15:结构体、联合体、枚举
15.1:结构体
15.1.1:结构体的定义与使用
定义一个结构有4种形式,建议用typedef:
1:
struct 结构名 {
成员表列
};
struct 结构名 变量名;
2,
struct 结构名 {
成员表列
} 变量名1,变量名2;
3,
struct {
成员表列
} 变量名1,变量名2;
4,
typedef struct _结构名 {
成员表列
} 结构名, *P结构名;
结构名 变量名;
例子:
typedef struct _student {
int id;
int age;
char name[20];
char sex;
float score;
} student, *pstudent;
student s1 = {1001, 19, "tom", 'm', 80.5};
student s2 = {};
s2.id=8;
s2.age=16;
strcpy_s(s2.name,"jerry");
s2.sex='M';
s2.weight=47.05f;
// . 结构体的成员访问
printf("id:%d, age:%d, name:%s, sex:%cm %f\n", s1.id; s1.age, s1.name, s1.sex, s1.score);
printf("id:%d, age:%d, name:%s, sex:%cm %f\n", s2.id; s2.age, s2.name, s2.sex, s2.score);
student *ps1 = &s1;
pstudent ps2 = &s2;
// -> 结构体的指针访问
printf("id:%d, age:%d, name:%s, sex:%cm %f\n", ps1->id; ps1->age, ps1->name, ps1->sex, ps1->score);
printf("id:%d, age:%d, name:%s, sex:%cm %f\n", ps2->id; ps2->age, ps2->name, ps2->sex, ps2->score);
sizeof(ps1);//等价于sizeof(student *);ps1是个指针,x86是4个字节,x64是8个字节。
sizeof(student *);//x86是4个字节,x64是8个字节。
sizeof(*ps1);//等价于sizeof(student)的大小;36字节
sizeof(student);/36字节
*与->、.运算符 关系
->与.运算符比*的优先级高,所以没有括号,先算->和.
15.1.2:结构体中的指针与数组
结构体中成员是一个字符指针,如果要给此成员单独赋值,那么需要单独为name指定内存。
结构体中可以包含指针成员。如:
typedef struct _student {
int age;
char sex;
char \*name;//name成员是一个字符指针,如果要利用name来表示一个人的名字信息,那么需要单独为name指定内存。
}student , \*pstudent;
//如:
student s1={30,’M’,”tom”};//将s1.name指向了静态常量区中的”tom”字符串首地址。
student s2;
s2.age=25;
s2.sex=’F’;
