文章来源:Python数据分析
目录:
- DIKW模型与数据工程
- 科学计算工具Numpy
- 数据分析工具Pandas
- Pandas的函数应用、层级索引、统计计算
- Pandas分组与聚合
- 数据清洗、合并、转化和重构
参考学习资料:
http://pandas.pydata.org
1.什么是Pandas?
Pandas的名称来自于面板数据(panel data)和Python数据分析(data analysis)。
Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了 高级数据结构 和 数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
一个强大的分析和操作大型结构化数据集所需的工具集
基础是NumPy,提供了高性能矩阵的运算
提供了大量能够快速便捷地处理数据的函数和方法
应用于数据挖掘,数据分析
提供数据清洗功能
2.Pandas的数据结构
import pandas as pd
Pandas有两个最主要也是最重要的数据结构: Series 和 DataFrame
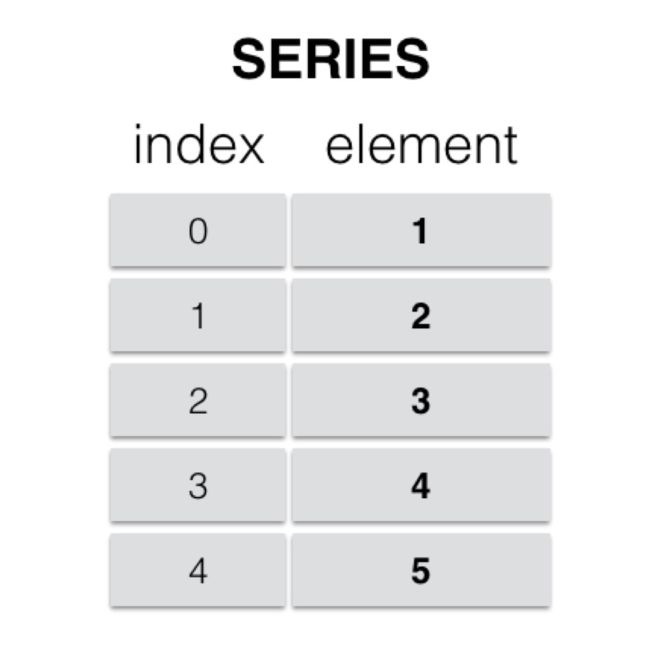
Series
Series是一种类似于一维数组的 对象,由一组数据(各种NumPy数据类型)以及一组与之对应的索引(数据标签)组成。
- 类似一维数组的对象
- 由数据和索引组成
- 索引(index)在左,数据(values)在右
- 索引是自动创建的
1. 通过list构建Series
ser_obj = pd.Series(range(10))
示例代码:
# 通过list构建Series
ser_obj = pd.Series(range(10, 20))
print(ser_obj.head(3))
print(ser_obj)
print(type(ser_obj))
运行结果:
0 10
1 11
2 12
dtype: int64
0 10
1 11
2 12
3 13
4 14
5 15
6 16
7 17
8 18
9 19
dtype: int64
2. 获取数据和索引
ser_obj.index 和 ser_obj.values
示例代码:
# 获取数据
print(ser_obj.values)
# 获取索引
print(ser_obj.index)
运行结果:
[10 11 12 13 14 15 16 17 18 19]
RangeIndex(start=0, stop=10, step=1)
3. 通过索引获取数据
ser_obj[idx]
#通过索引获取数据
print(ser_obj[0])
print(ser_obj[8])
运行结果:
10
18
4. 索引与数据的对应关系不被运算结果影响
示例代码:
# 索引与数据的对应关系不被运算结果影响
print(ser_obj * 2)
print(ser_obj > 15)
运行结果:
0 20
1 22
2 24
3 26
4 28
5 30
6 32
7 34
8 36
9 38
dtype: int64
0 False
1 False
2 False
3 False
4 False
5 False
6 True
7 True
8 True
9 True
dtype: bool
5. 通过dict构建Series
示例代码:
# 通过dict构建Series
year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5}
ser_obj2 = pd.Series(year_data)
print(ser_obj2.head())
print(ser_obj2.index)
运行结果:
2001 17.8
2002 20.1
2003 16.5
dtype: float64
Int64Index([2001, 2002, 2003], dtype='int64')
name属性
对象名:
ser_obj.name对象索引名:
ser_obj.index.name
示例代码:
# name属性
ser_obj2.name = 'temp'
ser_obj2.index.name = 'year'
print(ser_obj2.head())
运行结果:
year
2001 17.8
2002 20.1
2003 16.5
Name: temp, dtype: float64
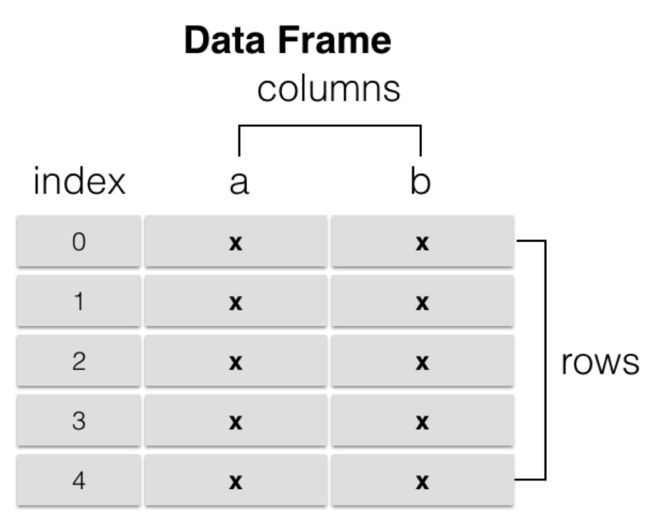
DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同类型的值。DataFrame既有行索引也有列索引,它可以被看做是由Series组成的字典(共用同一个索引),数据是以二维结构存放的。
- 类似多维数组/表格数据 (如,excel, R中的data.frame)
- 每列数据可以是不同的类型
- 索引包括列索引和行索引
1. 通过ndarray构建DataFrame
示例代码:
import numpy as np
# 通过ndarray构建DataFrame
array = np.random.randn(5,4)
print(array)
