
小西:小迪小迪,我发现人工智能发展史上很多事情都跟下棋有关呐。
小迪:是啊,人工智能发展史还是要从下棋说起,棋类游戏很多时候都被人类看做高智商游戏,在棋类游戏中让机器与人类博弈自然再好不过了。早在1769年,匈牙利作家兼发明家Wolfgang von Kempelen就建造了机器人TheTurk,用于与国际象棋高手博弈,但是最终被揭穿,原来是机器人的箱子里藏着一个人。虽然这是个骗局,但是也体现了棋类游戏是人机博弈中的焦点。
小西:哇,这么早啊!
小迪:是啊,在1968年上映的电影《2001太空漫游》里,有个情节是机器人HAL与人类Frank下国际象棋,最终人类在机器人面前甘拜下风。
小西:哈哈,看来很早人们就觉得有一天,机器人会在下棋方面超过人类哦。
小迪:是啊,直到1997年,IBM的深蓝智能系统战胜了国际象棋世界冠军Kasparov,这是一次正式意义上的机器在国际象棋领域战胜了人类。不过,当时时代杂志发表的文章还认为,计算机想要在围棋上战胜人类,需要再过上一百年甚至更长的时间。因为围棋相比于国际象棋复杂很多,而IBM的深蓝也只是一个暴力求解的系统,当时的计算机能力在围棋千千万万种变化情况下取胜是不可能的。

小西:后来我知道。没有过100年,20年后AlphaGo在20年后的2016年打败了围棋高手李世石,这下人工智能引起了全世界的关注。
小迪:恭喜你,学会抢答了!
小西:哈哈,过奖过奖。除了下棋,人工智能发展史上有没有什么特别著名的事件或者有名的大师呢,快给我科普科普呀!
小迪:那可就太多了啊,无数科学家默默地耕耘才有了今天智能化的社会,三天三夜都说不完。我就说说近些年火爆的深度学习的发展史吧。
小西:好,洗耳恭听呢!
感知器的发明
1943年Warren McCulloch和Walter Pitts一起提出计算模型,在1957年康奈尔大学的Frank Rosenblatt提出了感知器的概念,这是整个深度学习的开端,感知器是第一个具有自组织自学习能力的数学模型。Rosenblatt乐观地预测感知器最终可以学习,做决定和翻译语言。感知器技术在六十年代非常火热,受到了美国海军的资金支持,希望它以后能够像人一样活动,并且有自我意识。
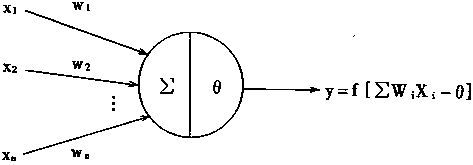
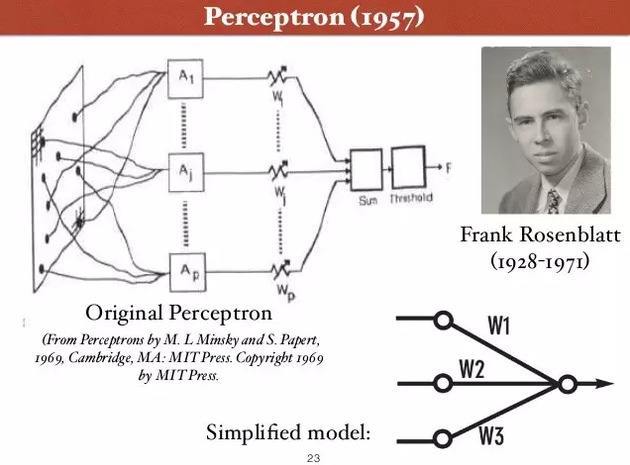
第一次低潮
Rosenblatt有一个高中校友叫做Minsky,在60年代,两人在感知器的问题上吵得不可开交。R认为感知器将无所不能,M觉得感知器存在很大的缺陷,应用有限。1969年,Minsky出版了新书《感知器:计算几何简介》,这本书中描述了感知器的两个重要问题:
- 单层神经网络不能解决不可线性分割的问题,典型例子:异或门;
- 当时的电脑完全没有能力承受神经网络的超大规模计算。
随后的十多年,人工智能转入第一次低潮,而Rosenblatt也在他43生日时,因海事丧生,遗憾未能见到神经网络后期的复兴。