s2.name=(char *)malloc(16);//为s2.name在堆上分配了16个字节的内存,然后把名字拷贝进内存。
strcpy_s(s2.name,16,”susan”);
//结构体中的指针,可以指向同一个类型的结构体地址.
//链表
typedef struct _node {
int value;
struct _node \*next;//next指针指向了同样类型的结构体地址
}node, \*pnode;
//二叉树
typedef struct _btree {
int value;
struct _btree \*left;
struct _btree \*right;
}btree, \*pbtree;
下图在链表_node中,链表的头结点中的next指针指向下一个结点,下一个结点中的next指针又指向下下一个结点,最后一个结点的next指针为NULL。这样,只要知道了链表的头结点,就可以将链表中的所有结点遍历一次。
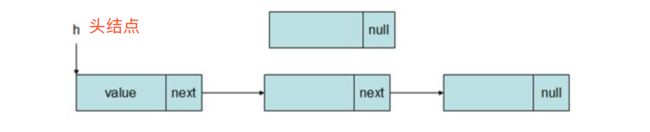
image.png
结构体的定义中,经常会出现下面3种不同的成员定义方法:
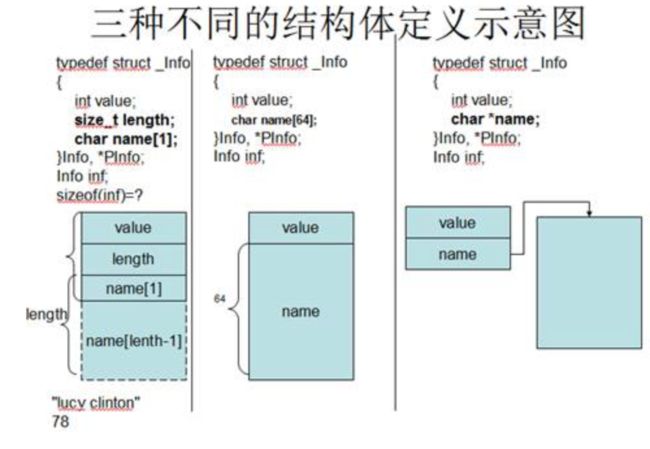
image.png
- 第一种定义方法:name[]是一个包含1个元素的字符数组,与length成员一起用来存放一个变长的数据,即在name后面还有length-1个字节的变长数据。此种结构体经常用于存放变长数据。
- 第二种定义方法:name[]是一个64个元素的字符数组,因此name[]在结构体中占用的内存空间是定长的。此种结构体用来存放数据的时候,数据不能超过指定的长度,而且容易造成部分内存空间的浪费。
- 第三种定义方法:name是一个字符指针,在结构体中占4个字节(X86)或者8个字节(X64),必须为name指定新的内存空间,才能保存相应的数据。
15.1.3:结构体浅拷贝深拷贝写时拷贝
- 浅拷贝(shallow copy):是指在被拷贝的对象中有指针的情况下,只是将目标指针设置为被拷贝指针的值(地址),而不会为目标指针分配一个新的内存,并把数据从被拷贝指针所指的内存中拷贝到这个内存中来。
- 深拷贝(deep copy):是为目标指针申请一个新的内存,然后将数据从被拷贝指针所指的内存中拷贝到这个新申请的内存中来。采用深拷贝,释放内存的时候就不会出现在浅拷贝时重复释放同一内存的错误。
在结构体中默认是浅拷贝
typdef struct _struct1 {
int a;
char b;
}struct1;
struct1 s1 = {1, ‘a’};
struct1 s2 = s1;//因为结构体中不包含指针和数组,那么这个赋值是没有任何问题的。
//下面的结构体定义:
typdef struct _struct2 {
int a;
char *p;
}struct2;//结构体中包含了一个指针成员p。那么试分析下面的代码:
struct2 s1;
s1.a = 10;
s1.p = (char *)malloc(100);
strcpy_s(s1.p,100,”hello world”);
struct1 s2 = s1;
free(s1.p);//这个时候s2.p所指向的内存已经在执行完free(s1.p)之后就被释放了,因此s2.p就是一个野指针了,因为它指向的指针内存已经被释放掉了。
