排序算法中,经常见到的有八种排序算法,这里我们不包括在内存的外部进行排序。
这八种排序算法分别是:
冒泡排序、选择排序、插入排序、归并排序、快速排序、堆排序、希尔排序、基数排序。
在讲具体的排序算法之前,我先给大家推荐一个对学习算法和数据结构非常有帮助的网站:armStrong数据结构与算法小动画,这个网站把各种数据结构与算法的原理做成了一个个小动画,非常直观的帮助我们理解和学习。如果打不开这个网站的话,请切换浏览器。
好了,接下来是具体的算法讲解部分。
1. 冒泡排序O(n^2)
先来看原理部分,冒泡排序就是将每个数与它后面的数进行比较,如果大于之后的数,就两者交换,一直循环前面的操作,直到该数小于后面的数为止。口说无凭,直接看动画吧,这就用到了我上面推荐的网站了,直接把冒泡排序的网址贴在这里吧!冒泡排序原理动画 相信现在你已经看完了冒泡排序的原理动画,现在我需要你脑海里回想着刚刚看到的动画,同时来思考我们下面的代码
public int[] bubbleSort(int[] A) {
for (int i = 0; i < A.length - 1; i++) {
for (int j = 0; j < A.length - 1 - i; j++) {
if (A[j] > A[j + 1]) {
int temp = A[j];
A[j] = A[j + 1];
A[j + 1] = temp;
}
}
}
return A;
}
这是一段冒泡排序的代码,在第一层循环里面,因为数组有A.length个元素,需要比较 A.length - 1次,所以我们循环的次数是 A.length-1。
在第二层循环里面,想象一下你刚才看到的动画,当一个数往后交换一直到交换不动的时候,是因为它后面的数都已经比它大了,此时这个数连同它后面的数都是有序的,所以我们下一次循环时就不需要再对这些数进行比较了。所以我们比较的范围要逐渐减小,只需要比较 0~A.length-1-i 之间的数就可以了。
2. 选择排序O(n^2)
选择排序的原理就是,每次从无序的序列中循环选出最小的数,将它交换到无序序列的最前面,最终在数组中形成一个从前往后排列的有序序列。看动画选择排序原理动画,同样的,脑海里带着刚才看到的画面,来思考我们下面的代码
public int[] selectionSort(int[] A) {
for (int i = 0; i < A.length - 1; i++) {
int min = A[i];
int minIndex = i;
for (int j = i + 1; j < A.length; j++) {
if (A[j] < min) {
min = A[j];
minIndex = j;
}
}
A[minIndex] = A[i];
A[i] = min;
}
return A;
}
最外层的循环中,i 代表着我们无序序列的第一个元素位置,我们先假使它是无需序列中最小的元素,每次循环,从该位置之后的元素中,选出最小的元素,如果这个最小的元素比 i 位置上的元素还小,就将它们两个交换。而随着 i 的增加,我们的无需序列也在不断减小,最后就形成了一个从小到大排列的有序序列。
3. 插入排序O(n^2)
插入排序和选择排序有点类似,都是把序列前面的部分看成有序的序列,后面部分看成无序的序列。每次会选定无序序列中第一个元素,插入到有序序列中的合适位置,随着有序序列的长度不断增加,最终形成一个完全的有序序列。
看动画插入排序原理动画
接下来放上我们的插入排序代码
public int[] insertionSort(int[] A) {
// write code here
for (int i = 1; i < A.length; i++) {
int point = i;
for (int j = i - 1; j >= 0; j--) {
if (A[point] < A[j]) {
int temp = A[point];
A[point] = A[j];
A[j] = temp;
point = j;
}
}
}
return A;
}
这段代码很好理解,首先将将序列的第 0 个元素看作有序的,所以 i 的初始值为 1,A[i] 就是无序序列的第一个元素,然后将 A[i] 和它前面的有序序列中的元素作比较,并且插到合适的位置。这里注意一点,我们的比较是从后往前的,即 A[i] 首先和它前面的做比较,如果小于它前面的元素就交换位置,然后再和它现在的前面的元素作比较,直到找到一个小于 A[i] 的元素,比较结束。但 i 是一直在改变的啊,那我们怎么才能确保每次都是移动的同一个元素呢? 加个point指针就好了嘛。
4. 归并排序O(n * logn)
前面三个都是时间复杂度为 n 的平方的排序算法,下面来讲时间复杂度为
n * logn的排序算法,首先从归并排序讲起。
看原理图(刚刚画的,之前没怎么画过,才开始写博客,都是借别人的图,但是这个归并排序人家动画里没有,只能自己动手了)