Geoffrey Hinton与神经网络
1970年,此时的神经网络正处于第一次低潮期,爱丁堡大学的心理学学士Geoffrey Hinton刚刚毕业。他一直对脑科学非常着迷,同学告诉他,大脑对事物和概念的记忆,不是存储在某个单一的地方,而是分布式的存在一个巨大的神经网络中。分布式表征让Hinton感悟很多,随后的多年里他一直从事神经网络方面的研究,在爱丁堡继续攻读博士学位的他把人工智能作为自己的研究领域。

Rumelhart与BP算法
传统的神经网络拥有巨大的计算量,上世纪的计算机计算能力尚未能满足神经网络的训练。1986年7月,Hinton和David Rumelhart合作在Nature杂志上发表论文系统地阐述了BP算法:
- 反向传播算法(BP)把纠错运算量下降到只和神经元数目有关;
- BP算法在神经网络中加入隐层,能够解决非线性问题。
BP算法的效率相比传统神经网络大大提高,计算机的算力在上世纪后期也大幅提高,神经网络开始复苏,引领人工智能走向第二次辉煌。

Yann Lecun与卷积神经网络
1960年Yann Lecun在巴黎出身,在法国获得博士学位后,追随Hinton做了一年博士后,随后加入贝尔实验室。在1989年,Lecun发表论文提出卷积神经网络,并且结合反向传播算法应用在手写邮政编码上,取得了非常好的效果,识别率高达95%。基于这项技术的支票识别系统在90年代占据了美国接近20%的市场。
但也是在贝尔实验室,Yann Lecun的同事Vladmir Vapnik的研究又把神经网络的研究带入了第二个寒冬。

Hinton与深度学习
2003年,Geoffrey Hinton在多伦多大学苦苦钻研着神经网络。在与加拿大先进研究院(CIFAR)的负责人Melvin Silverman交谈后,负责人决定支持Hinton团队十年来进行神经网络的研究。在拿到资助后,Hinton做的第一件事就是把神经网络改名为深度学习。此后的一段时间里,同事经常会听到Hinton在办公室大叫:“我知道神经网络是如何工作的了!”

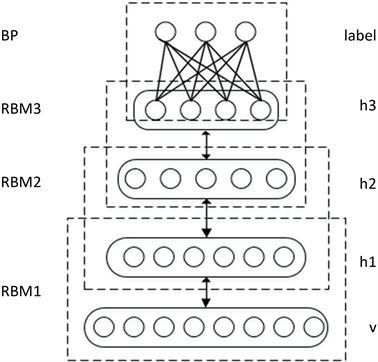
DBN与RBN
2006年Hinton与合作者发表论文——《A Fast Algorithm for Deep BeliefNet》(DBN)。这篇文章中的算法借用了统计力学中“波尔兹曼分布”的概念,使用了所谓的“受限玻尔兹曼机”,也就是RBN来学习。而DBN也就是几层RBN叠加在一起。RBN可以从输入数据进行预训练,自己发现重要的特征,对神经网络的权重进行有效的初始化。这里就出现了另外两个技术——特征提取器与自动编码器。经过MNIST数据集的训练后,识别错误率最低降到了只有1.25%。
吴恩达与GPU
2007年,英伟达推出cuda的GPU软件接口,GPU编程得以极大发展。2009年6月,斯坦福大学的Rajat Raina和吴恩达合作发表文章,论文采用DBNs模型和稀疏编码,模型参数高达一亿,使用GPU运行速度训练模型,相比传统双核CPU最快时相差70倍,把本来需要几周训练的时间降到了一天。算力的进步再次加速了人工智能的快速发展。