df_obj = pd.DataFrame(array)
print(df_obj.head())
运行结果:
[[ 0.83500594 -1.49290138 -0.53120106 -0.11313932]
[ 0.64629762 -0.36779941 0.08011084 0.60080495]
[-1.23458522 0.33409674 -0.58778195 -0.73610573]
[-1.47651414 0.99400187 0.21001995 -0.90515656]
[ 0.56669419 1.38238348 -0.49099007 1.94484598]]
0 1 2 3
0 0.835006 -1.492901 -0.531201 -0.113139
1 0.646298 -0.367799 0.080111 0.600805
2 -1.234585 0.334097 -0.587782 -0.736106
3 -1.476514 0.994002 0.210020 -0.905157
4 0.566694 1.382383 -0.490990 1.944846
2.通过dict构建DataFrame
示例代码:
# 通过dict构建DataFrame
dict_data = {'A': 1,
'B': pd.Timestamp('20170426'),
'C': pd.Series(1, index=list(range(4)),dtype='float32'),
'D': np.array([3] * 4,dtype='int32'),
'E': ["Python","Java","C++","C"],
'F': 'ITCast' }
#print dict_data
df_obj2 = pd.DataFrame(dict_data)
print(df_obj2)
运行结果:
A B C D E F
0 1 2017-04-26 1.0 3 Python ITCast
1 1 2017-04-26 1.0 3 Java ITCast
2 1 2017-04-26 1.0 3 C++ ITCast
3 1 2017-04-26 1.0 3 C ITCast
3. 通过列索引获取列数据(Series类型)
df_obj[col_idx]或df_obj.col_idx
示例代码:
# 通过列索引获取列数据
print(df_obj2['A'])
print(type(df_obj2['A']))
print(df_obj2.A)
运行结果:
0 1.0
1 1.0
2 1.0
3 1.0
Name: A, dtype: float64
0 1.0
1 1.0
2 1.0
3 1.0
Name: A, dtype: float64
4. 增加列数据
df_obj[new_col_idx] = data类似Python的 dict添加
key-value
示例代码:
# 增加列
df_obj2['G'] = df_obj2['D'] + 4
print(df_obj2.head())
运行结果:
A B C D E F G
0 1.0 2017-01-02 1.0 3 Python ITCast 7
1 1.0 2017-01-02 1.0 3 Java ITCast 7
2 1.0 2017-01-02 1.0 3 C++ ITCast 7
3 1.0 2017-01-02 1.0 3 C ITCast 7
5. 删除列
del df_obj[col_idx]
示例代码:
# 删除列
del(df_obj2['G'] )
print(df_obj2.head())
运行结果:
A B C D E F
0 1.0 2017-01-02 1.0 3 Python ITCast
1 1.0 2017-01-02 1.0 3 Java ITCast
2 1.0 2017-01-02 1.0 3 C++ ITCast
3 1.0 2017-01-02 1.0 3 C ITCast
3.Pandas的索引操作
索引对象Index
1.Series和DataFrame中的索引都是Index对象
示例代码:
print(type(ser_obj.index))
print(type(df_obj2.index))
print(df_obj2.index)
运行结果:
Int64Index([0, 1, 2, 3], dtype='int64')
2. 索引对象不可变,保证了数据的安全
示例代码:
# 索引对象不可变
df_obj2.index[0] = 2
运行结果:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in ()
1 # 索引对象不可变
----> 2 df_obj2.index[0] = 2
/Users/Power/anaconda/lib/python3.6/site-packages/pandas/indexes/base.py in __setitem__(self, key, value)
1402
1403 def __setitem__(self, key, value):
-> 1404 raise TypeError("Index does not support mutable operations")
