR: Empty Queue !"); return LINKEDLIST_FALSE; }
#if _C_QUEUE_LINKEDLIST_IMP
QueueNode lDelete = q->head;
/* Get Data */
*data = lDelete->data;
/* Pop Operations */
q->head = q->head->next;
/* Free The Deleted Node */
free(lDelete);
#else
*data = q->nodes[q->headIdx].data;
q->headIdx = Queue_VaildIdx(q->headIdx, q);
#endif
/* Size -- */
q->size--;
return LINKEDLIST_TRUE;
}
解析,出队操作,在链式实现下就直接在链头进行,而数组实现下直接在数组的第一个下标节点进行;
出队操作图示,
【链式实现】
// 对应的核心代码
QueueNode lDelete = q->head;
q->head = q->head->next;
free(lDelete);
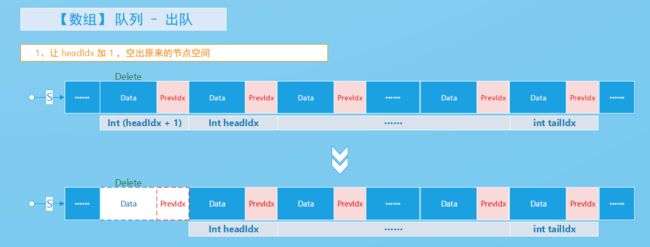
// 对应的核心代码
q->headIdx = Queue_VaildIdx(q->headIdx, q);
参考书籍:
1、《算法精解_C语言描述(中文版)》
2、《数据结构与算法分析—C语言描述》
写到这里,本文结束!下一篇,《数据结构:集合》