文章名:Visualizing theHidden Activity of Artificial Neural Networks
(对人工神经网络的隐式行为进行可视化)
期刊:IEEE Transactions on Visualization and Computer Graphics
在机器学习中,模式分类对实例样本进行学习,得到模型后把高维向量进行分类。目前,人工神经网络在这方面中获得了最先进的结果,但是,以前研究者往往把神经网络的内部行为当成黑盒来处理,至于神经网络到底做了什么,研究者并不了解。而这篇文章则是使用可视化的技术对神经网络的隐式行为进行可视化,为神经网络设计者提供非常有价值的反馈与参考。
基础知识:
在讲这篇文章的任务之前,先简单了解一下神经网络,下图中给出了一个典型的神经网络结构,其中图中的每一个小圆都是一个神经元,每一竖对应与神经网络的每一层,左边一竖代表的是输入层,中间带灰色条的是隐藏层,就是本文需要可视化的部分,右边一层是输出层,除第一层外,每个神经元都有若干输入,而前一层的输出作为下一层的输入,最后一层的输出不在作为其它神经元的输入,当然同一层神经元是没有值传递的
一个神经元接收若干输入,计算他们的加权和,然后使用激活函数对这个和进行处理后(例如加入惩罚函数或者奖励函数),得到输出值,而这里的权重就是神经元待学习的参数。

数据与模型:
为了进行具体的研究,本文给出了两种神经网络:1、多层感知机(MLP)2、卷积神经网络(CNN),并且给出了三种数据集,1、MNIST,2、SVHN,3、CIFAR-10。
多层感知器:结果类似于刚刚所给的经典神经网络,不过其有4个隐藏层。
卷积神经网络:由一个或者多个卷积层和顶端的全连通层(对应经典神经
网络)组成,同时也包括关联权重和池化层。
三组数据:1、MNIST,2、SVHN,3、CIFAR-10,这三组数据都是用来测试图片中的数字或物体的识别任务的。

上表给出了两种神经网络在三个数据集中能达到的准确率,在上表最后一列则给出了现在的技术在这三个数据集中能够达到的最高准确率
任务:
我们回到神经网络本身,在神经网络中,可以用来可视化的数据包括两类,一是每一层神经元的输出,它们对应输入数据在网络中的不同表示,二是每一个神经元所学习到的权重,他刻画着各个神经元的行为,即如何对输入进行响应,本文针对这些数据提出了两个任务:
任务一:研究数据表示间的关系
任务二:研究神经元间的关系
具体分析:
任务一:研究数据表示间的关系
1.1 MNIST数据集:探索训练的效果

上图是MNIST数据没有经过训练,直接进行投影的投影图,其中由于原始数据已经有所属类别,那么研究数据表示间的聚类关系是非常有必要的,所以作者选择了能很好保留相邻关系和聚类关系的t-SNE投影方法进行投影,其中文中的NH指的是邻域命中率,表示的是数据经过投影后,选择一个数据a,在其K近邻中,有与它所属的类别相同的数据数量记为Ma,那么该数据的邻域命中率为Ma/K,在本文中K取值为6。

左图是未经MLP训练的MNIST数据集的投影图,可以发现其实有不错的类间区分性,右图是经过MLP训练后的投影图,可以看见类间的区分性大大增强了,同时预测的准确率也得到提高,这说明根据内部的类间区分性能一定层度上预测准确率,同时也说明了模型的训练过程,也是提高类间区分性的过程,在图3的右图中的插图中我们可以看到,数字3的图像被误认为数字5,并且放在数字5的视觉集群附近,这表明投影并不能完全保留数据结构。
1.2 SVHN数据集:解释视觉集群

图4是SVHN测试子集的投影图,我们会发现它比MNIST的投影图更具挑战性,它的类间区分性比较差

图5表明投影图可以用来比较同一模型不同层的区别,图5的a图表示MLP第一层的投影图,b图表示最后一层的投影图,从中我们可以发现,随着训练,类间的区分性不断加大。

上图是作者将SVHN数据集的CNN最后一层神经元输出进行投影,从投影图中可以明显的看出每个类别的点都基本形成了两个类,经过对投影探测,我们发现其中一个类对应的是浅色背景上的深色数字,另一类为深色背景上的浅色数字,而通过对这个探测,如果对测试数据进行进一步的操作,可以提高模型的准确率和邻域命中率,作者就对测试数据进行了处理消除了颜色深浅带来的影响,使得预测准确率得到了提高。
在图中,我们可以观察到数字9被聚到了数字2这一类别,经过观察,可以发现数字9的背景就像一个深色的数字2,所以使得该数被聚类到深色的数字2附近,如果能消除这种颜色带来的影响,那么可以提高预测的准确率。

