总结
unique_ptr指针的一些特性总结
- 默认情况下,占用的内存大小和raw指针一样。(除非指定了用户自定义deleter);
- 运行过程中unique_ptr消耗资源和raw指针一样;
- unique指针只可以进行转移操作,不能拷贝、赋值。所以unique指针作为函数入参类型的时候,函数的调用方必须使用转移语义;
- 允许在定义unique指针的时候,指定用户自定义的指针销毁函数(在指针析构的时候会回调)
- 从一个unique指针转换成shared指针很容易
使用场景
- 用作工厂函数的返回类型
适合的原因有两个
- 工厂函数负责在heap上创建对象,但是调用工厂函数的用户才会真正去使用这个对象,并且要负责这个对象生命周期的管理。所以使用unique指针是最好的选择。
- 第二个原因是unique指针转换成shared指针很容易,作为工厂函数本身并不知道用户希望所创建的对象的所有权是专有的还是共享,这个时候返回unique指针,作为函数的调用方可以按照需要做变换。
写了个示例
#include
#include
class Investment
{
public:
Investment() {std::cout << "[unique_ptr]: Investment construction" << std::endl; }
virtual ~Investment() {std::cout << "[unique_ptr]: Investment destruction" << std::endl; }
};
class Stock : public Investment
{
public:
Stock() { std::cout << "[unique_ptr]: Stock construction" << std::endl; }
~Stock() { std::cout << "[unique_ptr]: Stock destruction" << std::endl; }
};
std::unique_ptr
makeInvestment()
{
std::unique_ptr pInv{nullptr};
pInv.reset(new Stock());
return pInv;
}
int main(int argc, char* argv[])
{
{
auto up = makeInvestment();
std::cout << "[unique_ptr]: up(raw_ptr): " << up.get() << std::endl;
}
std::cout << "[unique_ptr]: End of main!" << std::endl;
}
运行结果如下
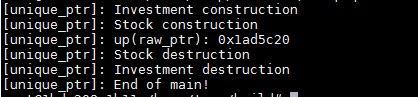
可以看到,离开{}的作用域后,unique指针up的生命周期就结束了,会自动调用所指向对象的析构函数销毁所指向对象。所以类的析构函数调用在End of main这句打印之前。
- PIMPL(pointer to implementation)风格
关于unique_ptr指针的move-only特性
参看如下一段代码
#include
#include
#include
int main(int argc, char* argv[])
{
std::unique_ptr up = std::make_unique(5);
std::cout << "up before send: " << up.get() << std::endl;
std::vector> upv;
// move语义在这里会解除up指针对raw指针的所有权,但实际上raw指针所指向对象并没有被释放
upv.push_back(move(up));
std::cout << "request after send: " << up.get() << std::endl;
}
这段代码里面如果直接把up指针作为push_back函数的入参,编译会报错。只有加上move语义之后才能正常编译,而这个时候up指针已经不再拥有之前它所管理的raw指针的所有权了。raw指针的所有权变更到了vector中的一个unique_ptr类型元素上了。下图是运行的结果
可以看到,运行完push_back语句后,up内保存的raw指针就置为空了。
更多内容请参看原文翻译。
原文翻译
当你刚刚开始接触智能指针的时候,std::unique_ptr应该最容易上手的。有理由相信,默认情况下,std::unique_ptr指针和普通指针拥有一样的大小。并且对于大多数的操作(包括deferencing),std::unique_ptr执行和普通指针一样的指令。这就意味着即使在内存和CPU都很紧张的情况下,你也可以使用这个指针。如果普通指针(raw pointer)对于你来说足够的省内存并且足够的快,那么std::unique_ptr也基本上一样,你可以放心使用。
std::unique_ptr体现了专属所有权语义。一个非空std::unique_ptr指针通常拥有它所指向对象的全部所有权。转移一个std::unique_ptr指针意味着从源指针转移所有权到目的指针(源指针会被置成null)。std::unique_ptr指针的拷贝是非法的,因为如果你可以拷贝一个std::unique_ptr,你就会得到两个std::unique_ptr,而这两个指针指向同一个地方并且都认为自己拥有指向对象的所有权。所以std::unique_ptr是一种move-only的类型。对于析构函数,一个非空的std::unique_ptr销毁自己的资源。默认的,资源的销毁是通过std::unique_ptr内部的delete raw指针来实现的。
std::unique_ptr最常见的一个用法是作为工厂函数的返回类型,这个工厂函数用来生产一个继承结构的类的对象。假设我们有这样一个基类Investement,然后有一些列关于投资的继承类型(例如,股票,物业等等),实现伪代码如下,
class Investment { ... };
class Stock:
public Investment { ... };
class Bond:
public Invectment { ... };
class RealEstate:
public Investment { ... };
一个相应的工厂函数来在堆(heap)上构造一个这些继承类的对象,然后返回指向这些对象的指针,工厂函数的调用者就需要负责在不需要使用对象的时候销毁这个对象。这应用场景完全匹配指针std::unique_ptr,因为调用者获取了工厂函数返回资源的所有权,当指向资源的std::unique_ptr销毁的时候,智能指针会负责自动销毁它所指向的对象。这个工厂函数定义如下,
template // 利用给定的参数params来创建一个Investment对象,然后返回std::unique_ptr指针
std::unique_ptr
makeInvestment(Ts&&.. params)
工厂函数的调用方可以在一个作用域内({}括起来的范围)如下的使用这个返回的指针,
{
...
auto pInvestment = // pInvestment 的类型是std::unique_ptr
makeInvestment(arguments);
...