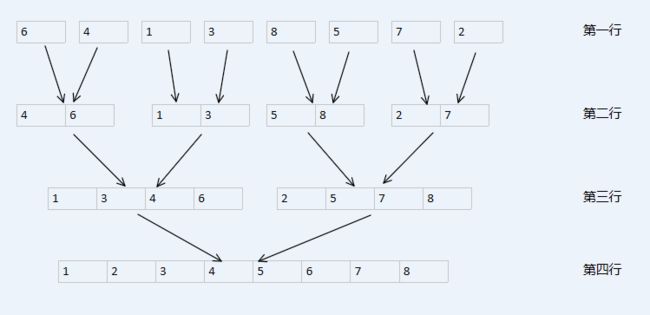
归并排序首先将序列看成一个个长度为 1 的有序序列,然后将相邻的两个序列归并,形成一个按照大小排好序的长度为 2 的有序序列。以此类推,最后形成完全有序的一个序列。
归并的过程也就是这个排序算法的关键步骤,这个人家的动画里有,我直接搬过来了归并相邻序列的动画
好了,该放代码了
public static void mergeSort(int[] list) {
if (list.length > 1) {
int[] firstHalf = new int[list.length / 2];
System.arraycopy(list, 0, firstHalf, 0, list.length / 2);
mergeSort(firstHalf);
int secondHalfLength = list.length - list.length / 2;
int[] secondHalf = new int[secondHalfLength];
System.arraycopy(list, list.length / 2, secondHalf, 0, secondHalfLength);
mergeSort(secondHalf);
int[] temp = merge(firstHalf, secondHalf);
System.arraycopy(temp, 0, list, 0, temp.length);
}
}
public static int[] merge(int[] firstHalf, int[] secondHalf) {
int[] temp = new int[firstHalf.length + secondHalf.length];
int firstIndex = 0;
int secondIndex = 0;
int tempIndex = 0;
while (firstIndex < firstHalf.length && secondIndex < secondHalf.length) {
if (firstHalf[firstIndex] < secondHalf[secondIndex]) {
temp[tempIndex++] = firstHalf[firstIndex++];
} else {
temp[tempIndex++] = secondHalf[secondIndex++];
}
}
while (firstIndex < firstHalf.length) {
temp[tempIndex++] = firstHalf[firstIndex++];
}
while (secondIndex < secondHalf.length) {
temp[tempIndex++] = secondHalf[secondIndex++];
}
return temp;
}
代码开始变得越来越复杂了,不过不用怕,我会一点一点的讲明白。
首先这里我们定义了两个方法,mergeSort() 就是一个递归调用,每次将序列分成两半,然后再通过merge() 方法对两个序列进行归并。所以merge() 方法就是我们归并排序的关键。
先来讲将序列分成两半的代码部分,也就是mergeSort() 方法部分。在这个方法里,我们以 list.length > 1 为递归的边界条件(递归必须有边界条件,否则就会报出StackOverflowException),代码很明了,将传入的 list[] 分成两部分 firstHalf[] 和 secondHalf[] 两部分,然后将这两个数组传入 merge 方法进行归并。
这里有一个坑,有同学可能直接会把 merge() 方法的返回值赋给 list。这样的做法是错误的,先贴一下主方法的代码:
public static void main(String[] args) { int[] list = {2, 3, 2, 5, 6, 1, -2, 3, 14, 12}; mergeSort(list); System.out.println(Arrays.toString(list)); }因为这样的结果只是改变了 mergeSort() 方法中 list 的指针,但是我们主方法中的 list[] 并没有改变,还是之前的结果。所以我们用到了
System.arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
这个API来对数组进行复制。
接下来是最关键的 merge() 方法,刚刚的动画没忘吧,首先建立一个 temp[] 数组用来存放归并之后的元素,然后定义三个指针,在第一个while循环比较两个数组中的第一个元素,将较小者赋给 temp[] ,然后改变指针,直到两个数组中的某一个遍历到了末尾。
剩下的两个 while 循环就是判断了一下:上面的两个数组中哪一个还没有遍历完,因为两个数组可能不是一样的长度,所以长的那个要把剩下的元素全都拷贝到 temp[] 中。
