摘要: 回顾大数据技术领域大事件,最早可追溯到06年Hadoop的正式启动,而环顾四下,围绕着数据库及数据处理引擎,业内充斥着各种各样的大数据技术。在云栖社区2017在线技术峰会大数据技术峰会上,阿里云大数据计算平台架构师林伟做了题为《MaxCompute的大脑:基于代价的优化器》的分享,为大家分享阿里巴巴大数据计算服务的大脑——基于代价的优化器的设计和架构。
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
摘要:回顾大数据技术领域大事件,最早可追溯到06年Hadoop的正式启动,而环顾四下,围绕着数据库及数据处理引擎,业内充斥着各种各样的大数据技术。这是个技术人的好时代,仅数据库领域热门DB就有300+,围绕着Hadoop生态圈的大数据处理技术更是繁花似锦。在云栖社区2017在线技术峰会大数据技术峰会上,阿里云大数据计算平台架构师林伟做了题为《MaxCompute的大脑:基于代价的优化器》的分享,为大家分享阿里巴巴大数据计算服务的大脑——基于代价的优化器的设计和架构。
MaxCompute简介
大数据计算服务(MaxCompute)是一种快速、完全托管的PB/EB级数据仓库解决方案,MaxCompute具备万台服务器扩展能力和跨地域容灾能力,是阿里巴巴内部核心大数据平台,承担了集团内部绝大多数的计算任务,支撑每日百万级作业规模。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。
MaxCompute架构

MaxCompute基本的体系结构如上图所示,最底层就是在物理机器之上打造的提供统一存储的盘古分布式文件存储系统;在盘古之上一层就是伏羲分布式调度系统,这一层将包括CPU、内存、网络以及磁盘等在内的所有计算资源管理起来;再上一层就是统一的执行引擎也就是MaxCompute执行引擎;而在执行引擎之上会打造各种各样的运算模式,比如流计算、图计算、离线处理、内存计算以及机器学习等等;在这之上还会有一层相关的编程语言,也就是MaxCompute语言;在语言上面希望为各应用方能够提供一个很好的平台,让数据工程师能够通过平台开发相关的应用,并使得应用能够快速地在分布式场景里面得到部署运行。
MaxCompute的研发思路

MaxCompute的研发思路主要分为以下四个方面:
高性能、低成本和大规模。希望打造的MaxCompute平台能够提运算的高性能,尽可能降低用户的使用成本,并且在规模上面能够达到万台机器以及多集群的规模。
稳定性,服务化。希望MaxCompute平台能够提供稳定性和服务化的方式,使得用户不用过多地考虑分布式应用的难度,而只需要注重于用户需要进行什么样的计算,让系统本身服务于用户,并能够提供稳定性,服务化的接口。
