在项目中如果要实现全文检索,最普通的方法就是通过数据库查询语句like '%keywords%',但是这种方法在数据量多的情况下效率很低。目前最主流的方法是集成一个搜索引擎,通过调用相关API来实现创建索引以及搜索的功能。目前比较常见的开源搜索软件:Lucene、Solr、ElasticSearch、Sphinx、CoreSeek。
对于一个比较大型的项目来说,集成一个搜索引擎是必须的。但是对于一些比较小型的项目,不想使用like语句,集成一个搜索引擎又需要很大的成本。如果该项目的数据库是PostgreSQL,那么就可以使用PostgreSQL的全文检索功能。不过PostgreSQL的全文检索功能效率是比不上那些开源搜索软件的。
遗憾的是,PostgreSQL默认没有中文分词功能,因此要实现PostgreSQL的中文分词功能必须使用扩展插件。我通过百度找到了两种中文分词插件,pg_jieba和Zhparser。pg_jieba是基于结巴中文分词的,zhparser是基于SCWS。
pg_jieba:https://github.com/jaiminpan/pg_jieba
Zhparser:https://github.com/amutu/zhparser
测试过程中发现pg_jieba和Zhparser都能够比较方便的实现全文检索的功能。
不过碰到特殊的分词会出现问题,比如数据库里的公司地址字段会出现浙江省余杭市,浙江省余杭区,浙江省余杭这种情况,分词的结果分别是“余杭市”、“余杭区”以及“余杭”。搜索“余杭”关键字只会出现浙江省余杭的相关数据,余杭市和余杭区的数据并不会出现。这种情况,pg_jieba可以通过使用自定义的分词词典来解决,Zhparser也有相关功能。但是构建分词词典比较麻烦,有好多分词结果需要处理。我只是想实现一个简单的全文检索功能,幸好Zhparser有相关的参数进行配置。
另外个问题就是标点符号对分词结果的影响。pg_jieba的分词结果是不受标点符号影响的,而Zhparser会受到严重影响。
德哥 PostgreSQL 如何高效解决 按任意字段分词检索的问题 - case1
德哥的这篇文章中有写关于SCWS分词的问题,逗号会对分词结果产生影响,文中采用的方法是使用replace函数将逗号替换成空格。实际测试中,我发现+ - . \ ;等符号也会对分词结果产生影响。由于公司有的表的详情字段是通过富文本编辑器进行编辑的,难免会出现各种标点符号,所以这种替换的方法就不可取了,幸好Zhparser有相关参数配置能够忽略标点符号的影响。
再加上Zhparser的star数比pg_jieba的要高(从众心理不可取),所以我最后选用了Zhparser来进行中文分词。
集成Zhparser中文分词插件
1.安装中文分词插件SCWS和Zhparser
SCWS:https://github.com/hightman/scws
Zhparser:https://github.com/amutu/zhparser
2.安装完成之后,执行以下三条sql语句来启用中文分词,生成一个叫testzhcfg的解释器。
CREATE EXTENSION zhparser;
CREATE TEXT SEARCH CONFIGURATION testzhcfg(PARSER=zhparser);
ALTER TEXT SEARCH CONFIGURATION testzhcfg ADD MAPPING FOR n,v,a,i,e,l WITH simple;
3.通过下面这条语句设定分词执行时针对长词进行复合切分,比如余杭区分词时会被分成“余杭”和“余杭区”,不设置这条语句则分词结果只有“余杭区”。
alter role all set zhparser.multi_short=on;
通过下面这条语句来使分词时忽略标点符号的影响。
alter role all set zhparser.punctuation_ignore=on;
