作者:侯新烁 湘潭大学 [编译] (知乎 | | 码云)
- Stata连享会 精品专题 || 精彩推文

资料参考来源: The Stata Blog » Monte Carlo simulations using Stata
通过计算机模拟,从总体抽取大量随机样本的计算方法统称为“蒙特卡罗法(Monte Carlo Method,简记为MC)”,这个名字来源于摩纳哥的蒙特卡洛赌场(Monte Carlo Casino),这是最早使用这个方法的一位美国物理学家的叔叔常去的赌场。蒙特卡罗方法长用来确定统计量的小样本性质。,我们知道许多统计量的精确分布没有解析解,通常的处理方法就是应用大样本理论,用渐近分布来近似真实分布,但现实中的样本容量可能不够大,此时蒙特卡罗法的价值就更加凸显了。
在蒙特卡罗模拟中通常需要设计 loop 语句,可能使用的命令有如 forvalues、 foreach 、while ; 也可能需要生成一些随机数据,比如 help random_number_functions 、 help simulate 等,读者可自行查阅进行扩展。
在本次推文中,我们将使用服从卡方分布的随机数据进行蒙特卡洛模拟,分别展示随机数据的均值分布,多个随机均值的生成与保存,以及样本标准误差的蒙特卡洛模拟过程。
1.概览
一个估计量的 蒙特卡罗模拟( Monte Carlo simulation ,MCS)是基于特定的 数据生成过程 ( data-generating process, DGP )和样本量,使用模拟的方法去近似估计量的抽样分布的过程。使用MCS可以考察一个估计方法对特定的数据生成过程的估计表现。在这篇推文中,我们将展示如何对 Stata 中的估计量进行 MCS 模拟以及如何解释结果。
大样本理论告诉我们,当真正的 DGP 是一个来自自由度为 1 的 chi^2 分布的随机样本时(标记为 ),样本平均值是均值的一个很好的估计量。但一位朋友声称这个估计量对于这个 DGP 不会很好,因为 分布会产生异常值。在这篇文章中,使用 MCS 方法,看是否大样本理论可以很好地用于本 DGP 的 500 个观察样本情形。
2.第一个 MCS
我首先从展示如何从 分布中抽取一个样本量为 500 的随机样本,以及如何估计平均值和平均值的标准误差开始。
示例1:模拟数据的平均值
drop _all
set obs 500
set seed 12345
generate y = rchi2(1)
mean y

设置种子 为 12345 ,设置随机数生成器的种子可允许样本结果是可重复的。该随机样本的平均样本平均估计值为 0.91 ,估计的标准误差为 0.055。
若有很多估计,每个估计都来自一个独立的随机样本,我就可以估计估计量的抽样分布均值和标准差。为了获得许多估计,我需要多次重复以下过程:
- 1.从 DGP 中抽取
- 2.计算估算值
- 3.存储估算值
我需要知道如何存储这些估计结果以继续这个过程。我还需要知道如何多次重复该过程以及如何访问 Stata 估计值,鉴于许多读者已经熟悉这些主题,我将这些细节信息附在了附录 I 和 II 中,我们将专注于如何存储如此多的抽样结果。
我想把这些估计结果保存在某处,它们将成为随后可分析数据集的一部分。我将使用命令 postfile , post 和 postclose 将估计值存储在内存中,并在完成后将所有存储的估计值写入一个数据集。示例 2 对有三次抽样过程的情形进行了说明。
示例2:三次抽奖的估计平均值
set seed 12345
postfile buffer mhat using mcs, replace
forvalues i=1/3 {
quietly drop _all
quietly set obs 500
quietly generate y = rchi2(1)
quietly mean y
post buffer (_b[y])
}
postclose buffer
use mcs, clear
list

命令 postfile buffer mhat using mcs, replace 在内存中创建了一个空间叫做 buffer ,在其中我们可以存储将最终写入数据集的结果。mhat 为估计变量的名称,数据集将保存为 mcs.dta 。关键词 using 将新变量名称与新数据集的名称分开。同时,该例中,定义选项 replace 以将 msc.dta 的任何先前版本替换为此处创建的版本。如图可见,我们可以得到 mhat 的三个结果。
具体而言,此例子使用如下循环,重复了计算均值的过程三次。(更多信息可参阅附录 I )。
forvalues i=1/3 {
}
此外,命令
quietly drop _all
quietly set obs 500
quietly generate y = rchi2(1)
quietly mean y
分别执行了 删除以前的数据,从 分布中抽取大小为 500 的样本,并估算平均值的操作。命令语句前的 quietly 表示抑制输出。
命令 post buffer (_b[y]) 将当前抽取的估计平均值存储在缓冲区中,以便下一次观察 mhat 。命令 postclose buffer 将存储在缓冲区中的内容写入文件 mcs.dta 。命令 use mcs, clear; list 从内存中删除最后一个 样本,读入 msc.dta 数据集,并列出数据集。
示例 3 是示例 2 的修改版本; 增加了抽样数量并对结果进行了描述统计。
示例3:2 000 个估计平均值的均值
set seed 12345
postfile buffer mhat using mcs, replace
forvalues i=1/2000 {
quietly drop _all
quietly set obs 500
quietly generate y = rchi2(1)
quietly mean y
post buffer (_b[y])
}
postclose buffer
use mcs, clear
summarize