} // 销毁*pInvestment
除此之外,std::unique_ptr指针也可以用在所有权转移的场景下,比如说当工厂函数返回std::unique_ptr指针转移进一个容器,下一步容器元素转移进一个类对象的成员数据,然后这个对象被销毁掉。当这种情况发生时,对象的std::unique_ptr类型的数据成员也会被销毁,析构函数会触发销毁之前工厂函数中分配的资源。如果这样的所有权链由于一些异常被破坏了(比如说,中间某个函数返回了或者从循环中break出来了,指针的转移没有继续往下进行),转移过程中最后一个std::unique_ptr指针始终拥有它所指向资源的管理权,当这个指针被销毁了,那么对应的资源也会被释放。
Note:
这个规则这里还有一些异常场景。大多来自于异常的程序终止,如果异常是从线程的主函数里传递出来的(比如说,main函数,用于程序的初始线程)或者是由于noexcept规范是非法的(参看Item 14),局部对象可能没有被销毁掉。如果是由于调用了std::abort或者是一个exit函数导致的退出,这些指针都不会被销毁。
缺省情况下,std::unique_ptr的析构函数会调用delete来释放raw指针。但是在构造函数过程中,std::unique_ptr对象也可以配置成使用用户自定义的deleters:当指针指向的资源要被释放的时候可以调用任意函数(或者是函数对象,包括lambda表达式)。如果通过调用工厂函数makeInvestment创建的对象不应该被直接delete掉,而是在这之前需要记录一下,这个时候makeInvestment可以按照如下伪代码进行实现(后面会有这段代码的解释)
auto delInvmt = [](Investment* pInvestment) // 用户自定的deleter,labmda表达式
{
makeLogEntry(pInvestment);
delete pInvestmentl;
}
template
std::unique_ptr
makeInvestment(Ts&&... params)
{
std::unique_Ptr pInv(nullptr, delInvmt);
if( /*需要创建一个Stock对象*/ )
{
pInv.reset(new Stock(std::forward(params)...))
}
else if ( /*需要创建一个Bond对象*/ )
{
pInv.reset(new Bond(std::forward(params)...))
}
else if( /*需要创建一个RealEstate对象*/ )
{
pInv.reset(new RealEstate(std::forward(params)...))
}
return pInv
}
稍等一会儿,我会解释一下这段代码是怎么工作的。但是首先从函数调用者的角度来看看,整个过程是怎么工作的。假如把makeInvestment函数调用的返回结果保存到auto类型的变量,虽然实际上这个指针所指向的资源在销毁过程中需要一些特殊的处理,然而作为调用者完全不需要关心这些。实际上,你可能还沉浸在幸福中,因为使用了std::unique_ptr就意味着你不需要关心在生命周期结束的时候去释放资源,更不需要去保证析构函数在整个程序中只会被调用一次。std::unique_ptr指针会自动管理所有的事情,从用户的角度来说,makeInvestment函数提供的接口非常好。
当你理解了下面这些之后,上述的代码实现就更加完美了,
首先表达式
delInvemt是用户自定义的删除函数,会用于makeInvestment函数所构造的对象中。所有的用户自定义删除函数都要携带一个raw指针做为函数的输入,这个raw指针指向需要销毁的对象,然后函数里面会实现销毁这个对象所需要完成的行为。在这个例子里,自定义的删除函数要做的是调用makeLogEntry并且delete raw指针。使用lambda表达式来实现delInvmt函数是很方便的,而且我们很快会看到,使用lambda表达式比传统的函数更加高效。当使用用户自定的删除函数的时候,这个自定义函数的类型必须被指定成
std::unique_ptr的第二个参数类型。这个例子里面,就是delInvmt的类型,这就是为什么工厂函数的返回类型是std::unique_ptrmakeInvestment函数的基本策略是创建一个空的std::unique_ptr指针,先让这个指针指向一个合适的类型。可以看到,函数delInvmt作为std::unique_ptr构造函数的第二个参数传递进去,通过这样的方式来指定用户自定的删除函数直接把一个raw指针(比如说new出来的)赋值给一个
std::unique_ptr指针会编译不通过,因为这等同于一个从raw指针到智能指针的隐式类型转换。这样的类型转换有可能会有问题,所以C++11里的规则是禁止这样的转换。这就是为什么这里要用reset函数来指定pInv指针对与new函数创建出来的对象的所有权。在每个
new函数使用的时候,我们用了std::forward来进行完美转移makeInvestment的入参(参看Item 25)。这样一来,新建对象的构造函数就能获取所有工厂函数的调用者所提供的信息。用户自定义删除函数的入参类型是
Investment*。不考虑makeInvestment函数所创建的对象的实际类型(比如说Stock,Bond或是RealEstate),lambda表达式中始终只会去销毁一个Investment*类型的对象。这就意味着我们会通过一个基类指针来删除一个派生类的对象,这就需要我们在基类里面定义一个虚析构函数,这样一来对象的delete才能正常工作。
class Investment {
public:
...
virtual ~Investment(); // 必要的
...