5. 快速排序O(n * logn)
现在来讲快排,正如时间复杂度变得越来越小,换来的却是算法的复杂度越来越高,现在我开始有点力不从心了。
快排的原理:
在数组中选取一个称为主元的(pivot)元素,然后根据主元对数组进行划分(partition),划分之后的数组变成两部分,第一部分中的元素全都小于主元,第二部分中的元素全都大于主元,然后再分别对第一部分和第二部分递归调用快排算法。
所以快速排序算法的关键就在于如何划分。请看动画
快排划分过程动画
清楚了如何划分,剩下的就是递归调用了,我画了一张原理图,

正如上面讲的,经过一次划分后, 5 的左边都是小于它的元素,右边都是大于它的元素,然后分别对两边的数组递归调用快排算法。
万事俱备,该放代码了
public static void quickSort(int[] list) {
quickSort(list, 0, list.length - 1);
}
private static void quickSort(int[] list, int first, int last) {
if (first < last) {
int midIndex = partition(list, first, last);
quickSort(list, 0, midIndex - 1);
quickSort(list, midIndex + 1, last);
}
}
private static int partition(int[] list, int first, int last) {
int pivot = list[first];
int low = first + 1;
int high = last;
while (low < high) {
while (low < high && list[low] <= pivot) {
low++;
}
while (low < high && list[high] >= pivot) {
high--;
}
if (low < high) {
int temp = list[low];
list[low] = list[high];
list[high] = temp;
}
}
if (pivot < list[high]) {
high--;
}
list[first] = list[high];
list[high] = pivot;
return high;
}
最上面的 quickSort(int[] list) 就是用于外部调用的快速排序方法,可以看到里面只有一行代码,它调用了我们下面封装的一个私有的 quickSort(int[] list, int first, int last) 重载方法。
在第二个 quickSort(int[] list, int first, int last) 方法中,执行的就是我们的递归过程。first 代表着 list 的首位置, last 代表着 list 中最后一个元素位置。递归以 (first < last) 为边界。首先对 list 执行一次划分,然后根据返回的主元的位置,再对剩下的两部分进行递归。
最后也是最关键的部分,划分的代码,来看 partition 里面的逻辑。
在这个方法里,我们先假定数组中的第一个元素为主元,就如同我画的图中的第一行。然后定义两个指针 low 和 high ,忘了划分步骤的,赶快回去看动画,接下来要飙车了。
在动画里我们看到, low 和 high 不断往中间移,而 list[low] 代表着小于主元的元素, list[high] 代表着大于主元的元素.
所以当 list[low] =< pivot <= list[high] 的时候,我们就不断执行 low++ 和 high-- ,一直遇到 list[low] > pivot 和 list[high] < pivot 的情况,这时候我们就要对 list[low] 和 list[high] 执行交换,使其一直保持 list[low]=< pivot <= list[high] 这样的姿势。
注意一点,在 low++ 和 high-- 这两个 while 循环中,我们附加了一个额外条件 low < high ,这并不多余!!因为主元的右边可能是全部小于它的数或者全部大于它的数,这样的情况下 low 和 high 继续改变下去就会报出数组越界异常。
当 low 和 high 相遇后,最外层的 while 循环结束,此时 low = high, 即 list[low] = list[high],这时候该做的是把主元移动到它该去的位置,而不是还呆在数组的开头。那我们该把它调到哪里呢?直接和 list[high] (或 list[low],它们此时是相等的) 交换吗?
不行,因为此时 list[low] = list[high] 可能大于 pivot,直接换到数组的开头后,就会出现主元的左边有大于它的元素的情况,这和我们划分的思想不符,那怎么办呢?