黄仁勋与GPU
黄仁勋也是一名华人,1963年出生于台湾,在1993年于斯坦福毕业后创立了英伟达公司,英伟达起家时主要做图像处理芯片,后来黄仁勋发明GPU这个词。相比于CPU架构,GPU善于大批量数据并行处理。而神经网络的计算工作,本质上就是大量的矩阵计算的操作,GPU的发展为深度学习奠定了算力的基础。

李飞飞与ImageNet
深度学习的三大基础——算法,算力和数据。上面提到的主要是算法与算力的发展,而数据集在深度学习发展也起到了至关重要的作用。又是一位华人学者——李飞飞,于2009年建立ImageNet数据集,以供计算机视觉工作者使用,数据集建立的时候,包含320个图像。2010年,ILSVRC2010第一次举办,这是以ImageNet为基础的大型图像识别大赛,比赛也推动了图像识别技术的飞速发展。2012年的比赛,神经网络第一次在图像识别领域击败其他技术,人工智能步入深度学习时代,这也是一个历史性的转折点。

Yoshua Bengio与RELU
2011年,加拿大学者Xavier Glorot与Yoshua Bengio联合发表文章,在算法中提出一种激活函数——RELU,也被称为修正线性单元,不仅识别错误率普遍降低,而且其有效性对于神经网络是否预训练过并不敏感。而且在计算力方面得到提升,也不存在传统激活函数的梯度消失问题。

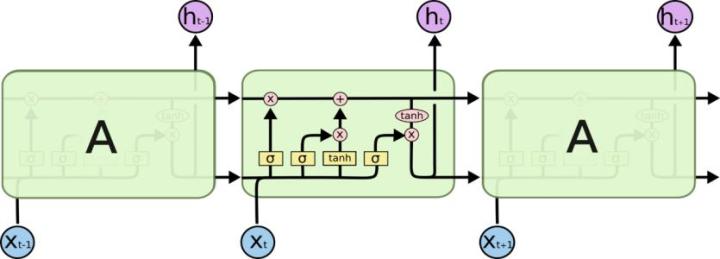
Schmidhuber与LSTM
其实早在1997年,瑞士Lugano大学的Suhmidhuber和他的学生合作,提出了长短期记忆模型(LSTM)。LSTM背后要解决的问题就是如何将有效的信息,在多层循环神经网络传递之后,仍能传送到需要的地方去。LSTM模块,是通过内在参数的设定,决定某个输入参数在很久之后是否还值得记住,何时取出使用,何时废弃不用。
后记
小迪:其实还有好多有突出贡献的的大师,要是都列出来可以出一本很厚很厚的书啦!
小西:这些大师都好厉害呀,为了我们的智能化生活体验,辛勤付出了一辈子。
小迪:是啊,还有很多学者默默无闻地工作,一生清苦。
小西:他们都好伟大,有突出贡献的都应该发奖发奖金,对对对,诺贝尔奖!
小迪:哈哈。诺贝尔奖多数是为基础学科设立的。不过计算机界也有“诺贝尔奖”——图灵奖,这可是计算机界最高奖项哦!2019年3月27日,ACM宣布,Geoffrey Hinton,Yann LeCun ,和Yoshua Bengio共同获得了2018年的图灵奖。
小西:太棒了,实至名归!
小迪:当然,图灵奖在此之前也授予了很多在人工智能领域的大牛,像Minsky,John McCarthy这些,还有华人科学家,现在在清华大学任职从事人工智能教育的姚期智先生在2000也获得过图灵奖呢!
小西:大师们太不容易了,我们也要好好学习呀!
小迪:是呀!如今我们站在巨人的肩膀上,许多人都可以接触到深度学习,机器学习的内容,不管是工业界还是学术界,人工智能都是一片火热!
小西:希望这一轮人工智能的兴起不会有低潮,一直蓬勃发展下去,更好地造福人类。
小迪:嗯!