估计值的平均值是估计量的抽样分布均值的估计值,它接近 1.0 的真值。2 000 个估计的样本标准差是估计量的采样分布的标准差的估计量,并且接近真实值 sqrt {sigma^2/N} = sqrt{2/500} ,约为 0.0632 ),其中 (sigma^2)是 随机变量的方差。
3.包含标准误
基于均值统计量报告的标准误差是估计量的抽样分布的标准误差估计值。若大样本分布在做近似估计的抽样分布时表现良好,估计的标准误均值
应当接近这些平均估计值的样本标准差。
为了将估计量的 标准差 与估计的 标准误 的平均值进行比较,修改了示例3,以存储标准误差信息。
示例4:2 000个标准误差的平均值
set seed 12345
postfile buffer mhat sehat using mcs, replace
forvalues i=1/2000 {
quietly drop _all
quietly set obs 500
quietly generate y = rchi2(1)
quietly mean y
post buffer (_b[y]) (_se[y])
}
postclose buffer
use mcs, clear
summarize
其中,命令 postfile buffer mhat sehat using mcs, replace 在缓冲区为新变量 mhat 和 sehat 腾出空间,并且使用命令
post buffer (_b[y]) (_se[y]) 存储的每个估计的均值 mhat ,和估计的标准误 sehat 。(如示例 3 所示,命令 postclose buffer 将存储在内存中的内容写入新数据文件。)

可见,这 2,000 个估计的样本标准偏差为 0.0625 ,接近 估计的标准误均值 0.0630。
你可能会认为我应该写“非常接近”,但 0.0625 距离 0.0630 究竟有多近?老实说,我们不知道这两个数字是否彼此足够接近,因为它们之间的距离并不能自动地告诉我们结果推论有多么可靠。
4.估计拒绝率
在频率统计中,如果 p 值低于某指定数值,我们拒绝零假设。若大样本分布很好的近似于有限样本分布,对真实的零假设检验,其拒绝率应接近指定的数值大小。
为了比较拒绝率在 5% 时的情形,本推文修改了例子 4 来计算和存储是否拒绝零假设的 Wald 检验 相关指标。
测试与真正的零假设。(机制讨论见附录 Ⅲ )
示例5:估计拒绝率
set seed 12345
postfile buffer mhat sehat reject using mcs, replace
forvalues i=1/2000 {
quietly drop _all
quietly set obs 500
quietly generate y = rchi2(1)
quietly mean y
quietly test _b[y]=1
local r = (r(p)<.05)
post buffer (_b[y]) (_se[y]) (`r')
}
postclose buffer
use mcs, clear
summarize

本例中,通过 local r = (r(p)<.05) 识别了每次估计中 p 是否显著。可见, 0.048 的拒绝率非常接近 0.05 的真实大小。
5.总结
在这篇文章中,我展示了如何在 Stata 中执行估计量的 MCS 。我讨论了使用 post 命令来存储大量估计结果的机制,并讨论了如何解释大量估计的均值和标准误均值内涵。同时,还介绍了使用估计的拒绝率来评价给定DGP和样本量条件下的大样本近似抽样分布的可用性。
示例结果证明,抽样均值表现为与大样笨原理预测的估计量均值一致。当然,这一结论并不意味着我朋友对异常值的担忧完全是错误的。其他对异常值更稳健的估计量可能具有更好的性质。以后的推文中将尝试为这种权衡提供一些证据。
附录
附录I:同一过程的多次重复
本附录简要介绍了局域宏以及如何使用它们进行多次重复命令操作; 相关更多详细信息,请参见 [P] macro and [P] forvalues for more details。(可以 help macro help forvalues)
我们可以在局域宏中存储和访问字符串信息。如将字符串 hello 存储在本地宏命名值中。命令为 local value "hello" ;为了访问存储的信息,需要修饰局域宏的名称。具体来说,在它前面加上单引号 (实际上是英文状态下的 Tab 按键上面按键符号),并用右单引号跟随它。如访问和展示局域宏 value 中的值,可利用 display 在结果窗中展示。也可以将数字存储为字符串。
左边 ` 右边 ' 合起来 `value'
local value "hello"
display "`value'"
local value "2.134"
display "`value'"
要多次重复某些命令,需将它们放在一个 forvalues 循环中。例如,下面的代码重复三次 display 命令。
forvalues i=1/3 {
display "i is now `i'"
}

