系列文章
- 秋名山涧--给班长的开车APP -- 用爬虫webmagic爬取数据(一)
- 秋名山涧--给班长的开车APP -- 用MySql结合JDBC保存数据到数据库(二)
- 秋名山涧--给班长的开车APP -- 用Rest API制作API接口(三)
小喇叭开篇啦!!!

开发环境
Win 10
IDEA Ultimate 2017.1.4
JDK 1.8.0_102
你要是想详细研究Webmagic爬虫框架可以去 WebMagic doc页仔细研读,目前此框架个人觉得少个爬数据完成时的回调。。。
无异议就开始咯,我觉得要写详细点....
新建一个Java Project
其他的都不用点啦,直接新建
为了可以用Mevan加载jar包,对着项目点右键
将Maven打勾,确定,然后项目中多出pom.xml文件
将这个复制到pom.xml文件中,然后保存,打开自动导包(会有自动提示),稍等完成webmagic的导包
us.codecraft
webmagic-core
0.7.2
us.codecraft
webmagic-extension
0.7.2
...
根据WebMagic的使用说明, 新建一个类MeizituRepoProcessor实现接口PageProcessor
public class MeituRepoProcessor implements PageProcessor {
public MeituRepoProcessor() {
}
public void process(Page page) {
}
public Site getSite() {
return null;
}
}
现在还什么都没有
1 分析网站结构
www.meizitu.com的网页结构是
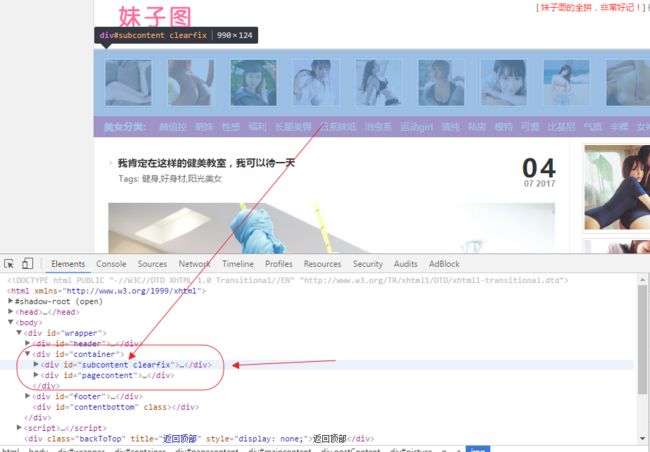
可以看到主要内容是在id为container的div里
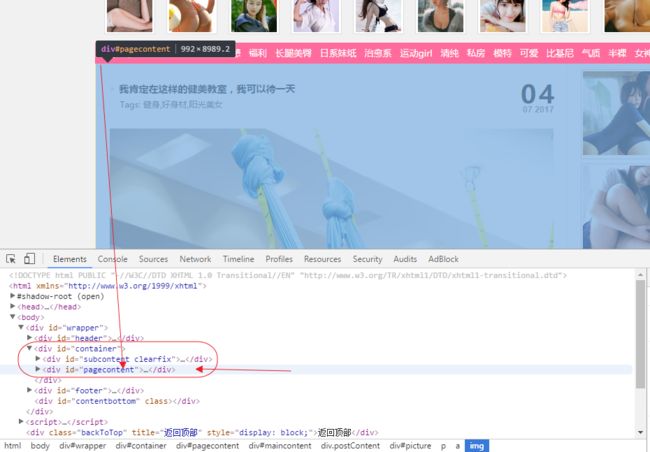
现在我们需要的数据在id为pagecontent的div里
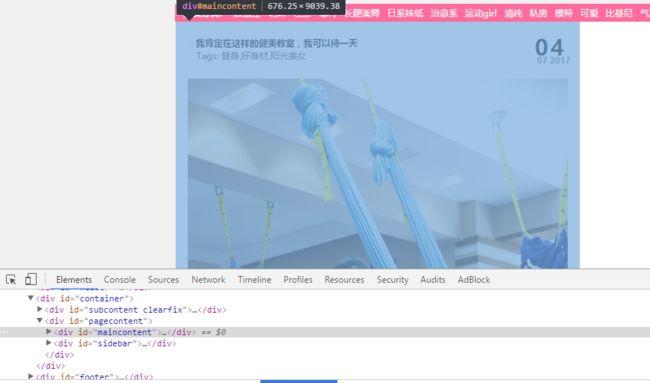
进一步的分析我们可以看到我们要的数据在pagecontent里面id为maincontent的盒子里
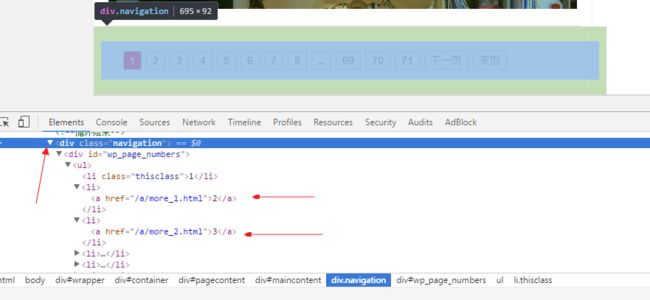
这个是底部的别的页的网址,结构是/a/more_1.html,/a/more_2.html,/a/more_3.html....

