本章介绍一个新的叫做CART(分类回归树)的树构建算法。该算法既可以用于分类还可以用于回归,因此非常值得学习。
树回归
优点:可以对复杂和非线性的数据建模
缺点:结果不易理解
使用数据类型:数值型和标称型数据
本章将构建两种树:第一种是9.4节的回归树,第二种是9.5节的模型树。下面给出两种树构建算法中的一些公用代码:
#createTree()
找到最佳的带切分特征:
如果该节点不能再分,将该节点存为叶节点
执行二元切分
在右子树调用createTree()方法
在左子树调用createTree()方法
下面开始构建regTree.py代码
from numpy import *
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float,curLine)#映射成浮点数
dataMat.append(fltLine)
return dataMat
def binSplitDataSet(dataSet, feature, value):#数据集,待切分的特征,该特征的某个值
mat0 = dataSet[nonzero(dataSet[:,feature] > value)[0],:]#nonzero()返回数组的非0部分
mat1 = dataSet[nonzero(dataSet[:,feature] <= value)[0],:]
#下面两行存疑,因为和课本的输出结果不符,要改成上面两行酱紫
# mat0 = dataSet[nonzero(dataSet[:,feature] > value)[0],:][0]#nonzero()返回数组的非0部分
# mat1 = dataSet[nonzero(dataSet[:,feature] <= value)[0],:][0]
return mat0,mat1
In [31]: import regTrees
...: testMat = mat(eye(4))
...: testMat
...:
Out[31]:
matrix([[ 1., 0., 0., 0.],
[ 0., 1., 0., 0.],
[ 0., 0., 1., 0.],
[ 0., 0., 0., 1.]])
In [32]: mat0,mat1 = regTrees.binSplitDataSet(testMat,1,0.5)
In [33]: mat0
Out[33]: matrix([[ 0., 1., 0., 0.]])
In [34]: mat1
Out[34]:
matrix([[ 1., 0., 0., 0.],
[ 0., 0., 1., 0.],
[ 0., 0., 0., 1.]])
切分成功
下面开始介绍chooseBestSplit(),该函数的目标是找到数据集切分的最佳位置
对每个特征:
对每个特征值:
将数据集切分成两份
计算切分的误差
如果当前误差小于当前最小误差,那么将当前切分设定为最佳切分并更新最小误差
返回最佳切分的特征
#切分函数和创建树函数,refLeaf和regErr要写在前面,一开始犯了这个低级错误...
def regLeaf(dataSet):#生成叶子结点
return mean(dataSet[:,-1])
def regErr(dataSet):
return var(dataSet[:,-1]) * shape(dataSet)[0]#方差函数*样本个数=总方差
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):#数据集,叶节点函数,误差计算函数,树构建所需要的其他参数
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)
if feat == None: return val
retTree = {}
retTree['spInd'] = feat
retTree['spVal'] = val
lSet, rSet = binSplitDataSet(dataSet, feat, val)
retTree['left'] = createTree(lSet, leafType, errType, ops)
retTree['right'] = createTree(rSet, leafType, errType, ops)
return retTree
def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):
#对创建叶节点的函数引用,总方差计算函数的引用,用户定义的参数构成的元组
tolS = ops[0]; tolN = ops[1]#误差下降值,最小样本数
if len(set(dataSet[:,-1].T.tolist()[0])) == 1: #所有值相等
return None, leafType(dataSet)
m,n = shape(dataSet)
S = errType(dataSet)
bestS = inf; bestIndex = 0; bestValue = 0
for featIndex in range(n-1):
for splitVal in set((dataSet[:,featIndex].T.A.tolist())[0]):
#for splitVal in set(dataSet[:,featIndex]):
mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): continue
newS = errType(mat0) + errType(mat1)
if newS < bestS:
bestIndex = featIndex
bestValue = splitVal
bestS = newS
#如果误差不大,不切分直接创建叶节点
if (S - bestS) < tolS:
return None, regLeaf(dataSet)
mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): #切分数据集过小
return None, leafType(dataSet)
return bestIndex,bestValue
In [10]: import regTrees
...: myDat = regTrees.loadDataSet('ex00.txt')
...: myMat = mat(myDat)
...: regTrees.createTree(myMat)
...:
Out[10]:
{'left': 1.0180967672413792,
