本文首发于微信公众号《与有三学AI》
[caffe解读] caffe从数学公式到代码实现3-shape相关类
接着上一篇说,本篇开始读layers下面的一些与blob shape有关的layer,比如flatten_layer.cpp等,具体包括的在下面;
flatten_layer.cpp
slice_layer.cpp
split_layer.cpp
tile_layer.cpp
concat_layer.cpp
reduction_layer.cpp
eltwise_layer.cpp
crop_layer.cpp
pooling_layer.cpp
scale_layer.cpp
conv与deconv虽然也与shape有关,但是由于比较复杂,我们以后专门留一篇来说。下面这些层,如果你没有仔细读过源码,那么建议你来读一读,因为有很多并没有想象中那么简单。
1 flatten_layer.cpp
Flatten layer的作用是把一个维度为n * c * h * w的输入转化为一个维度为 n* (c*h*w)的向量输出,虽然在我们看来不一样,但是在blob看来,输入和输出的数据存储是没有差异的,只是记录的shape信息不同。所以forward和backward只是数据拷贝
template
void FlattenLayer
const vector
}
template
void FlattenLayer
const vector
bottom[0]->ShareDiff(*top[0]);
}
2 slice_layer.cpp
Slice layer 的作用是将bottom按照需要分解成多个tops,它的定义如下:
message SliceParameter {
// By default, SliceLayer
concatenates blobs along the "channels" axis (1).
optional int32 axis = 3 [default = 1];
repeated uint32 slice_point = 2;
// DEPRECATED: alias for "axis" -- does not support negative indexing.
optional uint32 slice_dim = 1 [default = 1];
}
默认axis是1,也就是blob的第1个维度,即channel通道,这也是我经常使用的,一般用于有多种label时分离label。
前向反向时小心计算好offset就行,有兴趣可以去看。
3 split_layer.cpp
它的作用是将输入复制多份。
Forward: 在前向的时候,top[i]=bottom[0],直接赋值。
template
void SplitLayer
const vector
for (int i = 0; i < top.size(); ++i) {
top[i]->ShareData(*bottom[0]);
}
}
Backward: 在反向的时候,需要将所有top的diff叠加起来。
template
void SplitLayer
const vector
if (!propagate_down[0]) { return; }
if (top.size() == 1) { caffe_copy(count_, top[0]->cpu_diff(), bottom[0]->mutable_cpu_diff());
return;
}
caffe_add(count_, top[0]->cpu_diff(), top[1]->cpu_diff(),
bottom[0]->mutable_cpu_diff());
// Add remaining top blob diffs.
for (int i = 2; i < top.size(); ++i) {
const Dtype* top_diff = top[i]->cpu_diff();
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
caffe_axpy(count_, Dtype(1.), top_diff, bottom_diff);
}
}
4 tile_layer.cpp
数学定义:
将数据按照某个维度扩大n倍,看下面forward源码,将bottom_data的前inner_dim_个数据复制了tiles份,反向时将对应diff累加回去即可。
Forward,backward与split layer很像。
void TileLayer
const vector
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
for (int i = 0; i < outer_dim_; ++i) {
for (int t = 0; t < tiles_; ++t) {
caffe_copy(inner_dim_, bottom_data, top_data);
top_data += inner_dim_;
}
bottom_data += inner_dim_;
}
}
5 concat_layer.cpp
与slice_layer是反向操作,将多个bottom blob合并成一个top_data,forward,backward计算好index就行。
6 reduction_layer.cpp
顾名思义,这是一个降维的层。
数学定义:
message ReductionParameter {
enum ReductionOp {
SUM = 1;
ASUM = 2;
SUMSQ = 3;
MEAN = 4;
}
optional ReductionOp operation = 1 [default = SUM]; // reduction operation The first axis to reduce to a scalar -- may be negative to index from the end (e.g., -1 for the last axis). (Currently, only reduction along ALL "tail" axes is supported;
reduction of axis M through N, where N < num_axes - 1, is unsupported.)
Suppose we have an n-axis bottom Blob with shape:
(d0, d1, d2, ..., d(m-1), dm, d(m+1), ..., d(n-1)).
If axis == m, the output Blob will have shape (d0, d1, d2, ..., d(m-1)),
and the ReductionOp operation is performed (d0 * d1 * d2 * ... * d(m-1))
times, each including (dm * d(m+1) * ... * d(n-1)) individual data.
If axis == 0 (the default), the output Blob always has the empty shape
(count 1), performing reduction across the entire input often useful for creating new loss functions.
optional int32 axis = 2 [default = 0];
optional float coeff = 3 [default = 1.0]; // coefficient for output
}
从上面可以看出,reduct有4类操作,sum,mean,asum,sumsq,分别是求和,求绝对值和,求平方和与平均。它会从axis这个维度开始去降维,比如当axis=0,就是从0开始将所有blob降维,最终会得到一个标量数,常用于loss。
在reshape函数中可以看到,
axis_ = bottom[0]->CanonicalAxisIndex(this->layer_param_.reduction_param().axis());
vector top_shape(bottom[0]->shape().begin(), bottom[0]->shape().begin() + axis_);
top[0]->Reshape(top_shape);
num_ = bottom[0]->count(0, axis_);
dim_ = bottom[0]->count(axis_);
CHECK_EQ(num_, top[0]->count());
通过reduction_param().axis())设置维度之后,top[0]的元素数目就是num_ =bottom[0]->count(0, axis_);我们假设输入blob是10*3*224*224,如果axis=0,那么top[0]=10*1*1*1;如果axis=1,那么top[0]=10*3*1*1,以此类推。
Forward和Backward对应这4个操作去看代码即可,只要知道反向的时候,top的每一个元素的梯度会反传给bottom的多个元素。
7 eltwise_layer.cpp
eltwise是一个有多个bottom输入,一个top输出的layer,对逐个的元素进行操作,所bottom[i]和top[j]的大小都是相等的。Eltwise参数有相乘PROB,相加SUM,求MAX。对于SUM操作,该层定义了 coeff 参数,用于调整权重。 对于PROB操作,设定了stable_prod_grad #[default = true ] 来选择是否渐进较慢的梯度计算方法,forward过程不需要说太多,而对于backward,有必要说一下。下面举prob操作的例子;

我们看相应函数,这只是内循环,实际上还有外循环。
case EltwiseParameter_EltwiseOp_PROD:
if (stable_prod_grad_) { bool initialized = false;
for (int j = 0; j < bottom.size(); ++j) {
if (i == j) { continue; }
if (!initialized) {
caffe_copy(count, bottom[j]->cpu_data(), bottom_diff);
initialized = true;
} else {
caffe_mul(count, bottom[j]->cpu_data(), bottom_diff,
bottom_diff);
}
}
} else {
caffe_div(count, top_data, bottom_data, bottom_diff);
}
caffe_mul(count, bottom_diff, top_diff, bottom_diff);
当stable_prod_grad = false时,直接对应了上面的式 top_data/bottom_data*bottom_diff,但是如果stable_prod_grad = true,差异在哪呢?反正我是没看出啥区别,只是为true时没有利用已经计算号的结果,计算更慢了。
8 crop_layer.cpp
crop layer改变blob的第2,3个维度,而不是改变前两个维度,也没有复杂的数学操作,所以只需要记录下offset即可,感兴趣还是去看源码。
9 pooling_layer.cpp
pooling layer想必大家都很熟悉了,caffe官方的有MAX,MEAN两种,还保留了一种random的没有实现。 Max和Mean的区别会在什么地方呢?主要就是max会存在一个mask,因为它要记录对top有贡献的那个元素,在梯度反传的时候,也只会反传到1个元素,而mean则会反传到r*r个元素,r就是滤波的半径。
其他的倒是没有需要特别注意的地方,主要就是bottom到top到index到计算,细节处小心即可。
10 bnll_layer.cpp
数学定义:
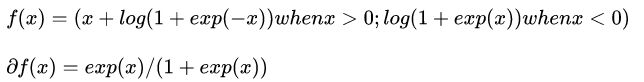
就这么多。
11 scale_layer.cpp
scale这个layer绝对比你想象中复杂多。我们通常以为是这样就完了
其中a是一个标量,x是一个矢量,在caffe中就是blob,但是实际上a也可以是blob,它可以有如下尺寸,见scale参数的定义:
message ScaleParameter {
// The first axis of bottom[0] (the first input Blob) along which to apply, bottom[1] (the second input Blob). May be negative to index from the end (e.g., -1 for the last
axis).
// For example, if bottom[0] is 4D with shape 100x3x40x60, the output top[0] will have the same shape, and bottom[1] may have any of the following shapes (for the given value of axis):
(axis == 0 == -4) 100; 100x3; 100x3x40; 100x3x40x60
(axis == 1 == -3) 3; 3x40; 3x40x60
(axis == 2 == -2) 40; 40x60
(axis == 3 == -1) 60
// Furthermore, bottom[1] may have the empty shape (regardless of the value of "axis") a scalar multiplier.
optional int32 axis = 1 [default = 1];
// (num_axes is ignored unless just one bottom is given and the scale is a learned parameter of the layer. Otherwise, num_axes is determined by the number of axes by the second bottom.)
// The number of axes of the input (bottom[0]) covered by the scale
// parameter, or -1 to cover all axes of bottom[0] starting from `axis`.
// Set num_axes := 0, to
multiply with a zero-axis Blob: a scalar.
optional int32 num_axes = 2 [default = 1];
// (filler is ignored unless just one bottom is given and the scale is
// a learned parameter of the layer.)
// The initialization for the learned scale parameter.
// Default is the unit (1) initialization, resulting in the ScaleLayer
// initially performing the identity operation.
optional FillerParameter filler = 3;
// Whether to also learn a bias (equivalent to a ScaleLayer+BiasLayer, but
// may be more efficient). Initialized with bias_filler (defaults to 0).
optional bool bias_term = 4 [default = false];
optional FillerParameter bias_filler = 5;
}
从上面我们可以知道这些信息;
(1) scale_layer是输入输出可以都是1个,但是,输入可以是两个,也就是bottom[1]是scale,当没有bottom[1]时,就是通过一个标量参数来实现scale。
(2) scale可以有多种尺寸。从1维到4维。
上面举了例子,当输入x是100x3x40x60,scale blob可以是100; 100x3; 100x3x40; 100x3x40x60这几种尺寸,所以在forward,backward的时候,需要对上尺寸。
这一节看起来比较乱,就当读书笔记吧,只是有很多细节,真的需要自己去抠才知道坑在哪。
更多请移步
1,我的gitchat达人课
龙鹏的达人课
2,AI技术公众号,《与有三学AI》
[caffe解读] caffe从数学公式到代码实现4-认识caffe自带的7大loss
3,以及摄影号,《有三工作室》
冯小刚说,“他懂我”