易用性,服务于数据开发者。希望MaxCompute平台是易用的,并且能够很方便地服务于数据开发工程师,不需要数据工程师对于分布式的场景进行很深的理解,而只要关注于需要用这些数据进行什么样的运算就可以,接下来就是由MaxCompute平台帮助数据开发工程师高效并且低成本地执行自己的想法。
多功能。希望MaxCompute能够具有更多的功能,不仅仅是支持流计算、图计算、批处理和机器学习等,而希望更多种类的计算能够在MaxCompute平台上得到更好的支持。
MaxCompute的大脑——优化器
基于以上的研发思路,MaxCompute平台需要拥有一个更加强大的大脑,这个大脑需要更加理解用户的数据,更加理解用户的计算,并且更加理解用户本身,MaxCompute的大脑需要能够帮助用户更加高效地优化运算,通过系统层面去理解用户到底需要进行什么样的运算,从而达到之前提到的各种目的,使得用户能够从分布式场景中脱离出来,不必去考虑如何才能使得运算高效地执行,而将这部分工作交给MaxCompute的大脑,让它来为用户提供更智能的平台,这也就是MaxCompute所能够为用户带来的价值。

那么MaxCompute的大脑究竟是什么呢?其实就是优化器。优化器能够将所有信息串联在一起,通过理解系统中数据的相关性以及用户的企图,并通过机器的能力去充分地分析各种各样的环境,在分布式场景中以最高效的方式实现对于用户运算的执行。在本次分享中以离线计算作为主要例子来对于MaxCompute的大脑——优化器进行介绍。
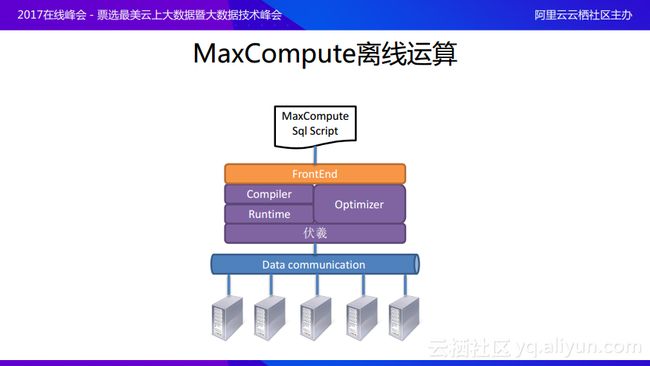
首先对于离线计算的概念进行简单介绍,MaxCompute离线计算架构设计如上图所示。在计算层面往往会存在一个类似高级语言的脚本语言,MaxCompute提供的是类SQL的脚本语言,将脚本语言通过FrontEnd提交进来,之后经过处理转化成为逻辑执行计划,逻辑执行计划在Optimizer(优化器)的指导下翻译成更加高效的物理执行计划,并通过与Runtime的连接之后由伏羲分布式调度系统将物理执行计划分解到运算节点上进行运算。
上述过程的核心就在于如何充分地理解用户的核心计划并通过优化得到高效的物理执行计划,这样的过程就叫做优化器Optimizer。目前开源社区内的Hive以及Spark的一些优化器基本上都是基于规则的优化器,其实对于优化器而言,单机系统上就存在这样的分类,分成了基于规则的优化器和基于代价的优化器。

在单机场景里面,Oracle 6-9i中使用的是基于规则的优化器,在Oracle 8开始有了基于代价的优化器,而Oracle 10g则完全取代了之前基于规则的优化器;而在大数据场景里面,像Hive最开始只有基于规则的优化器,而新版的Hive也开始引入了基于代价的优化器,但是Hive中还并不是正真意义上的代价优化器。而MaxCompute则使用了完全的基于代价的优化器。那么这两种优化器有什么区别呢?