s1.p=NULL;
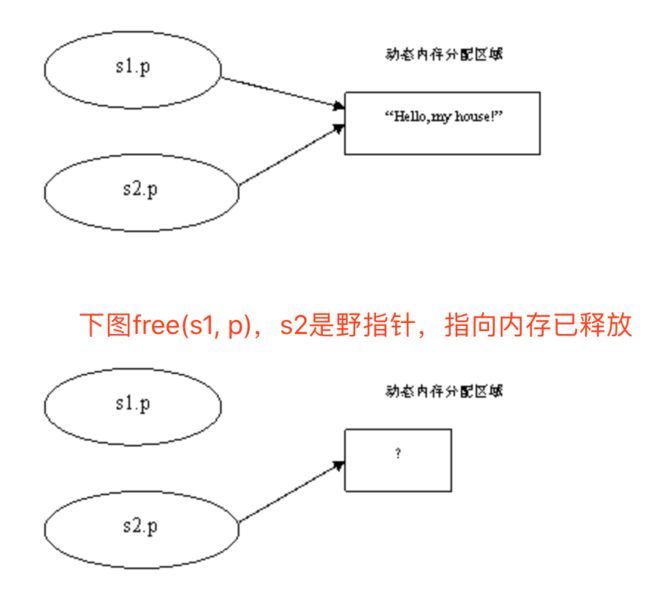
image.png
s1.a = 10;
s1.p = (char *)malloc(100);
strcpy_s(s1.p,100,”hello world”);
struct1 s2;
s2.a=s1.a;
s2.p=(char *)malloc(100);
memcpy(s2.p,s1.p,100);
free(s1.p);
s1.p=NULL;//即使执行了free(s1.p)之后,也不会对s2.p造成任何的影响
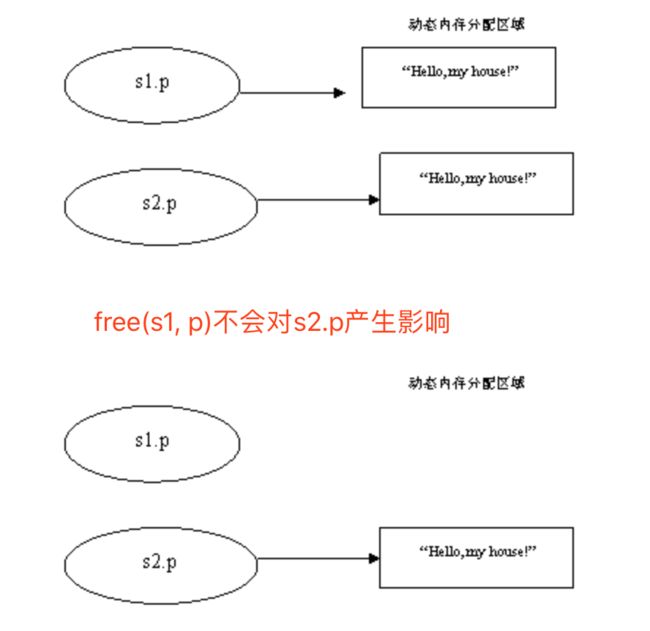
image.png
写时拷贝(copy on write):其实就是对指针所指向的内存用引用计数;释放其实是将引用计数减一,当引用计数为0,释放内存。
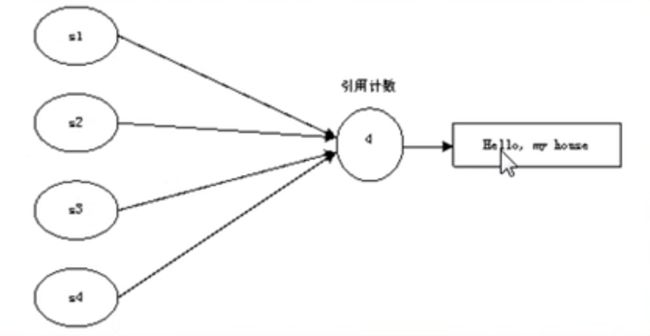
image.png
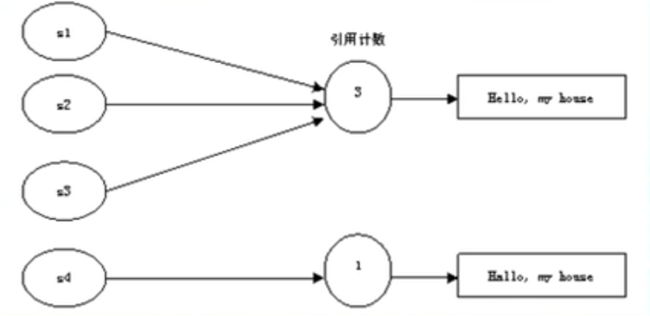
image.png
15.1.4:结构体应用
结构体数组:结构体数据与结构体指针是可以存放在数组中的
typedef struct _student {
int age;
char sex;
char name[20];
} student, *pstudent;
void structPoint(void) {
student *stu3[2];//结构体指针数组(返回指针的数组)
student stus[3]={{25,'M',"tom"},{22,'F',"lucy"},{23,'M',"david"}};//结构体数组与初始化
student stu2[2];//结构体数组
for(int i=0;i<2;i++) {//初始化结构体数组stu2
printf("Please input the age,sex,name(<=20)\n");
fflush(stdin);
scanf_s("%d %c %s",&stu2[i].age,&stu2[i].sex,stu2[i].name,20);
}
for(int i=0;i<2;i++) {//初始化结构体指针数组stu3
stu3[i]=&stu2[i];
}
for(int i=0;i<2;i++) {//遍历结构体指针数组stu3
printf("stu3:age:%d,sex:%c,name:%s\n",
stu3[i]->age,stu3[i]->sex,stu3[i]->name);
}
printf("\n");
for(int i=0;i<3;i++) {//遍历结构体数组stus
printf("stus:age:%d,sex:%c,name:%s\n",stus[i].age,stus[i].sex,stus[i].name);
}
for(int i=0;i<2;i++){//遍历结构体数组stu2
printf("stu2:age:%d,sex:%c,name:%s\n", stu2[i].age,stu2[i].sex,stu2[i].name);
}
return 0;
}
15.1.5:sizeof计算结构体长度