1405
1406 def __getitem__(self, key):
TypeError: Index does not support mutable operations
常见的Index种类
- Index,索引
- Int64Index,整数索引
- MultiIndex,层级索引
- DatetimeIndex,时间戳类型
Series索引
1. index 指定行索引名
示例代码:
ser_obj = pd.Series(range(5), index = ['a', 'b', 'c', 'd', 'e'])
print(ser_obj.head())
运行结果:
a 0
b 1
c 2
d 3
e 4
dtype: int64
2. 行索引
ser_obj[‘label’], ser_obj[pos]
示例代码:
# 行索引
print(ser_obj['b'])
print(ser_obj[2])
运行结果:
1
2
3. 切片索引
ser_obj[2:4], ser_obj[‘label1’: ’label3’]
注意,按索引名切片操作时,是包含终止索引的。
示例代码:
# 切片索引
print(ser_obj[1:3])
print(ser_obj['b':'d'])
运行结果:
b 1
c 2
dtype: int64
b 1
c 2
d 3
dtype: int64
- 不连续索引
ser_obj[[‘label1’, ’label2’, ‘label3’]]
示例代码:
# 不连续索引
print(ser_obj[[0, 2, 4]])
print(ser_obj[['a', 'e']])
运行结果:
a 0
c 2
e 4
dtype: int64
a 0
e 4
dtype: int64
5. 布尔索引
示例代码:
# 布尔索引
ser_bool = ser_obj > 2
print(ser_bool)
print(ser_obj[ser_bool])
print(ser_obj[ser_obj > 2])
运行结果:
a False
b False
c False
d True
e True
dtype: bool
d 3
e 4
dtype: int64
d 3
e 4
dtype: int64
DataFrame索引
1. columns 指定列索引名
示例代码:
import numpy as np
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'])
print(df_obj.head())
运行结果:
a b c d
0 -0.241678 0.621589 0.843546 -0.383105
1 -0.526918 -0.485325 1.124420 -0.653144
2 -1.074163 0.939324 -0.309822 -0.209149
3 -0.716816 1.844654 -2.123637 -1.323484
4 0.368212 -0.910324 0.064703 0.486016

2. 列索引
df_obj[[‘label’]]
示例代码:
# 列索引
print(df_obj['a']) # 返回Series类型
print(df_obj[[0]]) # 返回DataFrame类型
print(type(df_obj[[0]])) # 返回DataFrame类型
运行结果:
0 -0.241678
1 -0.526918
2 -1.074163
3 -0.716816
4 0.368212
Name: a, dtype: float64
3. 不连续索引
df_obj[[‘label1’, ‘label2’]]
示例代码:
# 不连续索引
print(df_obj[['a','c']])
print(df_obj[[1, 3]])
运行结果:
a c
0 -0.241678 0.843546
1 -0.526918 1.124420
2 -1.074163 -0.309822
3 -0.716816 -2.123637
4 0.368212 0.064703
b d
0 0.621589 -0.383105
1 -0.485325 -0.653144
2 0.939324 -0.209149
3 1.844654 -1.323484
4 -0.910324 0.486016
高级索引:标签、位置和混合
Pandas的高级索引有3种
1. loc 标签索引
DataFrame 不能直接切片,可以通过loc来做切片
loc是基于标签名的索引,也就是我们自定义的索引名
示例代码:
# 标签索引 loc
# Series
print(ser_obj['b':'d'])
print(ser_obj.loc['b':'d'])
# DataFrame
print(df_obj['a'])
# 第一个参数索引行,第二个参数是列
print(df_obj.loc[0:2, 'a'])
运行结果:
b 1
c 2
d 3
dtype: int64
b 1
c 2
d 3
dtype: int64
0 -0.241678
1 -0.526918
2 -1.074163
3 -0.716816
4 0.368212