其实基于规则的优化器理论上会根据逻辑模式的识别进行规则的转换,也就是识别出一个模式就可能触发一个规则将执行计划从A改成B,但是这种方式对数据不敏感,并且优化是局部贪婪的,就像爬山的人只看眼前10米的范围内哪里是向上的,而不考虑应该先向下走才能走到更高的山顶,所以基于规则的优化器容易陷入局部优但是全局差的场景,容易受应用规则的顺序而生产迥异的执行计划,所以往往结果并不是最优的。而基于代价的优化器是通过Volcano火山模型,尝试各种可能等价的执行计划,然后根据数据的统计信息,计算这些等价执行计划的“代价”,最后从中选用代价Cost最低的执行计划,这样可以达到全局的最优性。
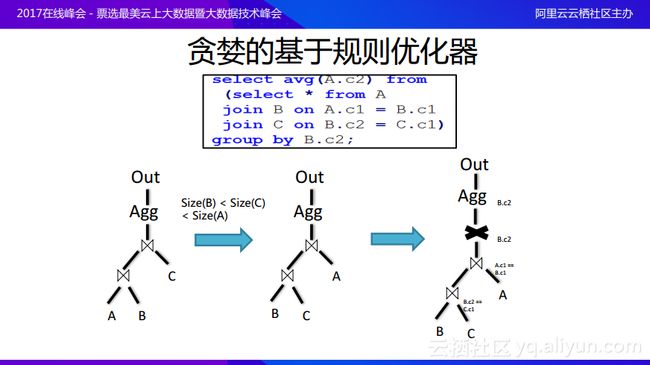
这里分享一个具体的例子帮助大家理解为什么基于规则的优化器无法实现全局的最优化。上图中的这段脚本的意思就是先在A、B和C上面做完join,join出来的结果在某一列上面进行group by操作并计算出平均值。可以将上述的查询过程画成树形的逻辑执行计划,在数据库领域往往是bottom-up的,也就是对于逻辑计划树而言,叶子节点是输入,最终的目标输出则是根节点,所以最终的数据流向是从下向上的。可以看到在这个逻辑计划里面,首先是对于A、B、C三个表进行join,假设Size(B)
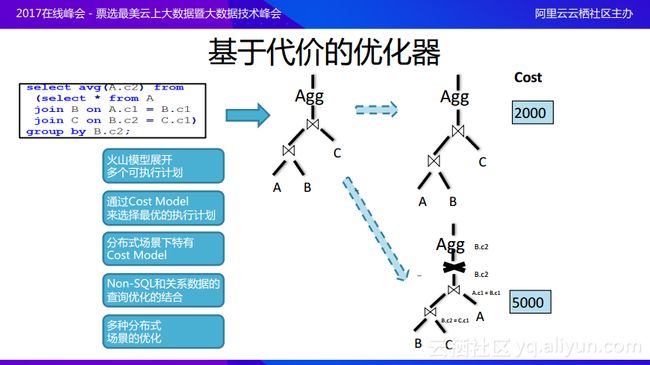
基于代价的优化器则采用了不同的方案,它首先通过火山模型将查询展开成为多个等价的可执行计划。例子中可以先让A和B join之后再join C或者先让B和C join之后再join A,在这两个计划中,因为下面的计划中多了一个exchange,而对于基于代价的优化器而言会在最后面有一个Cost代价模型,通过计算发现第一个计划在Cost上面更优,所以就会选择最优的计划进行执行。在基于代价的优化器中做了很多分布式场景之下特有的Cost模型,并且考虑到了Non-SQL,因为很多场景是与互联网有关的应用,用户需要很多Non-SQL的支持,所以可以通过用户自定义函数帮助用户实现一些Non-SQL与关系数据结合的查询优化,最后还有一些多种分布式场景的优化,这也是基于代价的优化器区别于单机优化器所做的一些工作。
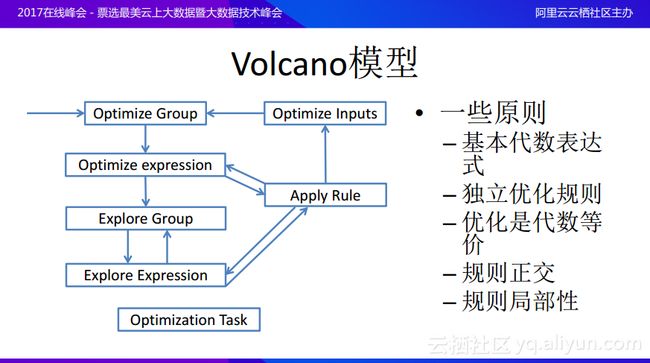
接下来分享一下Volcano火山模型的相关,其实Volcano模型是代价模型的一个引擎,这个引擎其实在单机系统上面就已经提出来了。Volcano模型里面也会有一些规则,但是与基于规则的优化器中的规则不同,这里面的规则更像是一些转化函数。Volcano模型首先会对于逻辑执行计划进行分组,之后在组上面要完成一件工作,就会先在组里面探索局部的表达式,然后根据一些规则应用一些变换,这些变换原则上都是代数等价的,在每次进行等价变化的时候其实并不是取代原来的逻辑执行计划树,而是在原本的基础之上分裂出新树。所以最后将会出现很多个等价的执行计划树,最终可以通过基于代价的优化器去选取最好的执行计划。