据对齐分为自然对齐和强制对齐两种方式:
- 自然对齐:各个类型自然对齐,即其内存地址必须是其类型本身的整数倍。结构体对齐到其中成员最大长度类型的整数倍。
- 强制对齐:预编译语句将定义的变量强制对齐到n
自然对齐应该遵守如下两条规则:
- 数据成员对齐规则:在默认情况下,各成员变量存放的起始地址相对于结构的起始地址的偏移量:sizeof(它的基本类型)或其倍数;如果该成员为非基本成员,则为其子成员中最大的基本类型的整数倍。
- 整体对齐规则:结构的总大小也有个约束条件:最大sizeof(基本类型)的整数倍
typedef struct _a {
char c1;
long i;
char c2;
double f;
}a;
typedef struct _b {
char c1;
char c2;
long i;
double f;
}b;
//sizeof运行结果如下:
sizeof of double, long, char = 8, 4, 1
sizeof of a, b = 24, 16
为什么对齐?:cpu在一个时钟周期内存取数据,效率高。
强制对齐
遵守如下两条对齐规则:
- 数据成员对齐规则:n字节对齐就是说变量存放的起始地址的偏移量:min(sizeof(基本类型),n)或其倍数。
- 整体对齐规则: 结构的总大小也有个约束条件:min(最大的sizeof(基本类型),n)的倍数。
#pragma pack(push) //保存对齐状态
#pragma pack(n) //定义结构对齐到n
//定义结构//
#pagman pack(pop)//恢复对齐状态
#pragma pack(push)
#pragma pack(8)
struct s1 {
short a;//2
long b;//4
};
struct s2 {
char c;//1
s1 d;//
long long e;//8
};
struct s3 {
char c;
short a;
long b;
long long e;
};
#pragma pack(pop)
//sizeof(s1)=8 sizeof(s2)=24 sizeof(s3)=16
/*
s1:由于#pragma pack(8)要求8字节对齐,但s1中所有成员都比8小,所以各个成员只需要按照自然对齐即可,所以a占2个字节,b占4个字节,a后面需要补齐2字节,才能使long类型的b自然对齐。然后b占4个字节,因此整个s1结构共占用:2+2(pad)+4=8字节。
s2:c占1个字节,d为s1结构体成员,s1结构体成员根据对齐规则,按照其中最大成员long的4字节对齐,所以c之后需要补3字节才能让d达到4字节对齐。对于x86,long long数据类型为8字节,所以存完d后,需要在后面补4个字节,让e 8字节对齐。因此s2结构共占用:1+3(pad)+8+4(pad)+8=24。
s3:c占1个字节,由于a为short类型,所以c之后需要填充1个字节,才能让a对齐。此时,b已经对齐,占4个字节。而e大小为8个字节,已经对齐。所以s3结构共占用:1+1(pad)+2+4+8=16。
*/
15.1.6:栈空间对齐
- 栈形参部分:按照4字节(x86)或者8字节(x64)对齐
- 局部变量区间:变量位置可能变化,char1个字节,short2个字节...