Name: a, dtype: float64
0 -0.241678
1 -0.526918
2 -1.074163
Name: a, dtype: float64
2. iloc 位置索引
作用和loc一样,不过是基于索引编号来索引
示例代码:
# 整型位置索引 iloc
# Series
print(ser_obj[1:3])
print(ser_obj.iloc[1:3])
# DataFrame
print(df_obj.iloc[0:2, 0]) # 注意和df_obj.loc[0:2, 'a']的区别
运行结果:
b 1
c 2
dtype: int64
b 1
c 2
dtype: int64
0 -0.241678
1 -0.526918
Name: a, dtype: float64
3. ix 标签与位置混合索引
ix是以上二者的综合,既可以使用索引编号,又可以使用自定义索引,要视情况不同来使用,
如果索引既有数字又有英文,那么这种方式是不建议使用的,容易导致定位的混乱。
示例代码:
# 混合索引 ix
# Series
print(ser_obj.ix[1:3])
print(ser_obj.ix['b':'c'])
# DataFrame
print(df_obj.loc[0:2, 'a'])
print(df_obj.ix[0:2, 0])
运行结果:
b 1
c 2
dtype: int64
b 1
c 2
dtype: int64
0 -0.241678
1 -0.526918
2 -1.074163
Name: a, dtype: float64
注意
DataFrame索引操作,可将其看作ndarray的索引操作
标签的切片索引是包含末尾位置的
4.Pandas的对齐运算
是数据清洗的重要过程,可以按索引对齐进行运算,如果没对齐的位置则补NaN,最后也可以填充NaN
Series的对齐运算
1. Series 按行、索引对齐
示例代码:
s1 = pd.Series(range(10, 20), index = range(10))
s2 = pd.Series(range(20, 25), index = range(5))
print('s1: ' )
print(s1)
print('')
print('s2: ')
print(s2)
运行结果:
s1:
0 10
1 11
2 12
3 13
4 14
5 15
6 16
7 17
8 18
9 19
dtype: int64
s2:
0 20
1 21
2 22
3 23
4 24
dtype: int64
2. Series的对齐运算
示例代码:
# Series 对齐运算
s1 + s2
运行结果:
0 30.0
1 32.0
2 34.0
3 36.0
4 38.0
5 NaN
6 NaN
7 NaN
8 NaN
9 NaN
dtype: float64
DataFrame的对齐运算
- DataFrame按行、列索引对齐
示例代码:
df1 = pd.DataFrame(np.ones((2,2)), columns = ['a', 'b'])
df2 = pd.DataFrame(np.ones((3,3)), columns = ['a', 'b', 'c'])
print('df1: ')
print(df1)
print('')
print('df2: ')
print(df2)
运行结果:
df1:
a b
0 1.0 1.0
1 1.0 1.0
df2:
a b c
0 1.0 1.0 1.0
1 1.0 1.0 1.0
2 1.0 1.0 1.0
2. DataFrame的对齐运算
示例代码:
# DataFrame对齐操作
df1 + df2
运行结果:
a b c
0 2.0 2.0 NaN
1 2.0 2.0 NaN
2 NaN NaN NaN
填充未对齐的数据进行运算
1. fill_value
使用
add,sub,div,mul的同时,通过
fill_value指定填充值,未对齐的数据将和填充值做运算
示例代码:
print(s1)
print(s2)
s1.add(s2, fill_value = -1)
print(df1)
print(df2)
df1.sub(df2, fill_value = 2.)
运行结果:
# print(s1)
0 10
1 11
2 12
3 13
4 14
5 15
6 16
7 17
8 18
9 19
dtype: int64
# print(s2)
0 20
1 21
2 22
3 23
4 24
dtype: int64
# s1.add(s2, fill_value = -1)
0 30.0
1 32.0
2 34.0
3 36.0
4 38.0
5 14.0
6 15.0
7 16.0
8 17.0
9 18.0
dtype: float64
# print(df1)
a b
0 1.0 1.0
1 1.0 1.0
# print(df2)
a b c
0 1.0 1.0 1.0
1 1.0 1.0 1.0
2 1.0 1.0 1.0
# df1.sub(df2, fill_value = 2.)
a b c
0 0.0 0.0 1.0
1 0.0 0.0 1.0
2 1.0 1.0 1.0