译者序:原文GPU Animation: Doing It Right,发表于2016年12月6日,本文是对该篇的中文翻译,如有帮助,作为译者,也深感欣慰。
附原文链接:https://www.smashingmagazine.com/2016/12/gpu-animation-doing-it-right/
目前,大部分人都知道现代浏览器是使用GPU来渲染web的部分页面,尤其是带有动画的。举个例子,一个使用transform的css动画看起来会比使用left和top属性的更为流畅。但是如果你问,“我是如何从GPU获得平滑的动画?”多数情况下,你可能会听到比如“使用 transform: translateZ(0) 或者 will-change: transform。”的回答。
这些属性好比如我们在IE6使用zoom:1(如果你懂我的意思),用于准备GPU的动画——或者合成(compositing),浏览器供应商喜欢这么称它。
但有时,简单演示中运行的很好很流畅的动画,在真实网站却很慢,引起视觉错误甚至导致浏览器崩溃。为什么会产生这种现象?我们如何修复它?接下来一起试着理解吧。
免责声明
在我们深入GPU的合成前,我想告诉你一件重要的事:这是一个巨大的hack。你不会在W3C的规范里(至少目前来说)找到任何关于合成(compositing )如何工作的资料,如何显式地在合成层上放置元素,甚至于合成本身。它只是浏览器用于执行确定任务的优化,并且每个浏览器供应商以自己的方式实现。
你在这篇文章学到的一切,不是官方说明文档,而是我个人实验的结果,夹杂着一点常识和不同浏览器子系统运行原理的知识。部分可能绝对是错的,部分可能随着时间而变化——这个要事先说明!
合成(Compositing )的工作原理
为了准备GPU动画的页面,我们需要理解浏览器的工作原理,而不仅仅是听取来自网上或本文的随意建议。
比如说一个页面有 A 和 B的元素,均为绝对定位position: absolute,带着不同的 z-index。浏览器将会从CPU绘制,然后把生成的图像发送给GPU——于屏幕上显示结果。
A
B
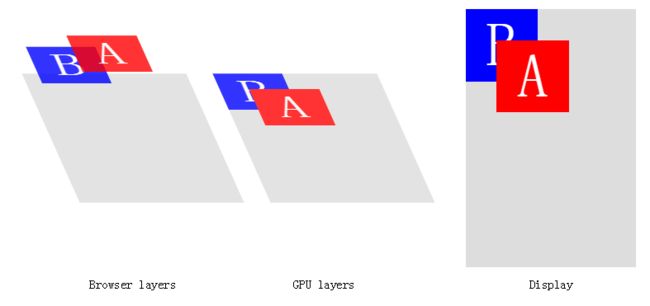
现在用left属性和css的animation,来移动A元素:
A
B
在这种情况下,对于每个动画帧,浏览器都会重新计算元素的几何形状(即回流reflow),渲染页面新状态的图像 (即重绘repaint),然后再次将其发给GPU以显示在屏幕。我们知道重绘是很耗性能成本的,每个现代浏览器都足够快速的来重绘页面改变的部分,而不是整个页面。浏览器在多数情况下能都很快地重绘,但我们的动画依旧不平滑。
在动画的每一步(甚至递增)进行回流和重绘整个页面,听起来真的很慢,特别是对于一个庞大复杂的布局。而绘制两个独立的图像会更有效——一个是A元素,一个是没有A元素的整个页面——然后简单的相对彼此偏移那些图像。换句话来说,合成(composing)缓存的元素图像会更快。这也是GPU闪光的地方:它能快速合成带有亚像素精度的图像,为动画添加“性感“的平滑度。
为了优化合成,浏览器得确保css的动画属性:
- 不影响文档流,
- 不依赖于文档流,
- 不会造成重绘。
有人会认为带有position: absolute以及fixed的top和left属性,不依赖于其环境,但事实并非如此。比如说,值为百分比的left属性,会取决于.offsetParent的大小;同样,em, vh以及其他单位也会取决于自身环境。而transform和opacity是css唯一会满足上述情况的属性。
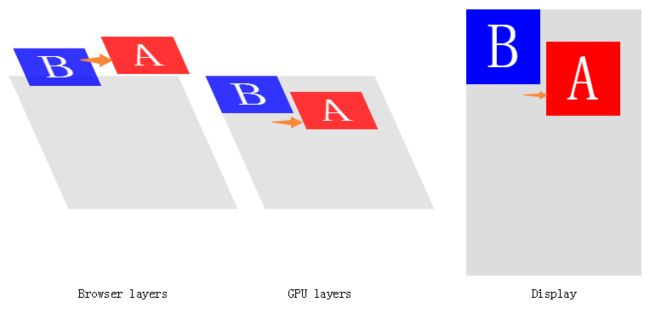
下面用transform代替left来动画:
A
B
这里,我们声明式地描述了动画:它的开始位置,结束位置,持续时间等。它将提前告诉浏览器css的更新属性。因为浏览器如果知道没有任何属性会导致回流或重绘,它可以应用合成优化:绘制合成层(compositing layers)的图像并发给GPU。
这种优化的优点在哪?
