前言:
有很多时候觉得自己很忙碌,其实都是自己拖拉造成的,让自己效率提升才是解决问题的关键性。
来吧,以后一切的种种。
目标:
既然已经学会了爬取网页的基本信息,就不能单纯的满足于几个网页的爬取。这次我们要更多更快更高效的完成任务。上次我们学习选择的是58同城,这次我们就选择和58同城相似的页面:赶集网。

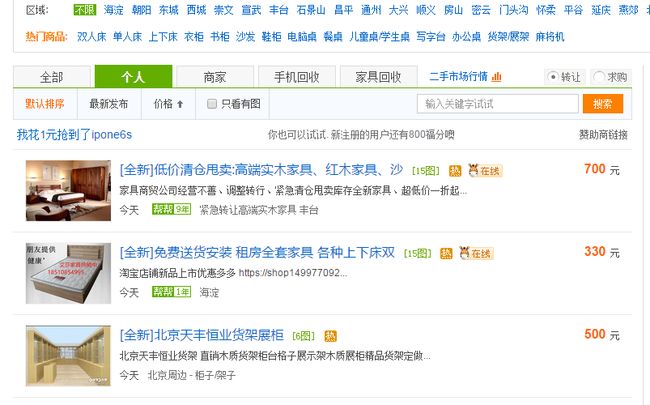
爬取每一个大标题里的内容信息。例如
由于上次没有模块化,以及因为数据量太小没有用到数据库,这次我们就选择mongodb来作为我们的数据库,mongodb 这个就是官网,找到绿色的download键,根据自己电脑版本选择下载包。win7的小伙伴们记得下载这个补丁包补丁点我 ,安装mongoddb完成后,就要进行配置。
(1):创建一个存放数据的地址,在cmd中输入 md c:\data\db
(2):启动mongodb,cmd中输入 c:\xxx\xxx\xxx\mongod.exe 这里的xxx是你的安装目录
(3):连接mongodd 不要关闭(2)的窗口,开启一个新的cmd,输入c:\xxx\xxx\xxx\mongo.exe,看到了welcome to mongodb shell就说明你已经启动成功啦!
(4):为了让mongodb开机自启动,我们要写一个简单的配置文件,在cmd中输入mkdir c:\data\log 关闭cmd,在文件夹下面建一个文件,命名为mongod.cfg,内容为:
systemLog:
destination: file
path: c:\data\log\mongod.log
storage:
dbpath: c:\data\db
保存,打开一个cmd 输入"c:\xxx\xxx\xxx\mongod.exe" --config "你cfg文件存放的位置" --install
结束后输入net start MongoDB 。到这里mongodb安装就完成了,接下来就在ide中对其进行配置:
(1):安装在pycharm中pymongo,第一篇文章有写第三方的安装这里就不多赘述。
(2):安装插件,在pycharm中setting
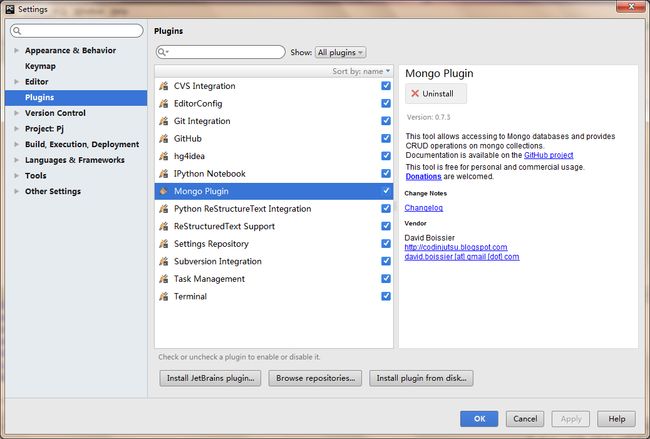
(3):
(4)配置
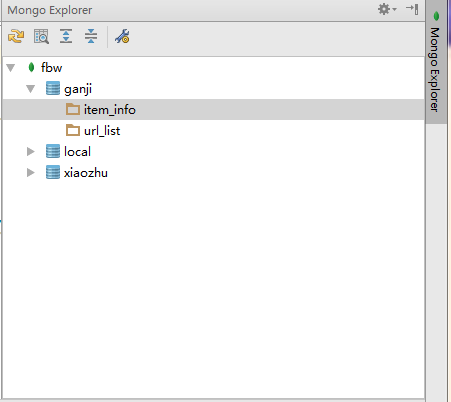
(5):
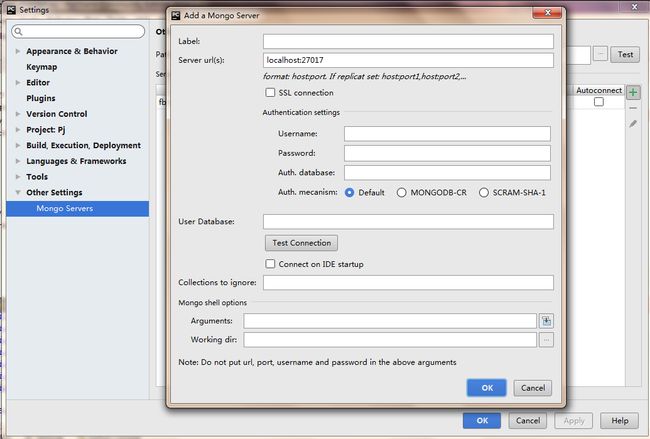
label里填一个自己起的名字,server url中如图所示,然后点ok。这时候我们就完成了整个的配置。
进入正题:
首先,选出提取出每一个频道的地址
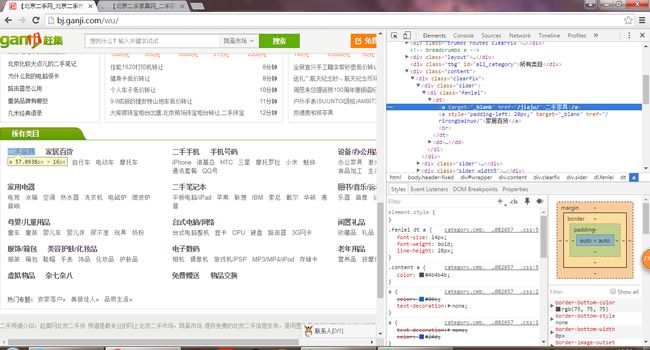
右键检查,观察后发现规律:
from bs4 import BeautifulSoup
import requests
main_url ='http://bj.ganji.com/wu/'
web_data = requests.get(main_url)
web_data.encoding ='utf-8'
soup = BeautifulSoup(web_data.text,'lxml')
url = soup.select('dl > dt > a') 在dl标签下的dt标签里的a标签中
绕口令
这样我们就能把url都提取出来,这里,我为了以后使用方便,把提取出来的url放在一个list中,命名为urls。
既然有了数据库,我们就可以分成两个爬虫来写,一个提取页面中商品的url信息。另一个函数爬取具体信息。所以建立两个数据表:
client = pymongo.MongoClient('localhost',27017)
ganji = client['ganji']
url_list = ganji['url_list'] 存放url
item_info = ganji['item_info'] 存放具体信息
为了让每个模块的功能清晰可见。我们分为几个部分来写
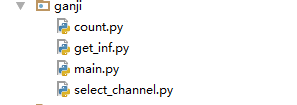
urls存在select—channel中
获取网址和获取信息存放在get_inf中
为了防止大量爬取的时候被58封ip,自定义一下header以及ip地址
headers = {
xxxx 这里请小伙伴们自己填写
}
proxy_list = [
'http://xxxxx', ip地址也同样
'http://xxxxx',
'http://xxxxx',
]
proxy_ip = random.choice(proxy_list) 随机选择ip
proxies = {'http': proxy_ip}
首先先完成提取url的工作
def get_url(channel, page): 定义两个参数,第一个为select_channel中的url,第二个为提取第几页
main_url = channel +'o{}'.format(page) 观察网页如http://bj.ganji.com/jiaju/o6/,可以知道网页的构成模式为channel和页数相拼接而成
web_data = requests.get(main_url)
time.sleep(1) 休眠一秒钟,防止速率过快
soup = BeautifulSoup(web_data.text,'lxml')
url = soup.select(' div > ul > li.js-item > a') 选出每个商品的链接
if soup.find('div','pageBox'): 这里如果页面太过于往后,就会只显示广告,为了不选择广告。观察发现,只有正常的页面里才有翻页这个功能,而广告页没有,所以选出带有"page_box"的网页
for link in url:
link = link.get('href')
urls = {
'url': link
}
url_list.insert_one(urls) 通过for循环把网页地址存入数据库中
else:
pass
完成了对网页的筛选以后,我们来写第二个爬虫。来进行对具体信息的爬取:
def get_inf(url):str =""
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text,'lxml')
if soup.find('div','error'): 网页如果出现404,跳出
pass
elif soup.find('p','error-tips1'): 网页若果出现物品不存在的错误,跳出
pass
else:
print(url) 调试用的
times = soup.select('i.pr-5') 检查网页得到的
leixing = soup.select('ul.det-infor > li:nth-of-type(1) > span > a') 同上
places = soup.select('div > ul.det-infor > li:nth-of-type(3) > a') 同上
money = soup.select('div.leftBox > div:nth-of-type(3) > div > ul > li:nth-of-type(2) > i') 同上