'right': -0.044650285714285719,
'spInd': 0,
'spVal': 0.48813}
下面开始构建一颗回归树:
In [5]: import regTrees
...: myDat1 = regTrees.loadDataSet('ex0.txt')
...: myMat1 = mat(myDat1)
...: regTrees.createTree(myMat1)
...:
Out[5]:
{'left': {'left': {'left': 3.9871631999999999,
'right': 2.9836209534883724,
'spInd': 1,
'spVal': 0.797583},
'right': 1.980035071428571,
'spInd': 1,
'spVal': 0.582002},
'right': {'left': 1.0289583666666666,
'right': -0.023838155555555553,
'spInd': 1,
'spVal': 0.197834},
'spInd': 1,
'spVal': 0.39435}
到目前为止,已经完成回归树的构建,但是需要某种措施来检查构建过程是否得当。下面介绍剪枝函数。
通过降低决策树的复杂度来避免过拟合的过程称为剪枝。函数chooseBestSplit()中的提前终止条件,实际上就是所谓的剪枝操作。另外一种剪枝需要使用测试集和训练集,称为后剪枝。
树构建算法其实对输入的参数tolS和tolN非常敏感,如果使用其他值将不太容易达到这么好的效果。
为了说明这一点,在Python提示符下输入如下:
In [27]: regTrees.createTree(myMat,ops=(0,1))
Out[27]:
{'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': 1.035533,
'right': 1.077553,
'spInd': 0,
'spVal': 0.993349},
'right': {'left': 0.74420699999999995,
#太长省略。。。
这里构建的树过于臃肿,它甚至为数据集中每个样本都分配了一个叶节点。
In [30]: myDat2 = regTrees.loadDataSet('ex2.txt')
...: myMat2 = mat(myDat2)
...: regTrees.createTree(myMat2)
...:
Out[30]:
{'left': {'left': {'left': {'left': 105.24862350000001,
'right': 112.42895575000001,
'spInd': 0,
'spVal': 0.958512},
'right': {'left': {'left': {'left': {'left': 87.310387500000004,
'right': {'left': {'left': 96.452866999999998,
'right': {'left': 104.82540899999999,
'right': {'left': 95.181792999999999,
'right': 102.25234449999999,
'spInd': 0,
'spVal': 0.872883},
'spInd': 0,
'spVal': 0.892999},
'spInd': 0,
'spVal': 0.910975},
'right': 95.275843166666661,
'spInd': 0,
'spVal': 0.85497},
'spInd': 0,
'spVal': 0.944221},
'right': {'left': 81.110151999999999,
'right': 88.784498800000009,
'spInd': 0,
'spVal': 0.811602},
#省略部分
停止条件tolS对误差的数量级十分敏感。如果在选项中花费时间并对上述误差容忍度去平方值,或许也能得到仅有两个叶子结点组成的树:
In [32]: regTrees.createTree(myMat2,ops=(10000,4))
Out[32]:
{'left': 101.35815937735848,
'right': -2.6377193297872341,
'spInd': 0,
'spVal': 0.499171}
使用后剪枝需要将数据集分成测试集和训练集。首先指定参数,使得构建出的树足够大、足够复杂,便于剪枝。接下来从上而下找到叶节点,用测试集来判断将这些叶节点合并是否能降低测试误差。如果是的话就合并,函数prune()的伪代码如下:
基于已有的树切分测试数据:
如果存在任一子集是一棵树,则在该子集递归剪枝过程
计算将当前两个叶节点合并后的误差
计算合并的误差
如果合并会降低误差的话,就将叶节点合并
In [33]: myTree = regTrees.createTree(myMat2,ops=(0,1))#创建最大的树
In [34]: myDatTest = regTrees.loadDataSet('ex2test.txt')
In [35]: myMat2Test = mat(myDatTest)
In [36]: regTrees.prune(myTree,myMat2Test)
merging
merging
merging
#省略大量merging
merging
Out[36]:
{'left': {'left': {'left': {'left': 92.523991499999994,
'right': {'left': {'left': {'left': 112.386764,
'right': 123.559747,
'spInd': 0,
'spVal': 0.960398},
'right': 135.83701300000001,
'spInd': 0,
'spVal': 0.958512},
'right': 111.2013225,
'spInd': 0,
'spVal': 0.956951},
'spInd': 0,
'spVal': 0.965969},
'right': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': {'left': 96.41885225,
'right': 69.318648999999994,
'spInd': 0,
'spVal': 0.948822},
'right': {'left': {'left': 110.03503850000001,