结构体内部对齐规律不变
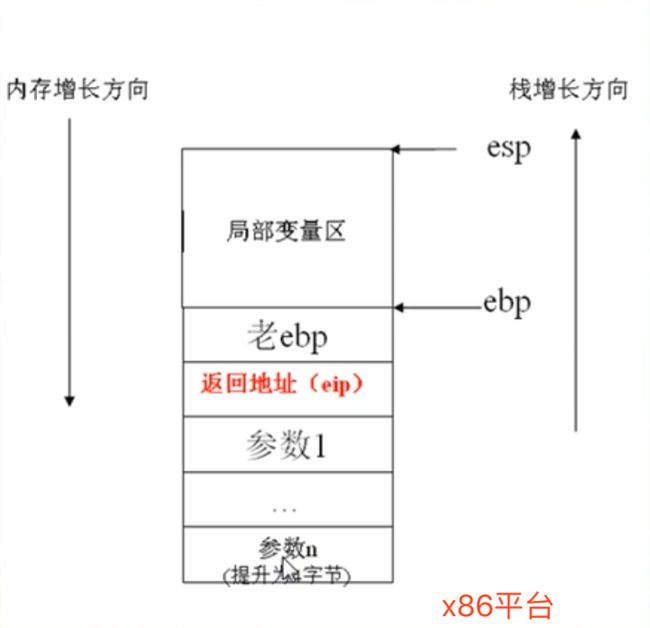
image.png
15.2:联合体(UNION)
联合体(union,又叫共用体):使几种不同类型的变量存放到同一段内存单元中。即使用覆盖技术,几个变量互相覆盖重叠。
定义形式:
1:
union 共用体名 {
数据类型 成员名;
数据类型 成员名;
...
} 变量名;
2:
union 共用体名 {
数据类型 成员名;
数据类型 成员名;
...
};
3:
typedef union {
数据类型 成员名;
数据类型 成员名;
...
} 共用体名;
4:
typedef union _共用体名 {
数据类型 成员名;
数据类型 成员名;
...
}共用体名,*P共用体名;
联合体定义使用时注意点:
- union中可以定义多个成员,union的大小由最大的成员的大小决定。
- union成员共享同一块大小的内存,一次只能使用其中的一个成员。
- 对某一个成员赋值,会覆盖其他成员的值,因为他们共享一块内存。
- union中各个成员存储的起始地址都是相对于基地址的偏移都为0。
联合体和结构体区别:
- 联合体和结构体都由多个不同的数据类型成员组成,但在任何同一时刻,联合体只存放了一个被选中的成员,而结构体的所有成员都存在。
- 对于联合体的不同成员赋值, 会对其它成员重写, 原成员值被覆盖, 而对于结构体的不同成员赋值是互不影响的。
- 结构体里可以含有union成员,union里也可以含结构体成员。
15.2.1:联合体和结构体相互包含
//联合体里包含结构体:
typedef union _Demo {
int a;
struct {
int b;
char c;
}s;
float f;
}Demo;
//结构体中包含联合体:
typedef struct _demo {
union {
int a;
char b;
}c;
int d;
}Demo2;
15.2.2:Union的应用
判断系统是低位优先还是高位优先
typedef union {
char c;
int a;
} U;
int is_integer_lower_store() {
U u;
u.a = 1;
return u.c;
}
15.3:枚举(enum)
枚举(enum):当一个变量的值被限于列出来的值的范围内,那么这个变量就可以被定义为一个枚举类型的变量。
定义形式:
1:
enum 枚举名 {
值1,//如果不额外指定则第一个标识等于整数0,后续依次加1
值2,
值3=7,//注意,值3的值不能被指定为0,1,否则会和值1,值2冲突
值4,//这个时候,值4的值是8
....
值n
};
enum 枚举名 变量名;
2:
typedef enum _枚举名 {
值1,
值2,
值3,
值4,
....
值n
} 枚举名, *P枚举名;