上面的示例说明 forvalues 定义了一个局域宏,它包含了值列表中的每个值。在前面的示例中,局域宏的名称是 i ,指定的值是 1/3 = {1,2,3 } 。
附录II:获取估计结果
在 Stata 估计命令之后,您可以通过键入 _b[y] 来访问名为 y 的参数的点估计值,也可以通过键入 _se[y] 来访问其标准误。下面的示例说明了此过程。
示例6:访问估计值
drop _all
set obs 500
set seed 12345
generate y = rchi2(1)
mean y
display _b[y]
display _se[y]

附录Ⅲ:通过检验计算获取p值
本附录解释了创建指示 Wald 检验是否会在一个特定的数值上拒绝零假设的指标的机理,首先是要生成一些数据,并对真实的零假设进行 Wald 检验。
示例7:Wald测试结果
drop _all
set obs 500
set seed 12345
generate y = rchi2(1)
mean y
test _b[y]=1
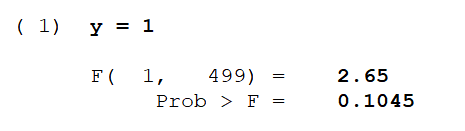
检验的结果被保存在 r() 中。接下来,使用 return list 来查看它们,输入 help return list 以获取详细信息。
示例8:通过测试存储的结果
return list

可以看到,p 值存储在 r(p) 中,接下来生成一个 p 值是否小于 0.05 的 0/1 指示器指标,存储在局域宏 r 中(局域宏的介绍可见附录II)。本文通过展示局域宏包含的信息是 0 来完成说明。
local r = (r(p)<.05)
display "`r'"
代码汇总
drop _all
set obs 500
set seed 12345
generate y = rchi2(1)
mean y
set seed 12345
postfile buffer mhat using mcs, replace
forvalues i=1/3 {
quietly drop _all
quietly set obs 500
quietly generate y = rchi2(1)
quietly mean y
post buffer (_b[y])
}
postclose buffer
use mcs, clear
list
set seed 12345
postfile buffer mhat using mcs, replace
forvalues i=1/2000 {
quietly drop _all
quietly set obs 500
quietly generate y = rchi2(1)
quietly mean y
post buffer (_b[y])
}
postclose buffer
use mcs, clear
summarize
set seed 12345
postfile buffer mhat sehat using mcs, replace
forvalues i=1/2000 {
quietly drop _all
quietly set obs 500
quietly generate y = rchi2(1)
quietly mean y
post buffer (_b[y]) (_se[y])
}
postclose buffer
use mcs, clear
summarize
set seed 12345
postfile buffer mhat sehat reject using mcs, replace
forvalues i=1/2000 {
quietly drop _all
quietly set obs 500
quietly generate y = rchi2(1)
quietly mean y
quietly test _b[y]=1
local r = (r(p)<.05)
post buffer (_b[y]) (_se[y]) (`r')
}
postclose buffer
use mcs, clear
summarize
qui local value "hello"
display "`value'"
qui local value "2.134"
display "`value'"
forvalues i=1/3 {
display "i is now `i'"
}
drop _all
set obs 500
set seed 12345
generate y = rchi2(1)
mean y
display _b[y]
display _se[y]
drop _all
set obs 500
set seed 12345
generate y = rchi2(1)
mean y
test _b[y]=1
return list
local r = (r(p)<.05)
display "`r'"
关于我们
- 【Stata 连享会(公众号:StataChina)】由中山大学连玉君老师团队创办,旨在定期与大家分享 Stata 应用的各种经验和技巧。
- 公众号推文同步发布于 CSDN-Stata连享会 、-Stata连享会 和 知乎-连玉君Stata专栏。可以在上述网站中搜索关键词
Stata或Stata连享会后关注我们。 - 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- Stata连享会 精彩推文1 || 精彩推文2
联系我们
- 欢迎赐稿: 欢迎将您的文章或笔记投稿至
Stata连享会(公众号: StataChina),我们会保留您的署名;录用稿件达五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。 - 意见和资料: 欢迎您的宝贵意见,您也可以来信索取推文中提及的程序和数据。
- 招募英才: 欢迎加入我们的团队,一起学习 Stata。合作编辑或撰写稿件五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。
- 联系邮件: [email protected]
往期精彩推文
- Stata连享会推文列表
- Stata连享会 精品专题 || 精彩推文