Volcano模型的原则是首先希望每个规则更加局部性,也就是局部性和正交的规则越好,就越能够使得对于空间探索得更加全面。举个例子,如果在平面上定义了前后左右四个方向,那么就可以通过这四个方向搜索整个二维平面的任何一个点,同样的优化问题就是在空间里选取最好的计划,那么就希望在每一次变化时候的探索规则都能够正交,这样就可以用更少的规则去探索整个空间,这样如何去探索空间和选取探索最优路径就可以交给引擎了。
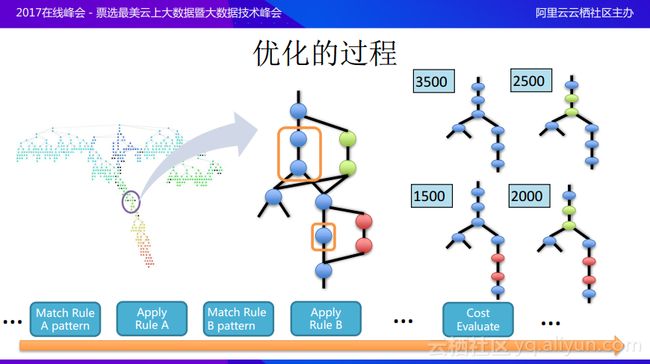
前面分享的比较抽象,这里进一步进行举例说明,希望能够加深大家对于优化过程的理解。假设有一个非常复杂的逻辑执行计划树,这就是真正需要做的用户的任务,现在将其中一小部分提取出来,在进行计划的优化时首先会分析有没有已有的规则可以与模式匹配,假设图中的两个节点正好能与模式匹配,一个是filter一个是project,理论上filter想要推到叶节点,也就是越早进行filter越好,现在就有一个模式:如果filter出现在project之上,也就是需要先做filter之后进行project,这样就可以转换成另一种计划,将这两个节点变成新的节点,也就是可以将filter和project换顺序,这样就是应用规则的过程。同样的还有另外一个节点,比如是aggregate操作能够与其他的模式匹配,之后就可以寻找对应的规则,并转化出等价的节点操作,这样就可以通过复用一棵树节点的模式来维护多棵树,在这里例子中可以看到使用了两个规则,看上去节点上是只是一个存储,但是实际上却描述了四棵等价树。之后会对于这四棵等价树花费的代价进行计算,最后选取花费代价最低的树作为执行计划。整体的基于代价的优化过程就是这样,但是可以看到当逻辑计划树规模很大并且规则变化有很多种的情况下,整个的探索空间还是非常庞大的,所以需要在很多因素上对于优化过程进行考虑。
接下来为大家介绍一下优化引擎的大致算法,下图是简化后的优化引擎算法,而在真正实施时还有很多需要考虑的因素下图中并没有表示出来。
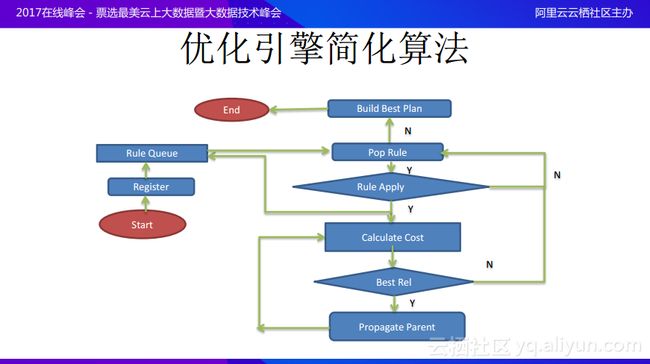
首先会将一个逻辑执行计划中的所有逻辑节点都注册进去,注册进去的同时就会将规则与已有的逻辑模式进行匹配,然后将匹配成功的规则推到规则队列里面,然后循环地弹出规则队列中的规则,并真正地应用这个规则。当然应用规则存在两种条件,一种就是应用之后能够产生等价树,也就是能够在树的局部分裂出另外一种树形状态,而在分裂出来的树上面也可能与其他的模式匹配,如果局部范围内的全部规则都已经匹配完成,就可以开始计算花费的代价。而当通过计算代价得出最佳方案之后,就可以放弃在该局部进行继续优化,如果认为当前的计划仍然不是最优的,就可以将该Cost记录下来,继续优化树的其他部分,直到最终找到最佳计划。
分布式查询中的优化问题实例
