论文链接:https://www.ijcai.org/proceedings/2017/0311.pdf
跨领域情感分类也是一个domain adaptation任务。因为领域矛盾,在一个领域上训练的可能不能直接用于其他领域。传统的方法是手动去挑选pivots(支点,核心)。深度学习的方法可以学习领域共享的表示,然而,缺乏解释性去直接识别pivots。为了解决这个问题,本文提出一个端对端的对抗记忆网络(Adversarial Memory Network, AMN)去解决跨领域的情感分类。使用attention机制来自动抓取pivots。本文的框架包括两个参数共享的memory network,一个用于sentiment分类,一个用于domain分类。两个网络是联合训练的所以选择的特征可以最小化情感分类的错误,同时使领域分类器对于source和target domain是非歧视性的。
Introduction:
传统做情感分类是基于支持向量机(support vector machine),使用手工的特征,例如bag-of-n-grams。
用深度学习依赖大量标注的数据,time-consuming and expensive manual labeling.
本文的贡献:
1. 自动识别pivots,使用attention机制,不需要手动选择pivots
2. AMN模型可以实现可视化,告诉我们哪个是pivots,which makes the representation shared by domains more interpretable.
3. achieve better peroformance
Problem definition and notation(记号):
有一组标记数据和未标记数据,在target domain中,有一组未标记数据。跨域情感分类是要学习一个robust的分类器,这个分类器是在有标注的source领域训练的,用来预测target领域的未标记数据的polarity
The task of the cross-domain sentiment classification is to learn a robust classifier trained on labeled data in the source domain to predict the polarity of unlabeled examples from the target domain.
An overview of the AMN model:
memory network可以抓取相关联的重要单词,使用attention机制。
The goal of the AMN model is to automatically capture the pivots.
利用memory network来抽取pivots,这种pivots有两种特性:1)对于情感分类很重要的情感词 2) 这些词在领域之间是共享的。
设计了两个参数共享的深度memory network,一个网络MN-sentiment 用做sentiment分类,一个网络MN-domain用做domain分类,致力于预测样本中的domain labels。
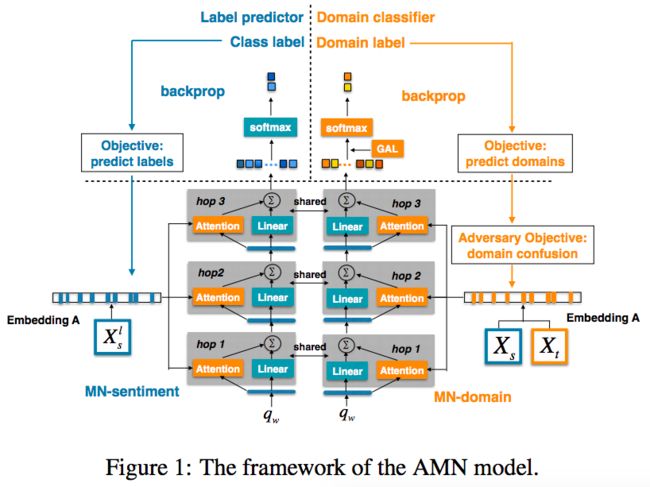
给一个文档d={w1, w2, ..., wn},首先将每个词映射到embedding向量 ei = Awi,文档获得一个向量表示 e = {e1, e2, ..., en}。这些word vectors堆叠起来输入到一个外部的memory。
m是memory size,大于文档的最大长度,free memories用0做填充。每个memory network包括多个hops,每个包含一个attention层和一个linear层。 在第一个hop中,使用query vector qw作为输入通过attention层来抓取memory m中的重要单词。query vector qw是在训练过程中随机初始化的 can be learned for a high-level representation according to the task of interest。
query vector输入后,attention层和线性变换层的输出结合起来作为下一个hop的输入。最后一个hop的输出作为整个document的representation,进一步被用做sentiment分类和domain分类。
对于MN-network,query vector qw可以被看作high-level representation of a fixed query"what is the sentiment word" over words
MN-domain中,给最后一个hop和domain分类器之间增加Gradient Reversal Layer(GRL),用于reverse the gradient direction of the MN-domain network. 用这种方法可以生成一个domain分类器不能预测的表示,最大化domain的confusion。MN-domain使用的query vector可以看作"what is the domain-shared word"。
联合训练,query vector可以看作是“what is the pivot”
Components:
1. Word Attention
MN-sentiment network:根据source领域的有标注的数据来更新external memory ms。
MN-domain network:根据所有来自source领域和target领域的数据来更新external memory md。
首先将每个memory mi 通过放进一个一层的神经网络获得hidden representation hi,通过比较hi和query vector qw的相似度来评价一个词的重要度,获得归一化的重要度权重:
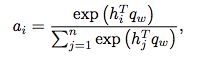
n is the size of the memory occupied, hi=tanh(Wsmi + bs)。不使用全部的memory m,因为我们发现attention模型有时会分配很大的权重在free memories并且分配低的权重在occupied part,这样会降低document representation的质量。free memories的权重都被设置为0.
attention层的输出为:
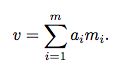
Sentiment Classifier:
将MN-sentiment network的最后一个hop的输出作为document representation vs,然后做softmax分类。
最小化交叉熵
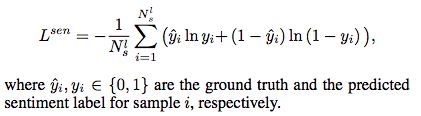
Domain Classifier:
不同的是,在将document representation vd送到softmax之前,vd先送到GRL,在前向传播时,GRL作为一个identity function,但是在bp时,GRL拿到梯度后,乘以 -入
可以将GRL看作一个假函数:
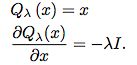
The domain classifier is trained to minimize the cross-entropy for all data from the source and target domains
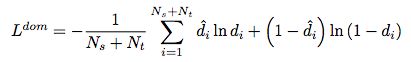
Regularization:
为了避免过拟合,假如来 squared Frobenius norm 给Ws, Wd, 给bias bs,bd增加squared l2 norm regularization:
Joint learning: