应用层:
String——字符串
Hash——字典
List——列表
Set——集合
Sorted Set——有序集合
中间层
redisobject
从Redis的使用者的角度来看,一个Redis节点包含多个database(非cluster模式下默认是16个,cluster模式下只能是1个),而一个database维护了从key space到object space的映射关系。这个映射关系的key是string类型,而value可以是多种数据类型,比如:string, list, hash等。我们可以看到,key的类型固定是string,而value可能的类型是多个。
而从Redis内部实现的角度来看,在前面第一篇文章中,我们已经提到过,一个database内的这个映射关系是用一个dict来维护的。dict的key固定用一种数据结构来表达就够了,这就是动态字符串sds。而value则比较复杂,为了在同一个dict内能够存储不同类型的value,这就需要一个通用的数据结构,这个通用的数据结构就是robj(全名是redisObject)。举个例子:如果value是一个list,那么它的内部存储结构是一个quicklist(quicklist的具体实现我们放在后面的文章讨论);如果value是一个string,那么它的内部存储结构一般情况下是一个sds。当然实际情况更复杂一点,比如一个string类型的value,如果它的值是一个数字,那么Redis内部还会把它转成long型来存储,从而减小内存使用。而一个robj既能表示一个sds,也能表示一个quicklist,甚至还能表示一个long型。
底层
dict-hash
dict是一个用于维护key和value映射关系的数据结构,与很多语言中的Map或dictionary类似。Redis的一个database中所有key到value的映射,就是使用一个dict来维护的。不过,这只是它在Redis中的一个用途而已,它在Redis中被使用的地方还有很多。比如,一个Redis hash结构,当它的field较多时,便会采用dict来存储。再比如,Redis配合使用dict和skiplist来共同维护一个sorted set。这些细节我们后面再讨论,在本文中,我们集中精力讨论dict本身的实现。
sds-string
一个sds字符串的完整结构,由在内存地址上前后相邻的两部分组成:
一个header。通常包含字符串的长度(len)、最大容量(alloc)和flags。sdshdr5有所不同。
一个字符数组。这个字符数组的长度等于最大容量+1。真正有效的字符串数据,其长度通常小于最大容量。在真正的字符串数据之后,是空余未用的字节(一般以字节0填充),允许在不重新分配内存的前提下让字符串数据向后做有限的扩展。在真正的字符串数据之后,还有一个NULL结束符,即ASCII码为0的’\0’字符。这是为了和传统C字符串兼容。之所以字符数组的长度比最大容量多1个字节,就是为了在字符串长度达到最大容量时仍然有1个字节存放NULL结束符。
ziplist
翻译一下就是说:ziplist是一个经过特殊编码的双向链表,它的设计目标就是为了提高存储效率。ziplist可以用于存储字符串或整数,其中整数是按真正的二进制表示进行编码的,而不是编码成字符串序列。它能以O(1)的时间复杂度在表的两端提供push和pop操作。
实际上,ziplist充分体现了Redis对于存储效率的追求。一个普通的双向链表,链表中每一项都占用独立的一块内存,各项之间用地址指针(或引用)连接起来。这种方式会带来大量的内存碎片,而且地址指针也会占用额外的内存。而ziplist却是将表中每一项存放在前后连续的地址空间内,一个ziplist整体占用一大块内存。它是一个表(list),但其实不是一个链表(linked list)。
quicklist
它确实是一个双向链表,而且是一个ziplist的双向链表。
这是什么意思呢?
我们知道,双向链表是由多个节点(Node)组成的。这个描述的意思是:quicklist的每个节点都是一个ziplist。ziplist我们已经在上一篇介绍过。
ziplist本身也是一个能维持数据项先后顺序的列表(按插入位置),而且是一个内存紧缩的列表(各个数据项在内存上前后相邻)。比如,一个包含3个节点的quicklist,如果每个节点的ziplist又包含4个数据项,那么对外表现上,这个list就总共包含12个数据项。
quicklist的结构为什么这样设计呢?总结起来,大概又是一个空间和时间的折中:
双向链表便于在表的两端进行push和pop操作,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
ziplist由于是一整块连续内存,所以存储效率很高。但是,它不利于修改操作,每次数据变动都会引发一次内存的realloc。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝,进一步降低性能。
于是,结合了双向链表和ziplist的优点,quicklist就应运而生了。
不过,这也带来了一个新问题:到底一个quicklist节点包含多长的ziplist合适呢?比如,同样是存储12个数据项,既可以是一个quicklist包含3个节点,而每个节点的ziplist又包含4个数据项,也可以是一个quicklist包含6个节点,而每个节点的ziplist又包含2个数据项。
skiplist
这种数据结构是由William Pugh发明的,最早出现于他在1990年发表的论文《Skip Lists: A Probabilistic Alternative to Balanced Trees》。对细节感兴趣的同学可以下载论文原文来阅读。
skiplist,顾名思义,首先它是一个list。实际上,它是在有序链表的基础上发展起来的。
我们先来看一个有序链表,如下图(最左侧的灰色节点表示一个空的头结点):
在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中进行查找。比如,我们想查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:

23首先和7比较,再和19比较,比它们都大,继续向后比较。
但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。
利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:

在这个新的三层链表结构上,如果我们还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。比如,一个节点随机出的层数是3,那么就把它链入到第1层到第3层这三层链表中。为了表达清楚,下图展示了如何通过一步步的插入操作从而形成一个skiplist的过程:
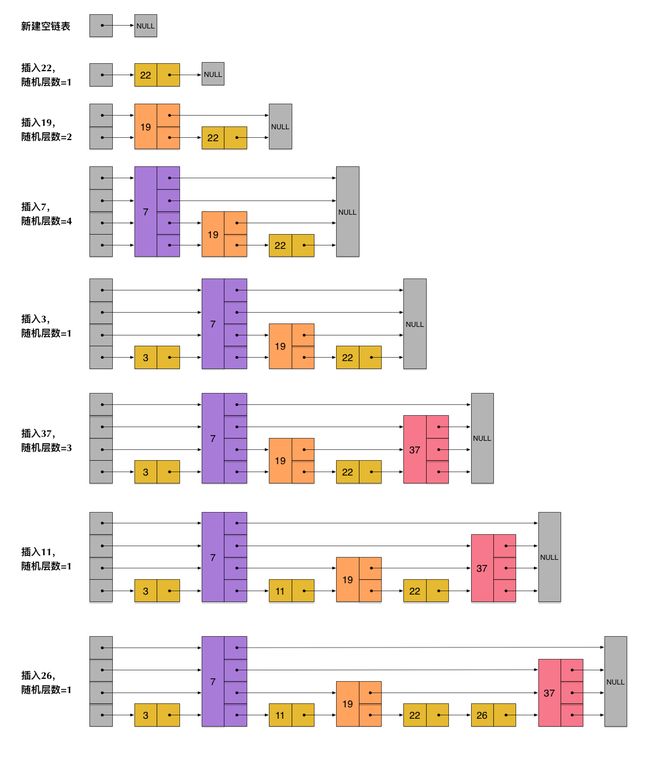
从上面skiplist的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。这在后面我们还会提到。
intset
encoding: 数据编码,表示intset中的每个数据元素用几个字节来存储。它有三种可能的取值:INTSET_ENC_INT16表示每个元素用2个字节存储,INTSET_ENC_INT32表示每个元素用4个字节存储,INTSET_ENC_INT64表示每个元素用8个字节存储。因此,intset中存储的整数最多只能占用64bit。
length: 表示intset中的元素个数。encoding和length两个字段构成了intset的头部(header)。
contents: 是一个柔性数组(flexible array member),表示intset的header后面紧跟着数据元素。这个数组的总长度(即总字节数)等于encoding * length。柔性数组在Redis的很多数据结构的定义中都出现过(例如sds,quicklist,skiplist),用于表达一个偏移量。contents需要单独为其分配空间,这部分内存不包含在intset结构当中。
其中需要注意的是,intset可能会随着数据的添加而改变它的数据编码:
最开始,新创建的intset使用占内存最小的INTSET_ENC_INT16(值为2)作为数据编码。
每添加一个新元素,则根据元素大小决定是否对数据编码进行升级。
下图给出了一个添加数据的具体例子(点击看大图)。

在上图中:
新创建的intset只有一个header,总共8个字节。其中encoding= 2,length= 0。
添加13, 5两个元素之后,因为它们是比较小的整数,都能使用2个字节表示,所以encoding不变,值还是2。
当添加32768的时候,它不再能用2个字节来表示了(2个字节能表达的数据范围是-215~215-1,而32768等于215,超出范围了),因此encoding必须升级到INTSET_ENC_INT32(值为4),即用4个字节表示一个元素。
在添加每个元素的过程中,intset始终保持从小到大有序。
与ziplist类似,intset也是按小端(little endian)模式存储的(参见维基百科词条Endianness)。比如,在上图中intset添加完所有数据之后,表示encoding字段的4个字节应该解释成0x00000004,而第5个数据应该解释成0x000186A0 = 100000。
intset与ziplist相比:
ziplist可以存储任意二进制串,而intset只能存储整数。
ziplist是无序的,而intset是从小到大有序的。因此,在ziplist上查找只能遍历,而在intset上可以进行二分查找,性能更高。
ziplist可以对每个数据项进行不同的变长编码(每个数据项前面都有数据长度字段len),而intset只能整体使用一个统一的编码(encoding)。