在这里给大家列举一些在分布式系统中有别与单机系统中分布式查询中的优化问题的实例。
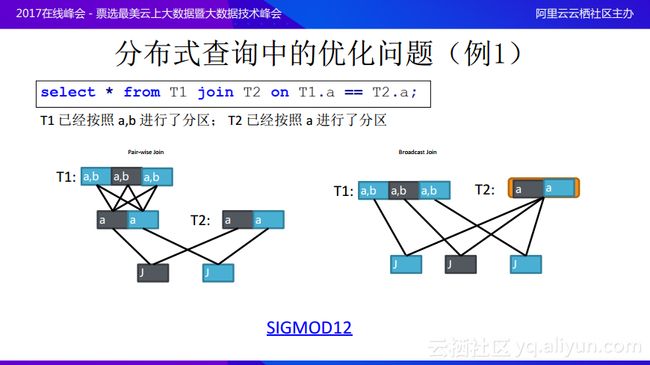
例1其实很简单,就是对于两个表进行join操作,T1已经按照a,b进行了分区;T2已经按照a进行了分区,join的条件就是T1.a=T2.a。一种方法因为T1是按照a和b分区好的,join条件在a上面,所以需要对于T1按照a重新进行分区之后再与T2进行join。但是如果T1表非常大,远远大于T2表的规模,这时候就不想将T1按照重新进行分区,反而可以采用另一种方案,就是将T2作为一个整体,将T2的所有数据广播给T1每一个数据,因为join条件是在a上面做内连接,所以可以做这样的选择,这样就可以避免将很大的数据进行reshuffle。在这个场景中,如何去感知join的条件是关键。上图例子中的两个计划并不存在绝对的最优,而是需要根据的数据的大小、T2数据量以及T1数据分片的分布情况来决定哪一种方案才是最优解,对于这个问题在SIFMOD12上面有很多的论文进行了讨论,在此就不再展开详细的叙述。
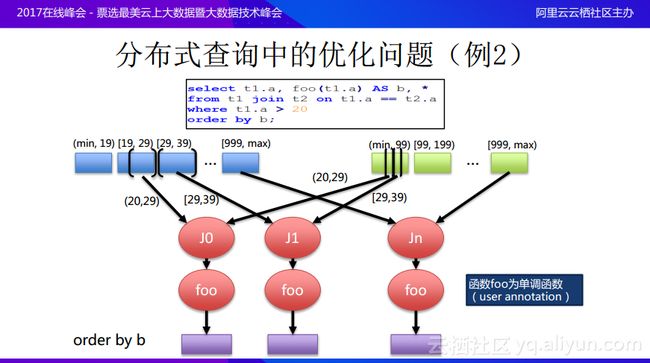
再分享分布式优化问题的里另外一个例子,如图所示,T1和T2还是在a上面进行join,join完成之后会有一个条件限制T1.a>20,完成之后会进行project,并将完成的结果当做新的一列b,最终希望所有的结果是order by b的。T1和T2都是range partition好了,这里不是hash partition,而且因为已经进行了global sort,所以这里在做join的时候就可以利用到两个表之间的range partition boundary,而不需要重新reshuffle数据,比如目前已经知道大于20会在哪些分区里面出现,可以根据选择的boundary去读取相应的数据之后进行作为,可以尽量避免数据shuffling,在做完join之后,还会有一个用户定义方法,将这个方法出来的结果按照order by b的规则进行排序,假设这个foo()方法是单调递增的函数,这样就可以利用上面的条件也就是已经按照范围分区好了,经过join和foo()还能保存b的顺序,就不用引入一个exchange,可以直接order by b操作。这样就是分布式中的一个查询优化,也就是如果能够理解数据里面的分片,能够知道数据的分布式情况还能理解用户的自定义函数方法,以及这些方法通过什么样的途径与优化器进行互动,就可以对于分布式查询进行优化。这其实是通过了用户的Annotation就可以知道用户的方法具有什么样的特性,能够保持什么样的数据属性。
用户自定义函数UDF
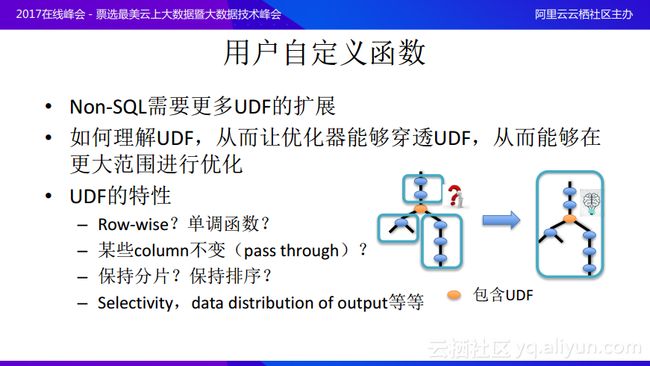