'right': {'left': 65.548417999999998,
'right': {'left': 115.75399400000001,
#省略部分结果
可以看到大量的节点以及被减掉,但没有像预期的那样剪枝成两部分,这说明后剪枝可能不如预剪枝有效。一般的,为了寻求最佳模型,可以同时使用两种剪枝技术。
用树来对数据建模,除了把叶节点简单地设定为常数值之外,还有一种方法是把节点设定为分段线性函数,这里所谓的分段线性是指模型由多个线性片段组成。
In [39]: myMat2 = mat(regTrees.loadDataSet('exp2.txt'))
In [40]: regTrees.createTree(myMat2,regTree.modelLeaf,regTrees.modelErr,(1,10))
Traceback (most recent call last):
In [41]: regTrees.createTree(myMat2,regTrees.modelLeaf,regTrees.modelErr,(1,10))
Out[41]:
{'left': matrix([[ 1.69855694e-03],
[ 1.19647739e+01]]), 'right': matrix([[ 3.46877936],
[ 1.18521743]]), 'spInd': 0, 'spVal': 0.285477}
见课本图9-5,与真实模型非常接近。
前面介绍了模型树,回归树和一般的回归方法,下面测试一下哪个模型最好。
In [39]: trainMat = mat(regTrees.loadDataSet('bikeSpeedVsIq_train.txt'))
...: testMat = mat(regTrees.loadDataSet('bikeSpeedVsIq_test.txt'))
...: myTree = regTrees.createTree(trainMat,ops=(1,20))
...: yHat = regTrees.createForeCast(myTree, testMat[:,0])
...: corrcoef(yHat, testMat[:,1], rowvar=0)[0,1]
...:
Out[39]: 0.96408523182221406
同样的,再创建一颗模型树:
In [40]: myTree = regTrees.createTree(trainMat,regTrees.modelLeaf,regTrees.modelErr,(1,20))
In [42]: yHat = regTrees.createForeCast(myTree,testMat[:,0],regTrees.modelTreeEval)
In [44]: corrcoef(yHat,testMat[:,1],rowvar=0)[0,1]
Out[44]: 0.97604121913805941
R²越接近1.0越好,所以从上面的结果我们可以看出,这里模型树的结果比回归树的结果好。下面我们看标准的线性回归效果如何:
In [5]: ws,X,Y = regTrees.linearSolve(trainMat)
In [6]: ws
Out[6]:
matrix([[ 37.58916794],
[ 6.18978355]])
为了得到测试集上所有的yHat预测值,在测试数据上循环运行:
In [12]: for i in range(shape(testMat)[0]):
...: yHat[i] = testMat[i,0]*ws[1,0] + ws[0,0]
...:
In [13]: corrcoef(yHat, testMat[:,1], rowvar=0)[0,1]
Out[13]: 0.94346842356747662
可以看到,该方法在R²值上表现上面两种树回归方法。所以,树回贵州预测复杂数据上会比简单线性模型更有效。
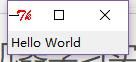
Python中有很多GUI框架,其中一个易于使用的Tkinter,是随Python的标准编译版本发布的。下面是一个简单的Hello World:
In [23]: from Tkinter import *
...:
...: root = Tk()
...:
...: myLabel = Label(root, text='Hello World')
...:
...: myLabel.grid()
...:
...: root.mainloop()
...:
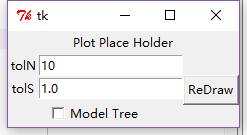
from numpy import *
from Tkinter import *
import regTrees
def reDraw(rolS,tolN):
pass
def drawNewTree():
pass
root = Tk()
Label(root, text='Plot Place Holder').grid(row=0, columnspan=3)
Label(root, text='tolN').grid(row=1, column = 0)#行和列的位置
tolNentry = Entry(root)#输入文本框
tolNentry.grid(row=1,column=1)
tolNentry.insert(0,'10')
Label(root, text="tolS").grid(row=2, column=0)
tolSentry = Entry(root)
tolSentry.grid(row=2, column=1)
tolSentry.insert(0,'1.0')
Button(root, text="ReDraw", command=drawNewTree).grid(row=1, column=2, rowspan=3)
chkBtnVar = IntVar()
chkBtn = Checkbutton(root, text="Model Tree", variable = chkBtnVar)#复选文本框
chkBtn.grid(row=3, column=0, columnspan=2)
reDraw.rawDat = mat(regTrees.loadDataSet('sine.txt'))
reDraw.testDat = arange(min(reDraw.rawDat[:,0]),max(reDraw.rawDat[:,0]),0.01)
reDraw(1.0, 10)
root.mainloop()