list[low] 虽然大于主元,但是它前边的 list[low--] 肯定小于主元啊!那我们加个判断,判断一下 list[low] (或 list[high])是不是真的大于主元,如果真的大于的话,就让 low-- (或 high--),最后再执行交换。
这样主元就回到了正确的位置,然后我们返回它的位置,为下一次划分做准备。
这就是快速排序,是不是很啰嗦?没关系,一遍看不太懂的话,就多看几遍,因为后面还有更难的 -_-||
6. 堆排序O(n * logn)
学过数据结构的同学应该对堆不陌生,它就是一个二叉树,我们这次的堆排序用到的堆比较特殊,它是一个大根堆,所谓的大根堆就是指父节点的值永远比子节点的大。堆顶是堆中所有元素最大的。
所以堆排序的原理就是首先建立一个大根堆,然后每次移除堆顶元素,再把剩下的元素重新调整成大根堆的过程。因为堆顶是最大的元素,所以每次移除出来的一个个堆顶就构成了一个从大到小排好序的序列。
可以看到,堆排序的关键就在于构建堆与移除堆顶后的调整堆。
先看构建堆的动画构建堆的动画
动画省略了一些步骤,它只输出了结果,而构建是有一个过程的。首先会把新元素追加到堆尾,然后让它跟它的父节点比较,如果大于父节点,就和父节点交换,然后继续和新的父节点比较。。。一直循环,最后重新建成一个大根堆。
然后是移除堆顶后的堆调整过程,我画了一张图。
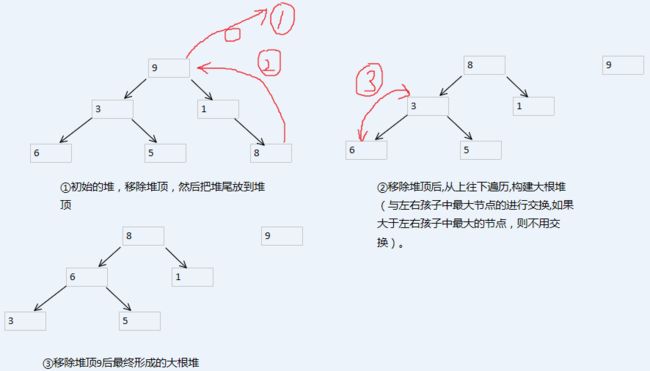
堆调整的过程分三步,就是我们红线标注的部分。
第一步,移除堆顶,放在一边,你可以放在一个数组里边,因为每次移除的堆顶都是堆中的最大元素,所以数组最终变成一个从大到小排好序的序列。
第二步,把堆尾元素放到堆顶。
第三步,从新的堆顶开始往下遍历,如果小于左右孩子中的最大节点,则进行交换,大于的话则不用交换。如 ② 中 8 大于 3 (3 是 8 的左右孩子中最大的节点),则 8 和 3不用交换,而 3 小于 6,所以 3 和 6 交换。
接下来看代码,这次我换了一个方式,把代码的讲解放到了代码注释里,这对代码量大的场合很方便。
//建立一个内部类Heap
private class Heap{
//用一个List来存放堆中的元素
List list = new ArrayList();
//构造函数,将传入的数组最终构建成大根堆
private Heap(int[] array) {
for (int i = 0; i < array.length; i++) {
add(array[i]);
}
}
/**
* 功能:每次先把传入的元素放在堆尾,然后调整,变成一个元素个数多一的大根堆
* @param num 传入的元素
*/
private void add(int num) {
list.add(num); //先将传入的元素追加在堆尾
int currentIndex = list.size() - 1; //从堆尾开始遍历
while (currentIndex > 0) {
int parentIndex = (currentIndex - 1) / 2; //先找到堆尾元素的父节点
//因为我们要构建的是大根堆,所以当父节点小于当前节点时,两者交换。
// 否则说明刚刚追加的元素合适,直接退出循环
if ((list.get(currentIndex).compareTo(list.get(parentIndex))) > 0) {
int temp = list.get(currentIndex);
list.set(currentIndex, list.get(parentIndex));
list.set(parentIndex, temp);
//两者交换后,我们要继续判断新追加的节点是不是比刚才的父节点的父节点还要大,
// 所以将刚才父节点的索引赋值给它,继续刚才的循环
currentIndex = parentIndex;
} else {
break;
}
}
}
/**
* 每次移除大根堆的堆顶元素,然后调整,变成一个元素个数减一的大根堆
* @return 返回的大根堆堆顶元素
*/
private int remove() {
int removedNum = list.get(0); //先保存堆顶元素
//将堆尾元素赋值给堆顶,同时删除堆尾
list.set(0, list.get(list.size() - 1));
list.remove(list.size() - 1);
//要开始调整堆了,首先从新堆顶开始遍历
int currentIndex = 0;
while (currentIndex < list.size() - 1) {
int leftIndex = currentIndex * 2 + 1;
int rightIndex = currentIndex * 2 + 2; //先找到当前节点的左右孩子
