欢迎关注我的微信公众号:FunnyBigData
在《Spark 内存管理的前世今生(上)》中,我们介绍了 UnifiedMemoryManager 是如何管理内存的。然而,UnifiedMemoryManager 是 MemoryManager 而不是 MemoryAllocator 或 MemoryConsumer,不进行实质上的内存分配和使用,只是负责可以分配多少 storage 或 execution 内存给谁,记录各种元数据信息。
这篇文章会关注 storage 的堆内堆外内存到底是在什么样的情况下,以什么样的形式分配以及是怎么使用的。
缓存 RDD 是 storage 内存最核心的用途,那我们就来看看缓存 RDD 的 partition 是怎样分配、使用 storage 内存的。
可以以非序列化或序列化的形式缓存 RDD,两种情况有所不同,我们先来看看非序列化形式的。
1: 缓存非序列化 RDD(只支持 ON_HEAP)
缓存非序列化 RDD 通过调用
MemoryStore#putIteratorAsValues[T](blockId: BlockId,
values: Iterator[T],
classTag: ClassTag[T]): Either[PartiallyUnrolledIterator[T], Long]
来缓存一个个 partition 。该函数缓存一个 partition(一个 partition 对应一个 block) 数据至 storage 内存。其中:
- blockId:缓存到内存后的 block 的 blockId
- values:对象类型的迭代器,对应一个 partition 的数据
整个流程还可以细化为以下两个子流程:
- unroll block:展开迭代器
- store unrolled to storage memory:将展开后的数据存入 storage 内存
1-1: unroll block
一图胜千言,我们先来看看 unroll 的流程
我们先对上图中的流程做进一步的说明,然后再简洁的描述下整个过程以加深印象
1-1-1: 为什么申请初始 unroll 内存不成功还继续往下走?
初始的用于 unroll 的内存大小由 spark.storage.unrollMemoryThreshold 控制,默认为 1M。继续往下走主要由两个原因:
- 由于初始 unroll 大小是可以设置的,如果不小心设置了过大,比如 1G,这时申请这么大的 storage 内存很可能失败,但 block 的真正大小可能远远小于该值;即使该值设置的比较合理,block 也很可能比初始 unroll 大小要小
- 对于
MemoryStore#putIteratorAsValues,即使 block 大小比初始 unroll 大小要大,甚至最终都没能完整的把 values unroll 也是有用的,这个将在后文展开,这里先请关注返回值new PartiallyUnrolledIterator(...)
1-1-2: 关于 vector: SizeTrackingVector
如流程图中所示,在 partition 对应的 iterator 不断被展开的过程中,每展开获取一个记录,就加到 vector 中,该 vector 为 SizeTrackingVector 类型,是一个只能追加的 buffer(内部通过数组实现),并持续记录自身的估算大小。从这里也可以看出,unroll 过程使用的内存都是 ON_HEAP 的。
整个展开过程,说白了就是尽量把更多的 records 塞到这个 vector 中。因为所有展开的 records 都存入了 vector 中,所以从图中可以看出,每当在计算 vector 的估算 size 后,就会与累计已申请的 unroll 内存大小进行比较,如果 vector 的估算 size 更大,说明申请的 unroll 内存不够,就会触发申请更多的 unroll 内存(具体是申请 vector 估算大小的 1.5 倍减去已申请的 unroll 总内存),这:
- 一是为了接下去的展开操作申请 unroll 内存
- 二也是为了尽量保障向 MemoryManager 申请的 unroll 内存能稍大于真实消耗的 unroll 内存,以避免 OOM(若向 MemoryManager 申请的 unroll 内存小于真实使用的,那么就会导致 MemoryManager 认为有比真实情况下更多的空闲内存,如果使用了这部分不存在的空闲内存就会 OOM)
如图所示,要符合一定的条件才 check unroll memory 是否够用,也就是 vector 计算其估算大小并判断是否大于已申请的 unroll memory size。这里是每展开 16 条记录进行一次检查,设置这样的间隔是因为每次估算都需要耗费数毫秒。
1-1-3: 继续还是停止 unroll ?