接着再看图片的信息,这个就是我们最终要爬的数据之一
再举个栗子
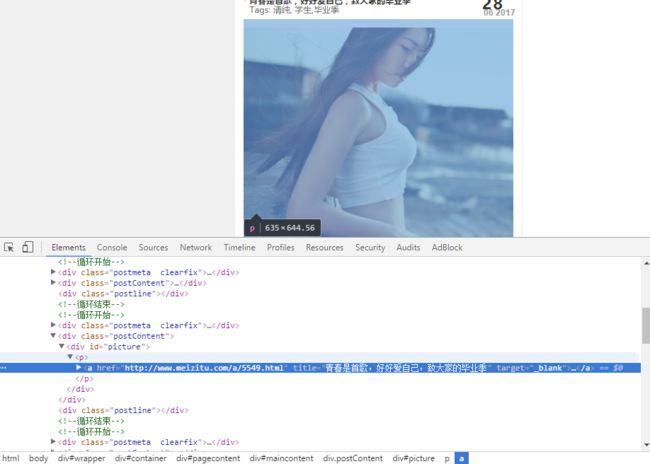
观察网址规律
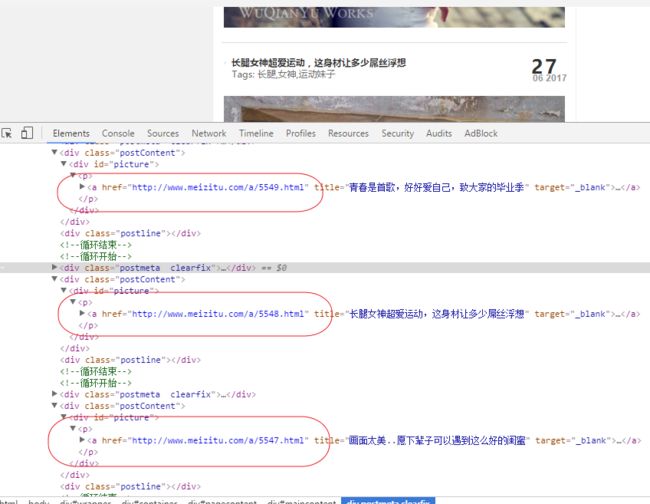
发现都是 www.meizitu.com/a/****(数字).html
正则表达式表示为:(http://www.meizitu.com/a/(\d{4}).html)
点进大图,比如,http://www.meizitu.com/a/5551.html
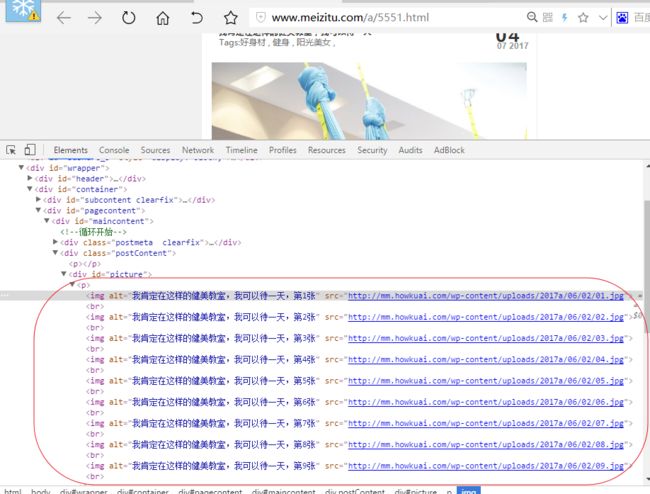
可以看到,图片的网址都在img标签的src属性下
类似 mm.howkuai.com/wp-content/uploads/****(一系列数字日期表示).jpg
正则表达式为: (http://mm.howkuai.com/wp-content/uploads/(.*).jpg)
--
2 根据这些规律
MeituRepoProcessor中添加实现代码
public class MeituRepoProcessor implements PageProcessor {
public MeituRepoProcessor() {
}
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
public void process(Page page) {
//选取网页中css为id为maincontent的div,然后选取所有链接,再用正则表达式过滤掉
List urls = page.getHtml().css("#maincontent").links().regex("(http:\\/\\/www\\.meizitu\\.com\\/a\\/(\\d{4})\\.html)").all();
//将待爬取的网址加到抓取队列池中
page.addTargetRequests(urls);
//这个是提取的主站www.meizitu.com的每个突变的title,用xpath表示,这个可以在调试里面下节点右键copy的到xpath地址,后面的这里的意思是id为maincontent的容器(这里是div)中的第一个盒子下的第一个盒子中的h2标签下的a标签的文字
page.putField("webTitle", page.getHtml().xpath("//*[@id=\"maincontent\"]/div[1]/div[1]/h2/a/text()"));
//先用xpath过滤到具体大的块(id为picture的容器中的p标签的img标签的src属性值),接着正则表达式提取出来(规律)
page.putField("picName", page.getHtml().xpath("//*[@id=\"picture\"]/p/img[@src]").regex("(http:\\/\\/mm\\.howkuai\\.com\\/wp-content\\/uploads\\/(.*)\\.jpg)").all());
if (page.getResultItems().get("picName") == null) {
//如果当前获取到的图片网址为null,那么跳到网址池中下一个网址抓取
page.setSkip(true);
}
//抓取底部的更多页面的地址
List nextUrls = page.getHtml().regex("(\\/a\\/more_(.*?)\\.html)").all();
page.putField("nextUrls", nextUrls);
//添加到池中
page.addTargetRequests(nextUrls);
}
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new MeituRepoProcessor())
.addUrl("http://www.meizitu.com/")
.addPipeline(new ConsolePipeline())
.thread(1)
.run();
}
}
注释很清楚了,就不多BB了
这里加了main方法,在Idea中可以在方法体里右键run main()方法测试,数据会全部打印到控制台。
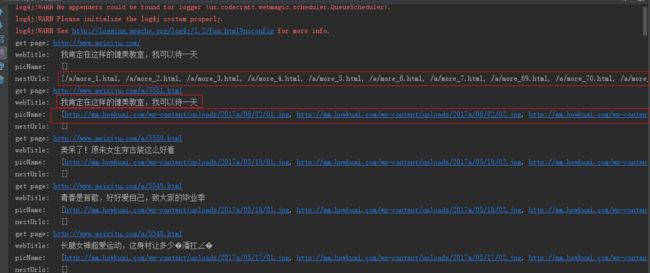
可以看到数据都是在数组里面,第一个框是更多页的地址,第二个框是title,第三个是图片的url地址数组。
可以看到目前为止,数据已经爬取成功了,本篇的(一)可以结束了
然后哎呀图片地址都搞出来了,我就是控几不住我记几啊,然后就写了个工具类全部下载下来了。。。啊哈哈哈啊哈
新建一个类叫做PineLineTest实现PineLine接口
public class PileLineTest implements Pipeline {
public PileLineTest() {
System.out.println("到大这里1");
}
int downLoadPosition = 1;
public void process(ResultItems resultItems, Task task) {
System.out.println("图片抓取页为:" + resultItems.getRequest().getUrl());
List urls = resultItems.get("picName");
System.out.println("抓取图片序号为" + downLoadPosition + "开始进入下载");
try {
for (int i = 0; i < urls.size(); i++) {
DownLoadImage.downLoad(urls.get(i), "pic" + i + ".jpg", "D:\\webmagic\\SpiderA\\pic" + downLoadPosition);
}
downLoadPosition++;
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("抓取图片序号为" + downLoadPosition + "下载结束");
}
}
工具类DownLoadImage 如下
package utils;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
/**
* Created by Niwa on 2017/7/2.
*/
public class DownLoadImage {
public static void downLoad(String urlString, String fileName, String savePath) throws IOException {
URL url = new URL(urlString);
URLConnection con = url.openConnection();
con.setRequestProperty("User-Agent","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11");
con.setConnectTimeout(5 * 1000);
InputStream is = con.getInputStream();
byte[] bs = new byte[1024];
int len;
File sf = new File(savePath);
if (!sf.exists()) {
sf.mkdirs();
}
OutputStream os = new FileOutputStream(sf.getPath() + "\\" + fileName);
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
is.close();
System.out.println(urlString + "下载成功");
}
}
接着去main方法里把
.addPipeline(new ConsolePipeline())
换成
.addPipeline(new PileLineTest())
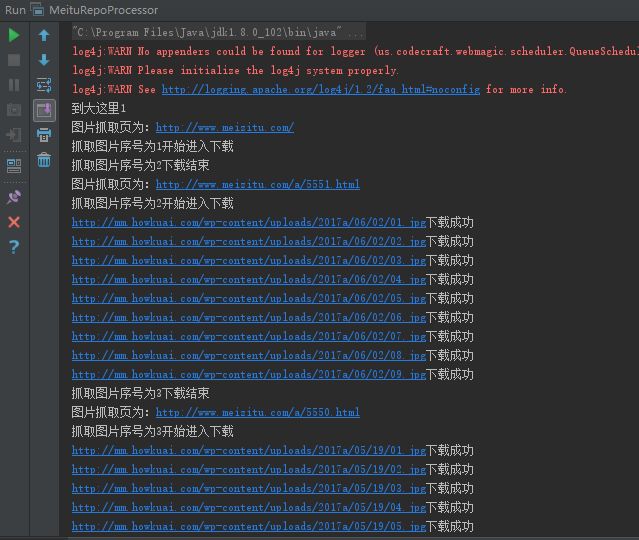
运行
3 注意事项
如果爬取的太快,可能会导致服务器403禁止访问,这个时候换个IP地址就可以了
最大能力去模拟浏览器的人为操作,比如爬一个数据休息随机秒,爬完一个数据更换IP接着爬
跳转到(二)
参考
爬虫:webmagic
正则表达式学习:正则表达式学习

全世界晚安!
The End !