};
在C++14里面,由于引入了函数返回类型推导(参看Item 3),makeInvestment函数的实现可以变得更加简单并且封装得更好:
tempate
auto makeInvestment(Ts&&... params) // C++14的版本
{
auto delInvmt = [](Investment* pInvestment) // 自定义函数现在可以挪到工厂函数内部了
{
makeLogEntry(pInvestment);
delete pInvestment;
};
std::unique_ptr pInv(nullptr, delInvmt); // 和之前一样
if( ... )
{
pInv.reset(new Stock(std::forward(params)...));
}
else if ( … ) // as before
{
pInv.reset(new Bond(std::forward(params)...));
}
else if ( … ) // as before
{
pInv.reset(new RealEstate(std::forward(params)...));
}
return pInv;
}
我之前说过,当使用默认的指针销毁函数delete的时候,你可以假设std::unique_ptr对象和raw指针的占用内存大小是一样的。当用户自定义的deleter引入之后,这种假设就不再成立了。自定义的deleters实际上是一个函数指针,所有std::unique_ptr的大小会从一个word变成两个。对于类型为函数对象的deleters,增加的大小就取决于函数内部的保存了多少状态了。stateless的函数对象(比如说,lambda表达式并且没有错误捕获)就没有指针大小上的变化。这就意味着如果用户自定的deleter即可以实现成函数,也可以实现成没有错误捕获的lambda表达式的时候,优先选择lambda表达式
auto delInvmt1 = [](Investment* pInvestment) // 用户自定义deleter实现成stateless的lambda表达式
{
makeLogEntry(pInvestment);
delete pInvestment;
}
template // 返回类型和Investment*的大小一致
std::unique_ptr
makeInvestment(Ts&&.. args);
void delInvmt2(Investment* pInvestment) // 实现成函数的用户自定义deleter
{
makeLogEntry(pInvestment);
delete pInvestment;
}
template // 返回类型的大小 = Investment*的大小 + 至少函数指针的大小
std::unique_ptr
makeInvestment(Ts&&... params);
如果作为deleters的函数对象里面还有额外的状态,这可能会导致std::unique_ptr指针对象的大小变得很大。如果你发现一个用户自定的deleter使你的指针变得非常之大的时候,你就要考虑是不是是需要对你的代码进行重构。
工厂函数并不是是唯一一个std::unique_ptr指针常用的场景。在进行PIMPL(pointer to implementation)风格实现的时候,std::unique_ptr的使用更加常见。代码实现并不复杂,但是却不是那么直观,所以我建议你去看一下Item 22,哪里会专门讲一下这个场景。
std::unique_ptr指针有两种实现形式,一种用于单一对象(std::unique_ptr),另一种用于数组(std::unique_ptr)。这样的结果就是,对于std::unique_ptr所指向的对象到底是啥就不会产生歧义了。并且,对应这两种不同的unique_ptr指针实现也设计实现了不同的API。举个例子来说,对于单一对象(single-object)的形式,就不会有索引操作符“[]”,而数组对象(array)则没有解引用操作(操作符"*"和操作符"->")
因为相较于原始的指针数组,标准库中提供的std::array,std::vector和std::string都是更好的选择。所以这里我能想到的唯一的一个适合用std::unique_ptr的场景就是,如果你在使用一个C风格的API,返回了一个普通的指针并保存在一个分配在heap上数组中,而这个时候你又需要设定这个数组的所有权。
std::unique_ptr是C++11中用来声明所分配资源专属所有权(exclusive ownership)的一种方式,然而另一个非常具有吸引力的特性是,unique_ptr可以很容易并且很有效的转换成std::shared_ptr:
std::shared_ptr sp = // std::unique_ptr转换成std::shared_ptr
makeInvestment( arguments );
这也是为什么std::unique_ptr非常适合用作工厂函数的返回类型的一个关键部分。工厂函数没有办法知道调用者是想要使用所创建对象的专属所有权语义(exclusive ownership)呢,还是共享所有权(shared ownership)更加合适。通过使用std::unique_ptr,工厂函数一方面提供给了调用者最高效的智能指针,另一方面它也没有阻碍调用者用它更加灵活的同类(比如说shared_ptr)来替换它。(更多关于std::shared_ptr的内容请参看Item 19)
记住下面几点
-
std::unique_ptr是一个小的,快速的,只能转移操作的(move-only)的智能指针,只能用来管理具有专属所有权语义的资源。 - 缺省情况下,资源的析构是通过
delete来完成的,但是也可以指定用户自定义的deleters。stateful deleters和函数指针作为deleters都会增加std::unique_ptr对象的大小 - 转换
std::unique_ptr到std::shared_ptr非常容易