有两种方法进行全文检索,第一种是在搜索的时候进行分词操作。第二种是将分词的结果存储到新增的列当中,通过触发器更新这个字段,然后在该字段上建索引。第一种方法的优点是创建索引简单,占用空间少,缺点是每次执行查询都需要调用to_tsvector函数来确保索引值关联。第二种方法的优点是查询的速度快(无需每次调用to_tsvector函数),缺点是需要新增一个列,消耗更多的存储空间。
以zl_company表为例
第一种方法
create index idx_zl_company on zl_company using gin(to_tsvector('testzhcfg',coalesce(name,'')||coalesce(address,'')));//创建gin索引
使用函数coalesce来确保字段为NULL的也可以建立索引。该语句对name和address字段进行索引,也可以扩展别的字段。
explain analyse select * from zl_company where to_tsvector('testzhcfg',coalesce(name,'')||coalesce(address,'')) @@ to_tsquery('testzhcfg','余杭');
通过这条语句就可以查询“余杭”关键字对应的结果,如果有多个关键字,比如要查询余杭的公司可以通过to_tsquery('testzhcfg','余杭&公司')。
第二种方法
alter table zl_company add column tsv tsvector;//新建字段类型是tsvector
update zl_company set tsv = to_tsvector('testzhcfg',coalesce(name,'')||coalesce(address,''));//更新该字段
create index idx_zl_company on zl_company using gin(tsv);//创建gin索引
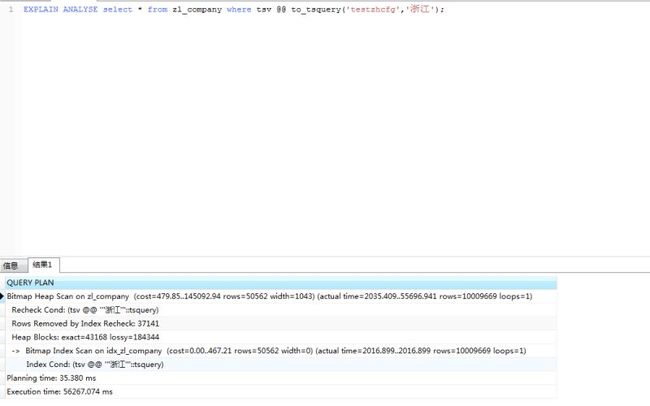
explain analyse select * from zl_company where tsv @@ to_tsquery('testzhcfg','余杭');
还需要创建一个触发器来更新tsv字段的值
create trigger tsvectorupdate before insert or update
on zl_company for each row execute procedure
tsvector_update_trigger(tsv, 'testzhcfg', name, address);
与like的效率对比
以1000万条数据为例
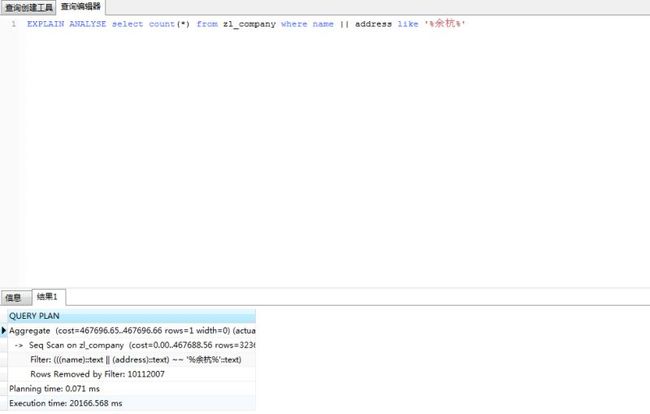
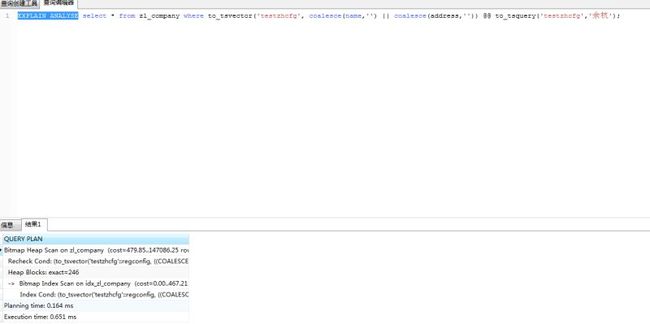
测试之后发现不管搜索的关键字是什么,like的搜索速度比较稳定,而PostgreSQL中文检索的搜索速度跟该搜索关键字的数据量有很大的关系。有个很尴尬的情况,这是我从正式库里复制的一个数据库表,里面加了将进1000万条相同的浙江某公司测试数据,只有几十万条的数据是正式数据,分词的结果反而比like还要慢,正式的数据也不大可能会出现1000万条分词相同的数据。如果真的出现了,我想总数据量应该都上亿了,这种时候不能再在代码层面上进行优化了,应该对数据库进行分表分库等。
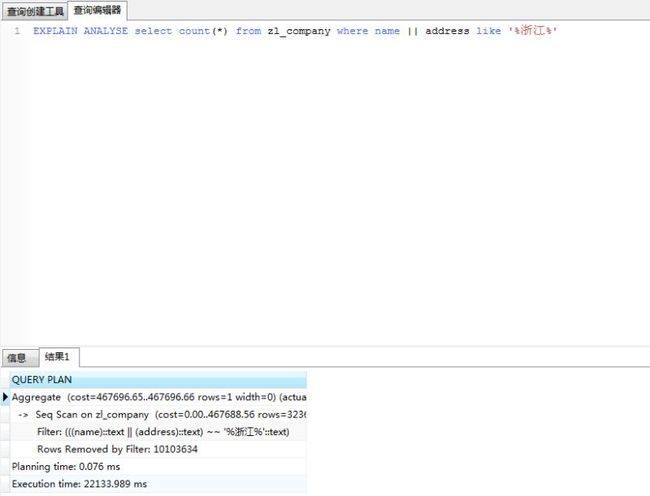
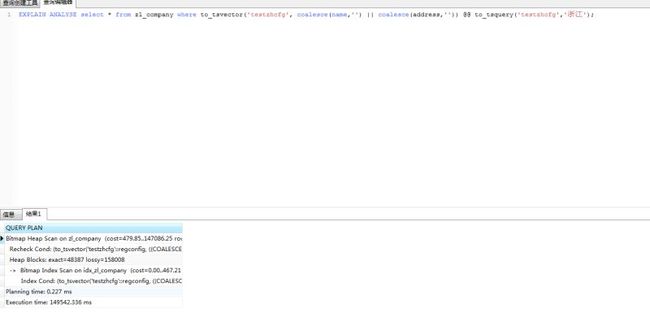
采用第二种方法后速度有明显提升。
如果PostgreSQL的版本为9.6以上,还能采用rum索引,速度比gin索引更快。详情看:PostgreSQL 全文检索加速 快到没有朋友 - RUM索引接口(潘多拉魔盒)
为Zhparser添加自定义中文分词词典的可以看:如何使用中文分词和自定义中文分词词典