if (!(leftIndex < list.size())) { //如果不存在左孩子,说明当前节点已经最大,不需要调整大根堆,直接退出循环
break;
}
int maxIndex = leftIndex; //如果存在左孩子,先假设它是最大的节点
//如果右孩子也存在的话,那么就要让它跟左孩子比较一下谁最大了
if (rightIndex < list.size()) {
if ((list.get(maxIndex).compareTo(list.get(rightIndex))) < 0) {
maxIndex = rightIndex;
}
}
//用刚才得到的,左右孩子中的最大节点,与当前节点进行比较
//如果当前节点比最大节点还要大的话,说明当前节点已经最大,不需要调整大根堆,直接退出循环
//否则,交换
if ((list.get(currentIndex).compareTo(list.get(maxIndex))) > 0) {
break;
} else {
int temp = list.get(currentIndex);
list.set(currentIndex, list.get(maxIndex));
list.set(maxIndex, temp);
currentIndex = maxIndex;
}
}
return removedNum; //返回之前保存的堆顶元素
}
}
因为我们的算法是堆排序,所以上面的代码是一个实现堆(Heap)的内部类,其中 add 方法用来建堆,就如同动画里面演示的。delete 方法用于删除堆顶和调整堆。
下面是堆排序的调用方法
public void heapSort(int[] list) {
//根据数组构建一个大根堆
Heap heap = new Heap(list);
//每次移除堆顶的最大元素,赋给数组(因为我们最后要的数组是从小到大排列的,所以从后遍历)。
for (int i = list.length - 1; i >= 0; i--) {
list[i] = heap.remove();
}
}
堆排序到此结束。
7. 希尔排序O(n * logn)
希尔排序是一种特殊的插入排序,想象一下之前的插入排序:将每个元素前面的序列都看成有序序列,然后对该有序序列从后往前遍历,如果相邻元素大于当前元素,就与当前元素交换。
在遍历的时候我们每次都是与当前元素相邻的元素做比较,即步长为 1 。
所以,如果序列中最小的元素恰巧放在序列末尾的时候,光移动这一个元素就要比较 n - 1 次,这对于大型的序列来说是非常耗时的!
希尔排序是怎么做的呢?
它与插入排序的区别就是希尔排序的步长(step)是改变的,首先选取为 数组长度的 1/2 ,之后每次减小一半,当最后步长(step)变成 1 的时候,就变成了我们经典的插入排序。
别看这么一小点改变,就靠这一点,希尔排序就突破了平方级别的运行时间。它的代码量小,而且不占用额外的空间,所以在中等级别的数组排序中非常推荐用希尔排序!你可能想还会有更高效的排序算法,没错,但是它们也只会比希尔排序快两倍(可能还达不到),而且更复杂。所以,学好希尔排序吧!
来看一张原理图
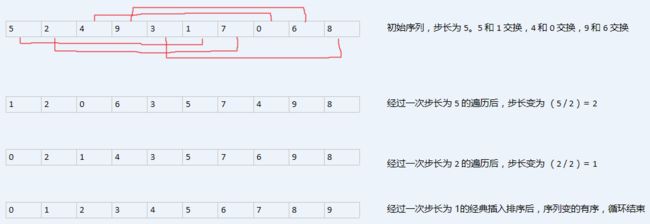
把排序过程在脑海里走一遍,然后看代码
public int[] shellSort(int[] A) {
int step = A.length / 2;
while (step > 0) {
for (int i = step; i < A.length; i++) {
for (int j = i; j >= step && (A[j] < A[j - step]); j -= step) {
int temp = A[j];
A[j] = A[j - step];
A[j - step] = temp;
}
}
step /= 2;
}
return A;
}
比快排和堆排序简单多了吧!首先定义步长为 数组长度的一半,其实就是在插入排序的两层 for 循环外面加一层判断步长(step)的 while 循环。
首先进行 step = A.length / 2 的插入排序。i 代表着我们要比较的元素,因为是间隔 step 的插入排序,所以 i 从 step 开始,然后每次都和它前面相隔 step 的元素进行比较,如果小于前面相隔 step 的元素,就交换,然后继续和新的与它相隔 step 的元素进行比较,直到小于或者前面没有与它相隔 step 的元素,结束循环。然后步长缩小一半,循环上述过程。
其实希尔排序的关键就是步长的选择,我们选的步长初始值是数组长度的一半,然后每次缩小二分之一。那么最优的步长初始值与递减规律该怎么选择呢????
我也不知道。
8. 基数排序
有点累了,不想写了,我找了一篇别人写的很不错的基数排序博客,贴给大家
我找的基数排序博客