xinjius = soup.select('div > div:nth-of-type(1) > ul.second-det-infor.clearfix > li')
for place in places: 处理地点的字符串
str = str + place.text +''
if(xinjius): 对新旧程度的处理
xinjius = xinjius[0].text.split('(')[0].replace('\n','').replace(' ','').split(':')[-1]
else:
pass
if(times): 对时间的处理
times = times[0].text.replace(' ','').replace('\n','').replace('\xa0','').split('发')[0]
else:
pass
if(leixing): 对类型的处理
leixing = leixing[0].text
else:
pass
if(money): 对价格的处理
money =int(money[0].text)
else:
money ='未填写'
data = {
'标题': soup.title.text.strip(),
'时间': times,
'类型': leixing,
'位置': str,
'价格': money,
'新旧': xinjius
}
item_info.insert_one(data) 写入数据库
这样就完成了对具体信息的爬取。
下一步我们写一个main函数,来进行调度
from ganji.select_channel import * 引用包
from ganji.get_inf import *
from multiprocessing import Pool 引用多进程
def all_links(channel):
for href in channel:
for i in range(1,11): 获取前十页的信息,如果获取100页即为range(1,,101)
get_url(href,i) 调用第一个爬取网址的爬虫
def start_get (link):
pool = Pool()
pool.map(get_inf, link) 使用多线程并调用第二个爬取信息的爬虫
if__name__ =='__main__': 主函数
all_links(urls) 调用上文定义的函数
link = [] 设定一个list存放从网址
for hrefs in url_list.find():
canshu = hrefs['url']
link.append(canshu) 把网址存入list中
start_get(link) 调用上文函数
最后的最后,我们要写一个计数程序来检测已经爬取了多少数据
import time
from ganji.get_inf importurl_list
from ganji.get_inf import item_info
while True: 死循环
print("网址")
print(url_list.find().count()) 输出网址数
print("数据")
print(item_info.count()) 输出数据数
time.sleep(5)
这样我们的程序就基本完成了,我们来看看结果:

题后记:
做中学,私以为是一种学习编程的最好的办法了。这次的程序的缺点,我认为有以下几点:
(1)参数命名问题。
(2)一万多条网址只爬取了四千多条信息,pass语句使用太多,应该更好的处理信息。
(3)爬取数量应该更多一些。应做到十万条的测试