在分布式系统特别是Non-SQL中需要大量的用户定义函数来进行扩展,因为很多查询过程不是像join和aggregate这么简单的,而需要对于很多比较独特的功能进行建模,所以需要用户自定义的函数实现。一旦有了用户自定义的函数,优化器往往难以理解UDF,那么优化的范围将会极大地受到限制,如上图中的中间黄色的节点包含了用户自定义的函数,但是可能系统并不知道这个函数所做的事情,那么在优化的时候就可能分成三个更小的可优化片段,在在三个小片段中进行进一步优化。如果优化器能够理解用户自定义的函数在做什么事情,那么就可以让优化器穿透UDF达到更大范围的优化。那么UDF有什么特性能够帮助优化器穿透它呢?其实可以分析UDF是不是Row-wise操作的,考虑它是不是一行一行处理,不存在跨行的,考虑UDF是不是单调函数,是不是在处理时有些列是不变的,也就是可以穿透的,它是不是可以保持数据分片或者保持排序,以及在Cost上面的一些信息,它的Selectivity高还是低,以及data distribution of output是多还是少等等都能优化器更好地优化,为优化器打开更大的优化空间,实现更加灵活的优化,帮助Cost模型选出更优的方案。这也是阿里巴巴目前在MaxCompute优化器上正在做的一些工作。
优化规则
MaxCompute基于代价的优化器做了大量的优化,实现如下图所示的各种优化,这里就不展叙述开了。可以从下图中看到在查询中有很多优化可以去做,这些所有的优化在整个系统引擎上面都是一个个算子,这些算子也在变化图,产生了很多个等价的树,由优化的引擎通过Cost模型去选择最佳的方案。

Cost模型
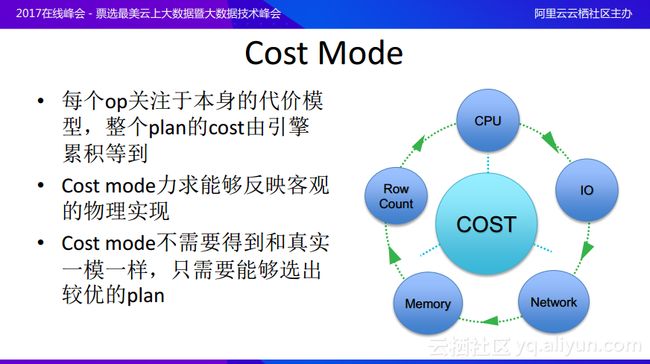
什么是Cost模型呢?其实Cost模型最需要关注的就是本身的代价模型。每个Cost模型都需要关注于局部,比如input是什么样的Cost,经过join之后又会得到什么样的Cost,而不需要关注于全局,全局方案的Cost则是由引擎通过累计得到的整体Cost。好的Cost模型力求能够反映客观的物理实现,Cost模型不需要得到和真实一模一样,Cost模型的最终目的是希望区别方案的优劣,只需要能够选出较优的计划,并不需要Cost的绝对值具有什么样的特性。现在传统的数据库的Cost模型还是很早以前的模型,就算硬件结构已经发生了变化,只要还是冯诺依曼体系结构,架构没有发生改变,Cost模型就可以用于选择最优的方案。
其实优化器还有很多其他方面的因素可以考虑,比如在规则方面,需要根据规则进行等价的变换,最后根据Cost模型选取最优的方案。随着逻辑计划规模的变大,如果枚举所有可能的方案就会极大地耗费时间,特别是在MaxCompute上希望逻辑执行计划越大越好,因为这样就能给优化引擎更大的空间,但是这就带来当枚举所有的计划时,有些枚举的计划其实是不必要的,可能已经处于在一个不优化的情况下了。所以如何去做有效的剪枝,如何去避免不必要的探索空间,也是实现一个好的优化器所需要考虑的。另外对探索空间的选择,可以将时间用在最有可能是最优化的计划的空间上面,这可能是一个比较好的选择,因为不能希望通过NP-hard的时间去选择最优的计划,而应该希望在有限的时间内选取比较好的执行计划,所以在优化领域中其实不一定需要寻找最佳的方案,而是要避免最差的方案,因为在优化上面总会存在时间约束。