图7则是验证了训练集的类别之间的分类效果比测试集的好,并且严格分开的训练集网络可能表示训练有素的网络,而过于分散或者分离不足的测试集投影则可能是,没有充分拟合或者过拟合造成的,从图7中我们看到中心区域类间分离不好,这也是大多数分类错误的地方。

图8的左上角的两个灰色点中,虽然CNN正确的分类了这些点(数字7),都是它们都靠近橙色点,即数字1,观察发现,这两个点的7与1很相似,而这也可能给出一个信号,即最后一层可能过度适应内部表示,这可能意味着该神经网络在类似的情况下不能很好的对这类问题分类。
1.3 CIFAR-10数据集:解释混乱区域

图9与之前一样中间区域是分类比较混乱的,它们的并没有很好的区分开,大部分的分类错误都发生在这,而在左上角的青色区域发现有一个异常值,本应是汽车的数据分到了卡车行列,经过观察发现,该汽车的外表与卡车相似。
1.4 随着训练而改变的学习特征

通过将多个投影图联合起来观察,还可以研究模型中数据表示的动态变化,左侧的四张小图展示的是MLP在每一个隐含层之后,数据表示的投影情况,右侧大图则表示把同一数据不同层的表示用曲线连接,用颜色表示层间先后顺序,作者同时采用捆绑技术来减少视觉混乱,从图中可以看到随着层次的推进,数据类内部的一致性和类间的区分性得到强化,并且还可以观察到,随着迭代的过程,数据是怎么变化的
任务二:研究神经元间的关系
在任务二中,因为神经元间的关系主要考虑的是它们之间线性相关的大小,所以在这篇文章中,作者为了选择能尽量保持距离的MDS投影,在本文中作者定义了不相似系数
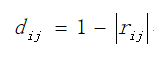
其中d-ij是神经元i和神经元j之间的不相似系数,r-ij则是神经网络L层(任意一隐藏层)激活量组成的数据集中,神经元i和神经元j之间的Pearson相关系数(Pearson相关系数是用来衡量两个数据集合是否在一条线上面,它用来衡量定距变量间的线性关系。激活向量的每一个元素是一个神经元的输出)这个度量指标同时包括了正和负的线性相关系数。对于得到的成对不相似矩阵,作者采用了MDS进行投影。

上图为由CNN(未)训练后最后一层隐藏层激活的相应数据(神经元)投影,左边代表的是数据投影图,右边是神经元投影图,上面代表的是未训练的,下面代表的是经过训练的。观看图d,如果暂时忽略颜色,我们在神经元的投影中看不见清晰的图案,只能看到模糊的分类簇,作者基于非常随机树的标准特征选择技术提供了一个分数来衡量给定神经元(特征)在给定的类和其他类之间的重要性。作者进行该操作后,发现一个非常清晰的模式出现在了神经元的投影图中。
如果作者在未训练的图中选择数字8对应是数据点,然后在神经元投影图中对这些高激活的神经元进行高亮,发现这些神经元分布在四周,然后作者对经过训练的数据进行相同操作,发现这些神经元基本形成了一个聚类,也就是说它们之间比较相似,经过训练后,这些相似的神经元将聚在一起。

左侧图中,作者根据每个神经元最易激活的类别对它们进行着色,其中,编号为460的神经元最容易对数字3产生高激活值,在对应的数据表示的投影图中,我们能看到被这个神经元激活的数据点主要对应浅色背景上的深色数字3这一聚类,但在一些数字5的数据上也会产生错误。通过类似的分析方法,研究者可以了解神经元的行为与角色。
结论:
优点:
作者使用降维的方法探索了深度神经网络中数据表达之间的关系和
神经元之间的关系
缺点:
本文只使用了两种神经网络与三种数据集,覆盖范围比较小
总的来说,本篇论文的思想是比较简单的,实现起来也是比较容易的,但是这篇文章可以说是作者做为第一个对这方面工作进行研究,即用可视化技术详细分析了通过隐藏层来预测分类系统的效果,并且探索隐藏层中神经元之间的关系。
原作者:Paulo E. Rauber 等
笔记撰写人:侯扬波
整理:张宇鸿