每展开一条记录后,都会判断是否还需要、还能够继续展开,当 values 还有未展开的 record 且还有 unroll 内存来展开时就会继续展开,将 record 追加到 vector 中。
需要注意的是,只有当 keepUnrolling 为 true 时(不管 values.hasNext 是否为 true)才会进入 store unrolled to storage memory 流程。这样的逻辑其实有些问题,我们先来看看其实现代码:
while (values.hasNext && keepUnrolling) {
vector += values.next()
if (elementsUnrolled % 16 == 0) {
// currentSize 为 vector 的估算大小
val currentSize = vector.estimateSize()
if (currentSize >= memoryThreshold) {
// 申请 size 为 amountToRequest 的估算大小,memoryGrowthFactor 为 1.5
val amountToRequest = (currentSize * memoryGrowthFactor - memoryThreshold).toLong
keepUnrolling = reserveUnrollMemoryForThisTask(blockId, amountToRequest, MemoryMode.ON_HEAP)
}
memoryThreshold += amountToRequest
}
}
elementsUnrolled += 1
}
if (keepUnrolling) {
// store unrolled to storage memory
}
此时,假设 keepUnrolling 为 true, values.hasNext 为 true,也就是还有一些记录没有展开(在假设剩余未展开的 records 总大小为 1M),进入循环后,展开一条记录追加到 vector 中后,恰好 elementsUnrolled % 16 == 0 且 currentSize >= memoryThreshold。根据 val amountToRequest = (currentSize * memoryGrowthFactor - memoryThreshold).toLong 计算出要为了展开剩余 records 本次要申请的 unroll 内存大小为 amountToRequest,大小为 5M,这时候实际上最大能申请的 unroll 内存大小为 3M,那么申请就失败了,keepUnrolling 为 false,此时进入下一次循环判断就失败了,整个展开过程也就失败了,但事实上剩余能申请的 unroll 内存大小是足以满足剩余的 records 的。
一个简单的治标不治本的改进方案是将 memoryGrowthFactor 的值设置的更小(当前为 1.5),该值越小发生上述情况的概率越小,并且,这里的申请内存其实只是做一些数值上的状态更新,并不会发生耗资源或耗时的操作,所以多申请几次并不会带来什么性能下降。
回到当前的实现中来,当循环结束,若 keepUnrolling 为 true ,values 一定被全部展开;若 keepUnrolling 为 false(存在展开最后一条 record 后 check 出 vector 估算 size 大于已申请 unroll 总内存并申请失败的情况),则无论 values 有没有被全部展开,都说明能申请到的总 unroll 内存是不足以展开整个 values 的,这就意味着缓存该 partition 至内存失败。
需要注意的是,缓存到内存失败并不代表整个缓存动作是失败的,根据 StorageLevel 还可能会缓存到磁盘。
1-2: store unrolled to storage memory
1-2-1: 真正的 block 即 DeserializedMemoryEntry
这一流程说白了就是将 unroll 的总内存占用转化为 storage 的内存占用,事实上真正保存 records 的 vector 中的数组也被移到了 entry 中(引用传递)。entry 是这样被构造的:
private case class DeserializedMemoryEntry[T](
value: Array[T],
size: Long,
classTag: ClassTag[T]) extends MemoryEntry[T] {
val memoryMode: MemoryMode = MemoryMode.ON_HEAP
}
val arrayValues = vector.toArray
vector = null
val entry = new DeserializedMemoryEntry[T](arrayValues, SizeEstimator.estimate(arrayValues), classTag)
entry 的成员 value 为 vector 中保存 records 的数组,entry 的 size 成员为该数组的估算大小。DeserializedMemoryEntry 继承于 MemoryEntry,MemoryEntry 的另一个子类是 SerializedMemoryEntry,对应的是一个序列化的 block。在 MemoryStore 中,以 entries: LinkedHashMap[BlockId, MemoryEntry[_]] 的形式维护 blockId 及序列化或非序列化的 block 的映射。
从这里,你也可以看出,当前缓存非序列化的 RDD 只能使用 ON_HEAP 内存。
1-2-2: unroll 内存的多退少补
这之后,再次使用 array[record] 的估算大小与 unroll 总内存进行比较:
- 若前者较大,则计算要再申请多少 unroll 内存(两者之差)并申请之,申请的结果为 acquireExtra
- 若后者较大,则说明申请了在 unroll 过程中申请了过多的内存,则释放多出来的部分(两者之差)。会出现多出来的情况有两点原因:
- 这次 array[record] 的估算结果更为准确
- 在 unroll 过程中由于每次申请的内存是
val amountToRequest = (currentSize * memoryGrowthFactor - memoryThreshold).toLong,这样的算法是容易导致申请多余实际需要的
1-2-3: transform unroll to storage
将 unroll 内存占用转为 storage 内存占用实现如下:
def transferUnrollToStorage(amount: Long): Unit = {
// Synchronize so that transfer is atomic
memoryManager.synchronized {
releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP, amount)
val success = memoryManager.acquireStorageMemory(blockId, amount, MemoryMode.ON_HEAP)
assert(success, "transferring unroll memory to storage memory failed")
}
}
可以看到,这是一个 memoryManager 级别的同步操作,不用担心刚被 release 的 unroll 内存在占用等量的 storage 内存之前会在其他地方被占用。
在 UnifiedMemoryManager 的内存划分中,unroll 内存其实就是 storage 内存,所以上面代码所做的事看起来没什么意义,先让 storage used memory 减去某个值,再加上该值,结果是没变。那为什么还要这么做呢?我想是为了 MemoryStore 和 MemoryManager 的解耦,对于 MemoryStore 来说其并不知道在 MemoryManager 中 unroll 内存就是 storage 内存,如果之后 MemoryManager 不是这样实现了,对 MemoryStore 也不会有影响。
1-2-4: enoughStorageMemory 及结果
在这一流程的最后,会根据 enoughStorageMemory 为 true 后 false,返回不同的结果。只有当以上流程中,partition 被完全展开并成功存放到 storage 内存中 enoughStorageMemory 才为 true;即使partition 全部展开,并生成了 entry,如果最终能申请的最多的 storage 内存还是小于 array[record] 的估算 size,整个 cache block to memory 的操作也是失败的,此时的 enoughStorageMemory 为 false。
如果最终结果是成功的,返回值为 array[record] 的估算 size。如果是失败的,包括 unroll 失败,将返回 PartiallyUnrolledIterator 对象实例:
class PartiallyUnrolledIterator[T](
memoryStore: MemoryStore,
memoryMode: MemoryMode,
unrollMemory: Long,
private[this] var unrolled: Iterator[T],
rest: Iterator[T])
extends Iterator[T]
该实例(也是个迭代器)由部分已经展开的迭代器(unrolled)以及剩余未展开的迭代器(rest)组合而成,调用者可根据 StorageLevel 是否还包含 Disk 级别来决定是 close 还是使用该返回值将 block 持久化到磁盘(可以避免部分的 unroll 操作)。
2: 缓存序列化 RDD(支持 ON_HEAP 和 OFF_HEAP)
有了上面分析缓存非序列化 RDD 至内存的经验,再来看下面的缓存序列化 RDD 至内存的图会发现有一些相似,也有一些不同。在下面的流程图中,包含了 unroll 过程和 store block to storage memory 过程。为了方便分析,我将整个流程分为三大块:
- 红框部分:初始化 allocator、bbos、serializationStream
- 灰框部分:展开 values 并 append 到 serializationStream 中
- 篮框部分:store block to storage memory
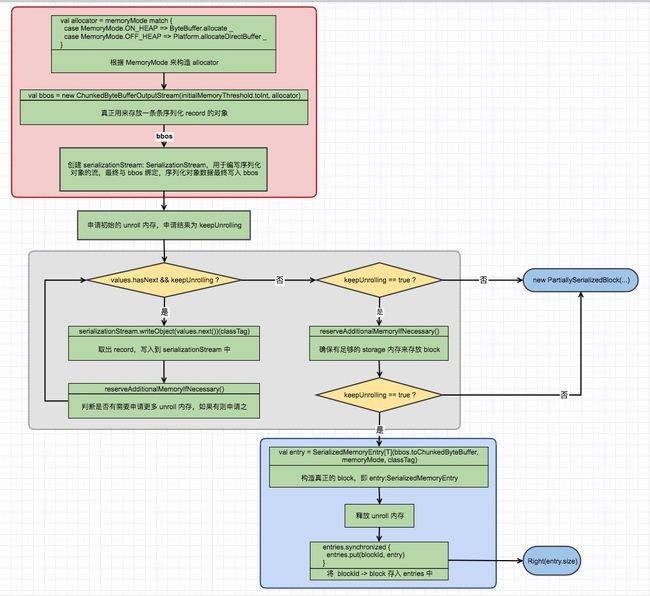
2-1: 初始化 allocator、bbos、serializationStream
allocator: Int => ByteBuffer 是一个函数变量,用来分配内存,它是这样被构造的:
val allocator = memoryMode match {
case MemoryMode.ON_HEAP => ByteBuffer.allocate _
case MemoryMode.OFF_HEAP => Platform.allocateDirectBuffer _
}
- 当 MemoryMode 为 ON_HAP 时,allocator 分配的是 HeapByteBuffer 形式的堆上内存
- 当 MemoryMode 为 OFF_HEAP 时,allocator 分配的是 DirectByteBuffer 形式的堆外内存。需要特别注意的是,DirectByteBuffer 本身是堆内的对象,这里的堆外是指其指向的内存是堆外的