为什么基于代价的优化器对于MaxCompute平台越来越重要了呢?

这是因为阿里巴巴希望能从Hive的一条条查询语句中走出来,提供更加复杂的存储过程。在上图中有一个展示,可以通过变量赋值以及预处理if-else编写出更加复杂的查询过程和存储过程,而基于规则的优化器会因为贪婪算法而越走越偏,最终很可能得不到全局最优方案,而逻辑计划的复杂化使得可以优化的空间变大了,但是同时也使得对于优化器的要求变得更高,所以需要更好的基于代价的优化器帮助选择比较好的执行计划。而在分布式以及Non-SQL等新型的场景下,使用基于代价的优化器有别于传统单机优化器的方式,所以需要有对于数据、运算和用户更加深刻的理解来使得基于代价的优化器更加智能。
理解数据

那么展开来看,什么叫做理解数据呢。在数据格式方面,理解数据需要对于更多的数据索引以及异构的数据类型进行理解,对于结构化的数据、非结构化的数据以及半结构化的数据都进行理解,而在大数据的场景里面数据是有一些Power-law属性的,有百万稀疏列的表格,需要在这样的场景下实现一个更好的优化;理解数据也需要理解丰富的数据分片方式,这是在分布式场景中才有的,数据分片可以是Range/Hash/DirectHash的,而存储可以是Columnstorage/Columngrouping的,还需要用Hierarchy Partition来进行分级分区;还会需要理解完善的数据统计信息和运行时数据,需要理解Histogram、Distinct value以及Data Volume等等。
理解运算

从理解运算方面,需要更加理解用户自定义的函数,能够与优化器进行互动,更够让用户通过Annotation的方式显示在运算中数据的属性上具有的特性,使得可以进行全局范围的优化。在运行时也会进行更多的优化,比如会在中间运行到一定阶段时需要判断数据量的大小,根据数据量的大小进行并行化的选择,并根据数据的位置选择网络拓扑上的优化策略。还可以做实时性,规模性,性能,成本,可靠性之间的平衡,并且使用网络Shuffling做内存计算以及流计算等。
理解用户

从理解用户的角度,需要理解在优化器上的用户场景,理解多租户场景下用户对规模,性能,延时以及成本不同需求等,并在这样的场景下让优化器选取最佳的方案;在生态上面,优化器是核心的优化引擎,希望能够在语言上面更多地开放,希望能与更多的语言和生态进行对接,也希望能够提供强大的IDE能来为开发者提供完整的开发体验;最后希望能够在统一的平台上提供多种运算的模式,使得优化器真正能够成为运算的大脑。
原文链接
阅读更多干货好文,请关注扫描以下二维码:
