- 什么是注解
- 注解分类
- 注解作用分类
- 元注解
- Java内置注解
- 自定义注解
- 自定义注解实现及使用
- 编译时注解
- 注解处理器
- 注解处理器基本代码
- 注解处理器一般处理逻辑
- 注解处理器
- 如何编写基于编译时注解的项目
- 项目结构划分
- 注解模块的实现
- 注解处理器的实现
- Glide遇坑记之分析
- 收集信息
- 生成代理类
- 生成Java代码
- Glide遇坑记之分析
- API模块的实现
- ButterKnife工作流程解析
- ButterKnife 有哪些优势?
- ButterKnife工作流程
- Java注解的工作流程
- 参考资料
什么是注解
在Java语法中,使用@符号作为开头,并在@后面紧跟注解名。被运用于类,接口,方法和字段之上。
注解也叫
元数据,是一种代码级别的说明,与类,接口。枚举是在用一个层次上,他可以声明在包,类,字段,方法,局部变量,方法参数等的前面,用来对这些变量进行说明,注释。注解可以提高代码的可读性,它可以向编译器,虚拟机等解释说明一些事情。降低项目的耦合度,自动生成Java代码,自动完成一些规律性的代码,减少开发者的工作量。
注解分类
- Java内置注解
- 元注解
- 自定义注解
- 运行时注解
- 编译时注解
注解作用分类
- 编写文档
- 通过代码里标识的元数据生成文档【生成文档doc文档】
- 代码分析
- 通过代码里标识的元数据对代码进行分析【使用反射】
- 编译检查
- 通过代码里标识的元数据让编译器能够实现基本的编译检查【Override】
Java字段(类成员)和属性
属性只局限于类中方法声明,并不与类中其他的成员相关
Java中的属性通常可以理解为get和set方法;而字段通常叫做类成员
字段通常是在类中定义的类成员变量
元注解(负责注解其他的注解)
-
@Target
- 表示该注解用于什么地方,可能的ElementType参数包括:
- CONSTRUCTOR:构造器的声明
- FIELD:域声明
- LOCAL_VARIABLE:局部变量声明
- METHOD:方法声明
- PACKAGE:包声明
- PARAMETER:参数声明
- TYPE:类,接口或enum声明
- 表示该注解用于什么地方,可能的ElementType参数包括:
-
@Retention
- 表示在什么级别保留此信息,可选的RetentionPolicy参数包括:
- SOURCE:注解仅存在代码中,注解会被编译器丢弃
- CLASS:注解会在class文件中保留,但会被VM丢弃
- RUNTIME:VM运行期间也会保留该注解,因此可以通过反射来获得该注解
- 表示在什么级别保留此信息,可选的RetentionPolicy参数包括:
-
@Documented
- 将注解包含在javadoc中
-
@Inherited
- 允许子类继承父类的注解
Java内置注解
-
@Override,表示当前的方法定义将覆盖超类中的方法,如果出现错误,编译器就会报错。
- 当我们的子类覆写父类中的方法的时候,我们使用这个注解,这一定程度的提高了程序的可读性也避免了维护中的一些问题,比如说,当修改父类方法签名(方法名和参数)的时候,你有很多个子类方法签名也必须修改,否则编译器就会报错,当你的类越来越多的时候,那么这个注解确实会帮上你的忙。如果你没有使用这个注解,那么你就很难追踪到这个问题。
-
@Deprecated:如果使用此注解,编译器会出现警告信息。
- 一个弃用的元素(类,方法和字段)在java中表示不再重要,它表示了该元素将会被取代或者在将来被删除。
当我们弃用(deprecate)某些元素的时候我们使用这个注解。所以当程序使用该弃用的元素的时候编译器会弹出警告。当然我们也需要在注释中使用@deprecated标签来标示该注解元素。
- 一个弃用的元素(类,方法和字段)在java中表示不再重要,它表示了该元素将会被取代或者在将来被删除。
-
@SuppressWarnings:忽略编译器的警告信息
- 当我们想让编译器忽略一些警告信息的时候,我们使用这个注解。比如在下面这个示例中,我们的deprecatedMethod()方法被标记了@Deprecated注解,所以编译器会报警告信息,但是我们使用了@SuppressWarnings("deprecation")也就让编译器不在报这个警告信息了
自定义注解
- 运行时注解大多数时候实时运行时使用反射来实现所需效果,这很大程度上影响效率
- 编译时注解在编译时生成对应Java代码实现代码注入
自定义注解实现及使用
自定义注解使用@interface来声明一个注解。创建一个自定义注解遵循: public @interface 注解名 {方法参数}
自定义注解示例一
@Documented
@Target(ElementType.METHOD)
@Inherited @Retention(RetentionPolicy.RUNTIME)
public @interface Annotation{
int studentAge() default 18; //定义默认值
String studentName();
String stuAddress();
String stuStream() default "CSE";
}
@Annotation(studentName = "Chaitanya", stuAddress = "Agra, India")
public class Class {
...
}
自定义注解示例二
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface getViewTo {
int value() default -1;
}
public class MainActivity extends AppCompatActivity {
@getViewTo(R.id.textview)
private TextView mTv;
/**
* 解析注解,获取控件
*/
private void getAllAnnotationView() {
//获得成员变量
Field[] fields = this.getClass().getDeclaredFields();
for (Field field : fields) {
try {
//判断注解
if (field.getAnnotations() != null) {
//确定注解类型
if (field.isAnnotationPresent(GetViewTo.class)) {
//允许修改反射属性
field.setAccessible(true);
GetViewTo getViewTo = field.getAnnotation(GetViewTo.class);
//findViewById将注解的id,找到View注入成员变量中
field.set(this, findViewById(getViewTo.value()));
}
}
} catch (Exception e) {
}
}
}
}
编译时注解
说到编译时注解,就不得不说注解处理器 AbstractProcessor,如果你有注意,一般第三方注解相关的类库(基于注解的框架),如bufferKnike、ARouter,都有一个Compiler命名的Module,如下图X2.3,这里面一般都是注解处理器,用于编译时处理对应的注解。
注解处理器(Annotation Processor)是javac的一个工具,它用来在编译时扫描和处理注解(Annotation)。你可以对自定义注解注册相应的注解处理器,用于处理注解逻辑。
javac是收录于JDK中的Java语言编译器。该工具可以将后缀名为.java的源文件编译为后缀名为.class的可以运行于Java虚拟机的字节码。
注解处理器
实现一个自定义注解处理器,至少重写四个方法,并注册你的Processor(为自定义注解注册相应的注解处理器,用于处理注解逻辑)
-
@AutoService(Processor.class),谷歌提供的自动注册注解,为你生成注册Processor所需要的格式文件(com.google.auto相关包)。 -
init(ProcessingEnvironment env),初始化处理器,一般在这里获取我们需要的工具类。 -
getSupportedAnnotationTypes(),指定注解处理器是注册给哪个注解的,返回指定支持的注解类集合。 -
getSupportedSourceVersion(),指定java版本。 -
process(),处理器实际处理逻辑入口。
注解处理器基本代码
init()方法传入一个参数processingEnv,可以帮助我们去初始化一些辅助类:
- Filer mFileUtils; 跟文件相关的辅助类,生成JavaSourceCode.
- Elements mElementUtils;跟元素相关的辅助类,帮助我们去获取一些元素相关的信息。
- Messager mMessager;跟日志相关的辅助类。
注解处理器一般处理逻辑
1、遍历得到源码中,需要解析的元素列表。
2、判断元素是否可见和符合要求。
3、组织数据结构得到输出类参数。
4、输入生成Java文件。
5、错误处理。
Processor处理过程中,会扫描全部Java源码,代码的每一个部分都是一个特定类型(比如类、变量、方法)的Element,它们像是XML一层的层级机构,比如类、变量、方法等,每个Element代表一个静态的、语言级别的构件。
Element代表的是源代码,而TypeElement代表的是源代码中的类型元素,例如类。然而,TypeElement并不包含类本身的信息。你可以从TypeElement中获取类的名字,但是你获取不到类的信息,例如它的父类。这种信息需要通过TypeMirror获取。你可以通过调用elements.asType()获取元素的TypeMirror。
Element 相关子类
- VariableElement //一般代表成员变量
- ExecutableElement //一般代表类中的方法
- TypeElement //一般代表代表类
- PackageElement //一般代表Package
如何编写基于编译时注解的项目
在Android应用开发中,我们常常为了提升开发效率会选择使用一些基于注解的框架,但是由于反射造成一定运行效率的损耗,所以我们会更青睐于编译时注解的框架,例如:
- ButterKnife免去我们编写View的初始化以及事件的注入的代码。
- EventBus3方便我们实现组建间通讯。
- Fragmentargs轻松的为Fragment添加参数信息,并提供创建方法。
- ParcelableGenerator可实现自动将任意对象转换为Parcelable类型,方便对象传输。
项目结构划分
在编写此类框架的时候,一般需要建立多个module,例如:
- xxx-annotation 用于存放注解等,Java模块
- xxx-compiler 用于编写注解处理器,Java模块
- xxx-api 用于给用户提供使用的API,本例为Andriod模块
- xxx-sample 示例,本例为Andriod模块
注解处理器只需要在编译的时候使用,并不需要打包到APK中。因此为了用户考虑,我们需要将注解处理器分离为单独的module。
对于module间的依赖,因为编写注解处理器需要依赖相关注解,所以:
ioc-compiler依赖ioc-annotation>。我们在使用的过程中,会用到注解以及相关API。所以ioc-sample依赖ioc-api;ioc-api依赖ioc-annotation
注解模块的实现
注解模块,主要用于存放一些注解类。
注解处理器的实现
实现一个注解处理器,至少需要重写四个方法。该模块,我们一般会依赖注解模块,以及可以使用一个auto-service库,auto-service库可以帮我们去生成META-INF等信息。
build.gradle的依赖情况如下:
dependencies {
compile 'com.google.auto.service:auto-service:1.0-rc2'
compile project (':ioc-annotation')
}
process的实现
process()注解处理器实际处理逻辑入口。主要是获取被注解的参数列表,组织数据结构得到输出类参数,生成Java文件。process中的实现一般可以认为两个步骤:
- 收集信息
- 生成代理类(本文把编译时生成的类叫代理类)
什么叫收集信息呢?就是根据你的注解声明,拿到对应的Element,然后获取到我们所需要的信息,这个信息肯定是为了后面生成JavaFileObject所准备的。
例如本例,我们会针对每一个类生成一个代理类,例如MainActivity我们会生成一个MainActivity$$ViewInjector。那么如果多个类中声明了注解,就对应了多个类,这里就需要:
- 一个类对象,代表具体某个类的代理类生成的全部信息,本例中为ProxyInfo
- 一个集合,存放上述类对象(到时候遍历生成代理类),本例中Map
收集信息
首先调用mProxyMap.clear(),因为process可能会多次调用,避免生成重复的代理类,避免生成类的类名已存在异常。
然后,通过roundEnv.getElementsAnnotatedWith()获取被@BindView注解的元素,这里返回值,按照我们的预期应该是VariableElement集合,因为我们用于成员变量上。
接下来for循环我们的元素,首先检查类型是否是VariableElement(对元素列表进行额外判断,校验元素是否可用),然后获取元素VariableElement对应的类信息TypeElement,继而生成ProxyInfo对象。这里先通过一个mProxyMap进行检查,key为qualifiedName即类的全路径,如果没有生成才会去生成一个新的ProxyInfo实例,ProxyInfo与类是一一对应的。
接下来,会将与该类对应的且被@BindView声明的VariableElement加入到ProxyInfo中去,key为我们声明时填写的id,即View的id。
这样就完成了信息的收集,收集完成信息后,应该就可以去生成代理类了。
生成代理类
遍历mProxyMap,然后取得每一个ProxyInfo,最后通过mFileUtils.createSourceFile()来创建文件对象,类名为proxyInfo.getProxyClassFullName(),写入的内容为proxyInfo.generateJavaCode()(生成Java代码)。
生成Java代码
ProxyInfo.generateJavaCode()方法通过收集得到的信息,拼接完成的代理类对象。也可以使用开源库,例如:javapoet,来通过Java API的方式来生成代码。javapoet (com.squareup:javapoet)是一个根据指定参数,生成java文件的开源库。
生成的代码实现了一个接口ViewInjector,该接口是为了统一所有的代理类对象的类型,到时候我们需要强转代理类对象为该接口类型,调用其方法。接口是泛型,主要就是传入实际类对象,例如:MainActivity,因为我们在生成代理类中的代码,实际上就是实际类.成员变量的方式进行访问,所以,使用编译时注解的成员变量一般都不允许private修饰符修饰(有的允许,但是需要提供getter,setter访问方法)。
API模块的实现
有了代理类之后,我们一般还会提供API供用户去访问
API一般如何编写呢?
- 根据传入的
host寻找我们生成的代理类:例如:MainActivity->MainActity$$ViewInjector。 - 强转为统一的接口,调用接口提供的方法。
这两件事应该不复杂,第一件事是拼接代理类名,然后反射生成对象,第二件事强转调用。拼接代理类的全路径,然后通过newInstance生成实例,然后强转,调用代理类的inject()方法。
ButterKnife工作流程解析
Butter Knife,专门为Android View设计的绑定注解,专业解决各种findViewById。
ButterKnife有哪些优势?
- 强大的View绑定和Click事件处理功能,简化代码,提升开发效率
- 方便的处理Adapter里的ViewHolder绑定问题
- 运行时不会影响APP效率,使用配置方便
- 代码清晰,可读性强
ButterKnife工作流程
- 开始它会扫描Java代码中所有的ButterKnife注解@Bind、@OnClick、@OnItemClicked等。
- 当它发现一个类中含有任何一个注解时, ButterKnifeProcessor会帮你生成一个Java类,名字<类名>$$ViewInjector.java,这个新生成的类实现了ViewBinder接口。
- 这个ViewBinder类中包含了所有对应的代码,比如@Bind注解对应findViewById(), @OnClick对应了view.setOnClickListener()等等。
- 最后当Activity启动ButterKnife.bind(this)执行时,ButterKnife会去加载对应的ViewBinder类调用它们的bind()方法。
Java注解工作流程
- 注解是在编译(Compile)时期进行处理的
- 注解处理器(Annotation Processor)读取Java代码处理相应的注解,并且生成对应的代码
- 生成的Java代码被当做普通的Java类再次编译
-
注解处理器不能修改存在Java输入文件,也不能对方法做修改或者添加
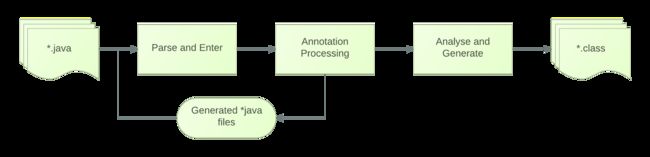 Java编译流程.png
Java编译流程.png
参考资料
Android注解快速入门和实用解析
Android 如何编写基于编译时注解的项目
自定义Java注解处理器
ButterKnife框架原理