HeapByteBuffer 通过调用 new 分配内存,而 DirectByteBuffer 最终调用 C++ 的 malloc 方法分配,在分配和销毁上 HeapByteBuffer 要比 DirectByteBuffer 稍快。但在网络读写和文件读写方面,DirectByteBuffer 比 HeapByteBuffer 更快(具体原因请自行调研,不是本文重点),这对经常会被网络读写的 block 来说很有意义。
另外,HeapByteBuffer 指向的内存受 GC 管理;而 DirectByteBuffer 指向的内存不受 GC 管理,可减小 GC 压力。DirectByteBuffer 指向的内存会在两种情况下会释放:
- remove 某个 block 时,会通过 DirectByteBuffer 的 cleaner 来释放其指向的内存
- 当 BlockManager stop 时,会 clear 整个 MemoryStore 中的所有 blocks,这时会释放所有的 DirectByteBuffers 及其指向的内存
接下来是:
val bbos = new ChunkedByteBufferOutputStream(initialMemoryThreshold.toInt, allocator)
ChunkedByteBufferOutputStream 包含一个 chunks: ArrayBuffer[ByteBuffer],该数组中的 ByteBuffer 通过 allocator 创建,用于真正存储 unrolled 数据。再次说明,如果是 ON_HEAP,这里的 ByteBuffer 是 HeapByteBuffer;而如果是 OFF_HEAP,这里的 ByteBuffer 则是 DirectByteBuffer。
bbos 之后将用于建构构造 serializeStream: SerializationStream,records 将一条条写入 serializeStream,serializeStream 最终会将 records 写入 bbos 的 chunks: ArrayBuffer[ByteBuffer] 中,一条 record 对应 ByteBuffer 元素。
2-2: 展开 values 并 append 到 serializationStream 中
具体展开的流程与 “缓存非序列化 RDD” 类似(serializationStream.writeObject(values.next())(classTag) 也在上一小节进行了说明),最大的区别是在没展开一条 record 都会调用 reserveAdditionalMemoryIfNecessary(),实现如下
def reserveAdditionalMemoryIfNecessary(): Unit = {
if (bbos.size > unrollMemoryUsedByThisBlock) {
val amountToRequest = bbos.size - unrollMemoryUsedByThisBlock
keepUnrolling = reserveUnrollMemoryForThisTask(blockId, amountToRequest, memoryMode)
if (keepUnrolling) {
unrollMemoryUsedByThisBlock += amountToRequest
}
}
}
由于是序列化的数据,这里的 bbos.size 是准确值而不是估算值。reserveAdditionalMemoryIfNecessary 说白了就是计算真实已经占用的 unroll 内存(bbos.size)比已经申请的 unrolll 总内存 size 大多少,并申请相应 MemoryMode 的 unroll 内存来使得申请的 unroll 总大小和实际使用的保持一致。如果申请失败,则 keepUnrolling 为 false,那么缓存该非序列化 block 至内存就失败了,将返回 PartiallySerializedBlock 类型对象。
在完整展开后,会再调用一次 reserveAdditionalMemoryIfNecessary,以最终确保实际申请的 unroll 内存和实际占用的大小相同。
2-3: store block to storage memory
这里将 bbos 中的 ArrayBuffer[ByteBuffer] 转化为 ChunkedByteBuffer 对象,ChunkedByteBuffer 是只读的物理上是以多块内存组成(即 Array[ByteBuffer])。
再以该 ChunkedByteBuffer 对象构造真正的序列化的 block,即 entry: SerializedMemoryEntry,构造时同样会传入 MemoryMode。
最后将 entry 加到 entries: LinkedHashMap[BlockId, MemoryEntry[_]] 中。
与 “缓存非序列化 RDD” 相同,如果缓存序列化 block 至内存失败了,根据 StorageLevel 还有机会缓存到磁盘上。
总结
上篇文章主要讲解 MemoryManager 是怎样管理内存的,即如何划分内存区域、分配踢除策略、借用策略等,并不涉及真正的内存分配,只做数值上的管理,是处于中心的storage 内存调度 “调度”。而本文则分析了在最重要的缓存非序列化/序列化 RDD 至内存的场景下,storage 内存真正是如何分配使用的,即以什么样的 MemoryMode、什么样的分配逻辑及方式,还介绍了 block 在 memory 中的表现形式等。
关注公众号回复:内存管理上
查看 Spark 是如何详细划分内存以及内存的分配策略