- 得到一个带有亚像素精密度的柔顺平滑动画,运行在特别为图形任务的优化的单元上,并且非常快。
- 动画不再绑定到CPU。即使运行一个强化的JavaScript任务,动画依然会快速执行。
一切看起来如此的清楚和简单,对吧,那会遇到什么问题呢?一起来看看这种优化方式是如何工作的。
它可能会让你震惊,GPU竟是一个独立的计算机。是的,每个现代设备的重要部分通常都是独立单元,有自己的处理器,自己的内存和数据处理模块。就像其他任何应用程序或者游戏一样,浏览器需要用外部设备跟GPU通信。
为了更好的理解它是怎么工作的,想想AJAX吧。假使你要提交用户输入的数据,你不会告诉远程服务器,“嗨,过来获取这些输入框的数据和JS变量,并保存到数据库。”远程服务器不能访问用户浏览器的内存。取而代之的是,你需要从页面保存这些数据到可以轻松解析的简单数据格式(如JSON)的有效内容中,并发送给远程服务器。
合成也是如此。GPU就像远程服务器,浏览器需要首先创建一个有效载荷,然后发送到设备。当然,GPU没有距离CPU数千米长;它就在旁边。然而,鉴于多数情况,远程服务器请求和返回允许2秒,对于GPU的数据转换的额外3~5毫秒会导致糟糕的动画。
什么是GPU的有效载荷?多数情况下,它包含了层图像,以及附加的说明比如大小,偏移量,以及动画参数。下面大致的写了有效负载及GPU传输的数据:
- 绘制每个合成层成独立图像。
- 准备层数据(例如大小,偏移量,透明度)
- 准备动画的着色(如果用到的话)
- 发送GPU数据
如你所见,每当为元素添加transform: translateZ(0)或者will-change: transform,你会开始同样的过程。而重绘是很耗性能成本的,这里它会更慢。多数情况下,浏览器不能进行递增的重绘,它会去绘制之前覆盖了新合成层的区域。
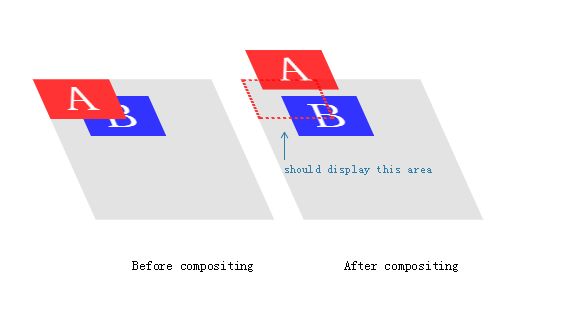
隐式合成(Implicit Compositing)
回到我们刚才A和B的例子。之前,我们动画处于所有元素上层的A,导致有两个合成层:一是A元素,另一个是B元素和整个页面背景(也就是没有A)。
现在,我们让B动画。
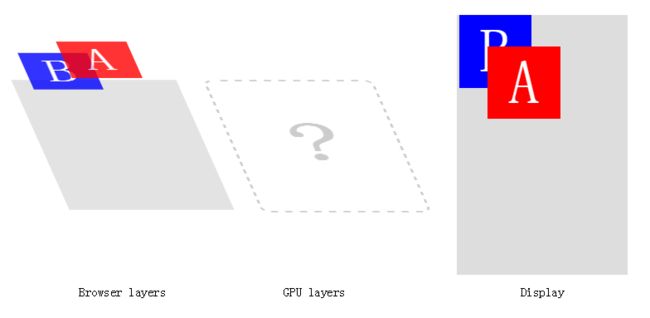
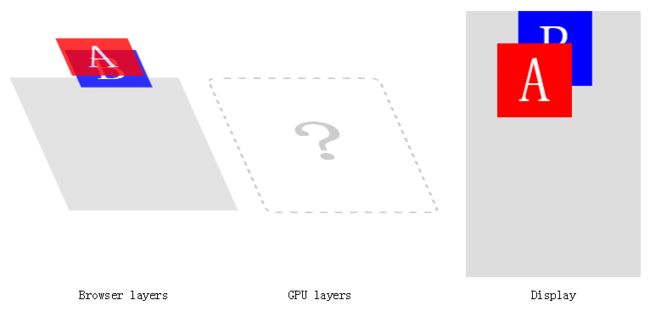
我们陷入了逻辑问题。B元素应该是一个独立的合成层,最终的层图像应该在GPU被合成。但是A元素应该出现在B的上面,我们并没有定义关于A的任何东西来推动它在自己层。
记住那个大的声明:特殊的GPU-合成(GPU-compositing)模式并不是CSS规范的一部分;它只是浏览器内部应用的优化。因为定义了z-index,A肯定是在B上方。而浏览器会做些什么呢?
它将会强制创建一个包含A的新合成层,当然,添加了另一个重绘:
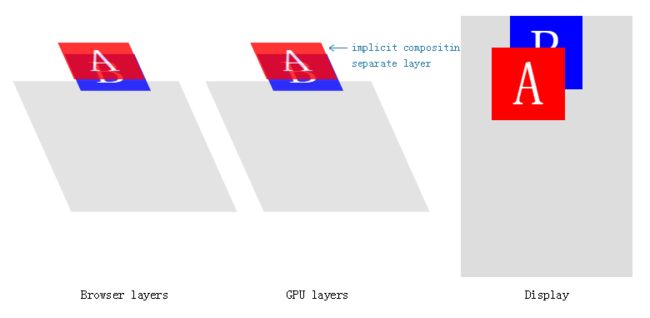
它被称为隐式合成 implicit compositing:以堆叠顺序应当出现在合成上的一个或多个非合成元素被提升为复合层 —— 即,被绘制为分离的图像,然后将其发送到GPU。
我们在隐式合成里犯的错远比你想象的还要多。浏览器提升元素为合成层是有很多原因的,下面列了几条:
- 3D变换:
translate3d,translateZ等; -
,